【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
shuaishuaicdp/MixSet
收藏Hugging Face2024-04-13 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/shuaishuaicdp/MixSet
下载链接
链接失效反馈官方服务:
资源简介:
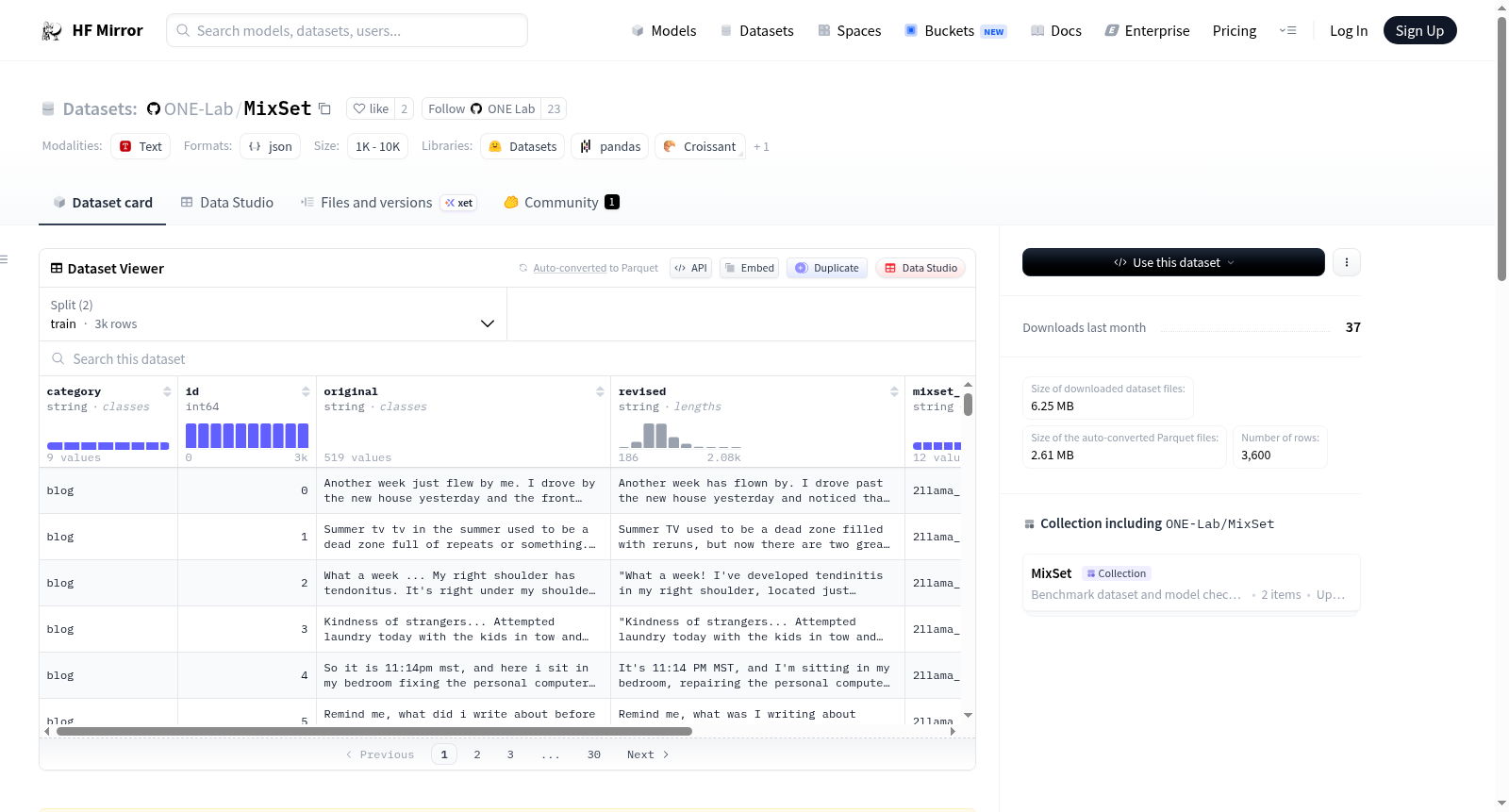
Mixset数据集包含12个JSON文件,总计3600条MixText数据。数据集分为训练集和测试集,分别包含3000条和600条数据。每条数据包括原始文本、修订文本、类别、ID等信息,适用于二元分类和多类分类任务。数据集的结构和格式详细描述了数据的来源和处理方式。
Mixset数据集包含12个JSON文件,总计3600条MixText数据。数据集分为训练集和测试集,分别包含3000条和600条数据。每条数据包括原始文本、修订文本、类别、ID等信息,适用于二元分类和多类分类任务。数据集的结构和格式详细描述了数据的来源和处理方式。
提供机构:
shuaishuaicdp
原始信息汇总
数据集概述
- 名称: Mixset 数据集
- 文件格式: JSON
- 文件数量: 12
- 数据点总数: 3,600 条 MixText 数据
数据集结构
- JSON 文件总数: 2
- 数据点总数: 3,600 条 MixText 数据
训练测试分割
- 训练集: 前 250 条数据,文件名为
./MixSet_train.json - 测试集: 剩余 50 条数据,文件名为
./MixSet_test.json - 完整数据集使用: 训练集包含 3,000 条数据,测试集包含 600 条数据
数据格式
- 字段:
category: 原始 HWT 和 MGT 数据集的类别id: 新构建数据集中的唯一 IDoriginal: 修订前的原始句子revised: 由人类或 LLM 修订的句子mixset_category: 在论文中定义的 LLM/Human + 操作类别binary: 二元分类设置中修订句子的类别
数据集用途
- 评估 MGT 检测器: 可直接使用训练/测试集进行二元分类设置的评估
- MixText 设置: 考虑 AI-修订的 HWT 和人类修订的 MGT 作为第三类
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,混合文本数据集的构建对于检测机器生成文本至关重要。MixSet数据集通过整合12个JSON文件,共包含3,600条混合文本数据,其构建过程基于对现有人类撰写文本和机器生成文本的改写操作。具体而言,数据集从预存的HWT和MGT数据集中采样原始句子,随后通过人工或大型语言模型进行修订,形成修订后的文本。每个数据点均标注了类别、唯一ID、原始文本、修订文本、混合类别及二元分类标签,确保了数据结构的系统性和可追溯性。
使用方法
MixSet数据集的使用方法灵活多样,主要面向机器生成文本检测器的评估。用户可直接利用提供的训练集和测试集进行二元分类任务,其中训练集包含3,000条数据,测试集包含600条数据。此外,数据集还支持混合文本设置,将AI修订的人类撰写文本和人类修订的机器生成文本作为第三类别,以应对更复杂的检测场景。数据以JSON格式组织,便于文件读写操作,用户可根据研究需求选择整体数据集或分离文件进行实验,确保评估过程的效率和准确性。
