reddit_ds_461985
收藏Hugging Face2025-04-04 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/zkpbeats/reddit_ds_461985
下载链接
链接失效反馈官方服务:
资源简介:
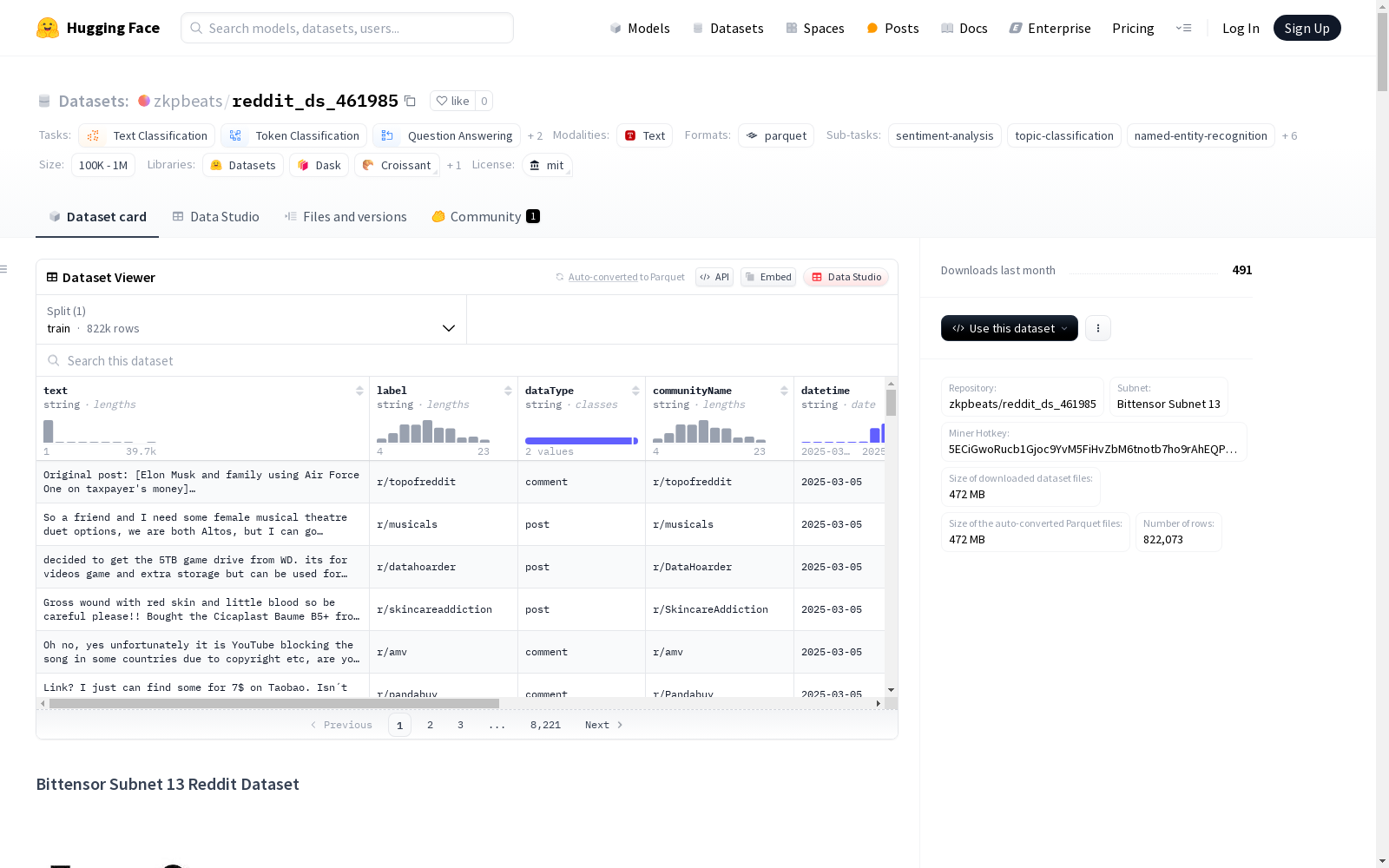
Bittensor Subnet 13 Reddit数据集是Bittensor去中心化网络的一部分,包含持续更新的预处理Reddit数据,适用于多种分析和机器学习任务,如情感分析、主题建模、社区分析和内容分类。数据集主要由英语组成,但也可能包含多语言内容。每个数据实例代表一个Reddit帖子或评论,包含文本内容、标签、数据类型、社区名称、时间戳、编码后的用户名和URL等字段。
The Bittensor Subnet 13 Reddit Dataset is part of the Bittensor decentralized network, and contains continuously updated preprocessed Reddit data. This dataset supports a variety of machine learning tasks including sentiment analysis, topic modeling, and more, while providing real-time streaming Reddit content. The dataset is primarily in English, but may also include content in other languages.
