shyuni/educational_illustraion_detection
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/shyuni/educational_illustraion_detection
下载链接
链接失效反馈官方服务:
资源简介:
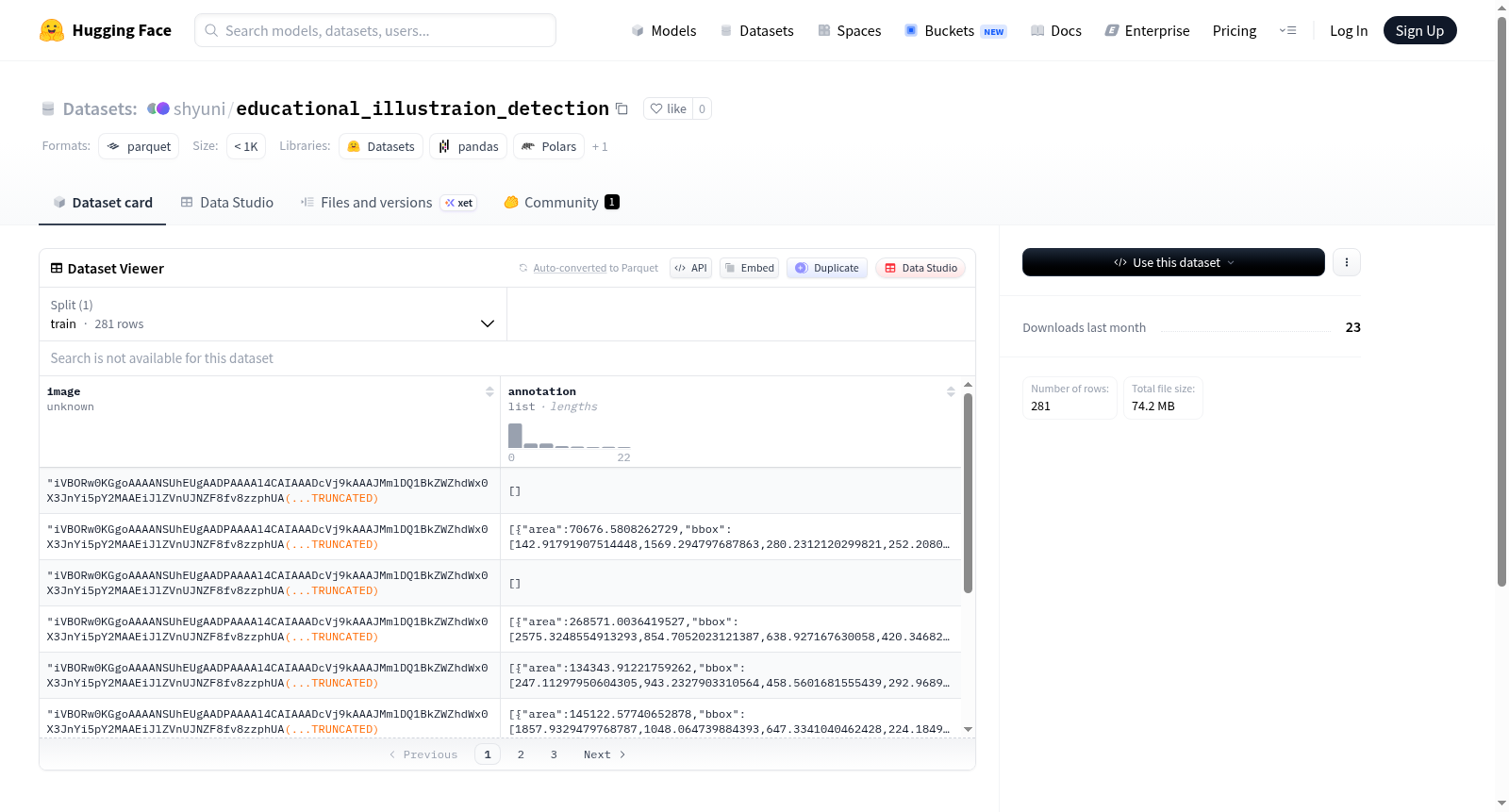
该数据集包含二进制编码的图像数据及其标注信息,标注包括面积、边界框(bbox)、类别ID、ID、忽略标志、图像ID、拥挤标志和分割细节。数据集包含一个train分割,共有281个样本,总大小为74,784,905字节。使用许可信息表明该数据集仅限个人非商业用途,所有权利归各自作者所有。
The dataset contains binary-encoded image data along with annotations including area, bounding box (bbox), category ID, ID, ignore flag, image ID, crowd flag, and segmentation details. It includes a train split with 281 examples and a total size of 74,784,905 bytes. The licensing information specifies that the dataset is for personal, non-commercial use only, with all rights belonging to the respective authors.