背景与挑战
背景概述
MixSet数据集由shuaishuaicdp团队构建,专注于文本改写检测领域,旨在应对人工智能生成文本与人类创作文本的边界日益模糊的挑战。该数据集包含3,600条MixText数据,涵盖12个JSON文件,其核心研究问题在于通过混合人类与大型语言模型(LLM)的改写文本,构建一个多源、多类别的文本检测基准。数据集的创建时间与具体研究机构信息虽未在README中明确,但其设计紧密关联自然语言处理领域的前沿议题,特别是文本真实性鉴别与生成模型评估,为相关研究提供了重要的数据支撑。
当前挑战
MixSet数据集所解决的领域问题是文本改写检测,其挑战在于区分人类修订文本与AI修订文本的细微差异,尤其是在语义保持与风格转换的复杂场景下。构建过程中的挑战包括数据源的多类别整合,如原始文本来自不同领域(如演讲类),以及修订操作(如LLM润色与人工改写)的标准化标注。此外,数据划分需平衡训练集与测试集的比例,确保模型评估的公正性,同时避免因标注误解(如论文中表格数据与实际数据集结构的差异)导致的应用偏差。
常用场景
经典使用场景
在自然语言处理领域,MixSet数据集为机器生成文本检测研究提供了关键资源。该数据集通过整合人类撰写文本与机器生成文本的修订版本,构建了一个包含3600条混合文本数据的集合,特别适用于训练和评估二元分类模型。研究者可利用其清晰的训练集与测试集划分,直接应用于检测算法性能的基准测试,同时支持将AI修订的人类文本与人类修订的机器文本作为第三类进行多类别分析,从而深化对文本来源混合场景的理解。
解决学术问题
MixSet数据集主要针对机器生成文本检测中的学术挑战,解决了传统数据集在混合修订场景下覆盖不足的问题。它通过系统化整合多种修订操作(如LLM润色或人工改写),帮助研究者探究文本修订对检测模型的影响,从而推动检测算法在复杂真实环境中的鲁棒性提升。该数据集的意义在于为文本真实性验证提供了更细粒度的实验基础,促进了自然语言处理领域在AI生成内容识别方面的理论进展与方法创新。
实际应用
在实际应用中,MixSet数据集可服务于内容审核、学术诚信维护及网络安全监测等多个领域。例如,教育机构可利用该数据集训练系统以识别学生作业中经AI修订的文本,确保评估的公正性;新闻平台或社交媒体则可借助其检测混合来源的虚假信息,提升内容可信度。通过提供人类与机器修订的对比样本,该数据集为实际场景中的文本溯源工具开发提供了可靠的数据支持。
数据集最近研究
最新研究方向
在文本生成与检测领域,MixSet数据集以其独特的混合文本结构,为机器生成文本(MGT)与人类写作文本(HWT)的边界研究提供了新的视角。该数据集融合了人工修订与大型语言模型修订的文本样本,推动了多类别分类框架的发展,特别是在AI修订文本与人类修订文本的第三类别识别上展现出前沿探索价值。当前研究热点聚焦于利用此类混合数据提升检测模型的泛化能力与鲁棒性,以应对日益复杂的文本生成场景,其影响延伸至学术诚信维护、内容安全评估等实际应用领域,为自然语言处理技术的可信发展奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