创建时间:
2025-04-03
搜集汇总
数据集介绍
构建方式
该数据集依托Bittensor Subnet 13去中心化网络构建,通过分布式矿工实时采集Reddit公开帖文与评论数据,严格遵循平台服务条款及API使用规范。采用隐私保护技术对用户名及URL进行编码处理,确保数据来源合法性的同时维护用户匿名性。数据采集过程采用动态更新机制,形成覆盖多主题、多时间维度的流式语料库。
特点
数据集呈现显著的社会媒体动态特征,包含229万余条结构化数据实例,涵盖帖子(1.97%)与评论(33.84%)两种类型。数据字段设计兼顾内容分析与隐私保护,包含文本内容、情感标签、社区归属等七类元数据。其突出优势在于实时更新的时间跨度(2025年3月至4月)和广泛的主题覆盖,前十大子版块如r/Advice、r/wallstreetbets等占比达21.92%,为研究网络社区行为提供丰富素材。
使用方法
研究者可通过HuggingFace平台直接加载数据集,建议依据时间戳自定义训练验证集划分。该数据支持文本分类、情感分析等多元任务,使用前需注意处理社交平台固有的噪声与偏差。典型应用场景包括:基于社区名称字段的垂直领域分析、利用时间戳研究舆论演化规律,或结合编码后的用户标识进行去隐私化行为建模。使用时需遵守MIT许可协议并引用指定文献。
背景与挑战
背景概述
reddit_ds_461985数据集是Bittensor Subnet 13去中心化网络的重要组成部分,由zkpbeats团队于2025年构建并持续更新。该数据集通过实时采集Reddit平台的公开帖文与评论,为自然语言处理领域提供了丰富的社交媒体文本资源。其核心研究价值在于捕捉网络社区动态,支持情感分析、主题建模等多类任务,填补了去中心化数据生态系统中高质量社交语料的空白。数据采集严格遵循Reddit平台条款,采用编码技术保护用户隐私,体现了分布式科研协作的前沿趋势。
当前挑战
该数据集面临双重挑战:在应用层面,社交媒体的非正式表达特性导致文本存在大量噪声、拼写错误及网络俚语,为情感分类等任务带来语义解析困难;平台固有的用户群体偏差可能影响模型泛化能力。在构建层面,去中心化采集机制导致数据质量波动,需设计鲁棒的预处理流程;实时更新特性要求动态验证机制以应对潜在的对抗性样本,且多语言混排现象增加了语言识别的复杂度。此外,如何平衡隐私保护与数据可用性仍是持续优化的关键问题。
常用场景
经典使用场景
在社交媒体分析领域,reddit_ds_461985数据集为研究者提供了丰富的Reddit平台文本数据,涵盖帖子与评论的多元内容。该数据集最经典的使用场景包括情感分析和主题建模,通过自然语言处理技术揭示用户观点倾向与社区讨论热点。其实时更新的特性使得追踪网络舆论动态演变成为可能,尤其适合研究突发事件中的公众情绪波动与话题传播规律。
实际应用
商业智能领域可利用该数据集进行品牌舆情监测,通过分析特定子版块中的用户讨论,识别产品改进方向与潜在市场风险。金融科技公司可结合r/wallstreetbets等投资社区内容,开发基于社交媒体的市场情绪指标。教育机构则能通过JEENEETards等学习论坛的文本挖掘,优化在线学习社区的内容推荐策略。
衍生相关工作
基于该数据集的经典研究包括跨社区语义迁移学习框架的开发,以及社交机器人检测模型的优化。在Bittensor去中心化网络生态中,衍生出多个专注于话题传播预测的子网项目。部分工作将本数据集与视觉模态结合,创建了多模态社交内容理解基准,推动了Reddit平台内容审核系统的迭代升级。
以上内容由遇见数据集搜集并总结生成