提供机构:
shyuni
搜集汇总
数据集介绍
构建方式
该数据集专注于教育场景下的插图目标检测任务,其构建过程以严谨的标注流程为核心。图像数据以二进制编码形式存储,每幅图像均附有包含边界框(bbox)、类别标识(category_id)、区域面积(area)及分割掩码(segmentation)等字段的详细注释。训练集包含281个样本,通过精心设计的标注体系,各目标实例被赋予唯一ID,并标注了忽略标记(ignore)与人群密集标记(iscrowd),以提升模型在复杂教育场景中的鲁棒性。数据集仅面向非商业个人用途开放,确保了版权合规性。
使用方法
数据集以HuggingFace标准格式封装,支持在训练流程中通过`load_dataset`接口便捷加载。用户需指定配置名`default`,数据集自动划分为单一训练集,包含281个样本。使用时,图像以二进制格式读取,结合注释中的边界框、类别等字段,可直接适配PyTorch或TensorFlow等主流框架的目标检测模型。建议将数据合并至自定义数据加载器,利用忽略标记调整损失函数,并依据非商业许可限制仅用于研究目的。通过设置`is_ocr`等参数过滤特殊目标,可进一步优化模型在教育插图中的检测精度。
背景与挑战
背景概述
在数字教育资源日益丰富的今天,如何自动识别与分类教育插画成为计算机视觉领域的重要课题。该数据集由研究机构于近期构建,专注于教育插画检测任务,通过提供281幅精心标注的训练图像,旨在推动目标检测技术在插画内容上的应用。数据集以COCO格式标准进行标注,包含边界框、类别及区域等关键属性,为教育场景下的视觉理解提供了基础资源。其非商业许可性质鼓励学术研究,有望促进教育智能化领域的相关探索。
当前挑战
该数据集面临的主要挑战包括:首先,教育插画风格多样,从简约线条到复杂彩绘差异显著,导致目标检测模型需具备高泛化能力;其次,数据集规模较小(仅281个样本),易引发过拟合问题,限制了模型在真实场景中的鲁棒性;最后,构建过程中,人工标注插画中微小或重叠目标时精度难以保证,且俄语描述与二进制图像编码增加了数据预处理与跨语言理解的复杂度,对算法适应性提出更高要求。
常用场景
经典使用场景
在计算机视觉与教育技术的交叉领域中,educational_illustraion_detection数据集主要服务于教材与教学插图的智能识别任务。该数据集包含281张精心标注的训练图像,每张图像都配备了详细的边界框、区域面积、类别标签等元信息,为教学插图中的目标检测与分割提供了标准化的训练与评估平台。研究者可以借此训练模型自动识别课本、课件或教育软件中的插图元素,从而推动智能教育工具的发展。
解决学术问题
该数据集有效回应了教育场景下视觉内容理解的两大核心挑战:其一,教学插图往往风格多样,包含手绘、卡通、图表等多种形式,传统自然图像数据集难以覆盖,此数据集填补了这一领域空白;其二,通过引入ignore与iscrowd等标注字段,解决了遮挡与密集目标检测中的评判难题。其发布推动了教学资源数字化与自动化标注技术的进步,为构建自适应学习系统提供了关键数据支撑。
实际应用
在实际应用中,educational_illustraion_detection数据集可赋能多种教育科技产品。例如,在智能教辅系统中,可自动识别并标注教材中的插图类型,辅助学生理解抽象概念;在在线课件制作工具中,能够快速提取插图区域并进行内容重组;在视力障碍辅助阅读设备中,配合语音输出以实现插图的语义描述。这些应用场景均依赖于该数据集训练的模型所具备的鲁棒检测能力。
数据集最近研究
最新研究方向
在当前人工智能与教育深度融合的浪潮中,教育插图检测数据集(educational_illustration_detection)的构建为多模态学习资源的结构化分析提供了关键支撑。该数据集聚焦于教材、课件等教育场景中的插图对象识别,通过精细的边界框标注与类别分类,推动了视觉理解技术在知识图谱构建、自适应学习内容生成等前沿方向的研究。其价值不仅在于优化教育资源的自动索引与元数据管理,更在于促进智能辅导系统对图文关联的深层语义解析,从而助力个性化学习路径的精准规划。随着教育数字化转型的加速,此类数据集为解决非结构化教学素材的高效检索与质量评估问题奠定了数据基础,对提升教育人工智能的实用性与公平性具有深远意义。
以上内容由遇见数据集搜集并总结生成


