Medical-Dataset-Cleaned-JSONL
收藏Hugging Face2026-04-02 更新2026-04-03 收录
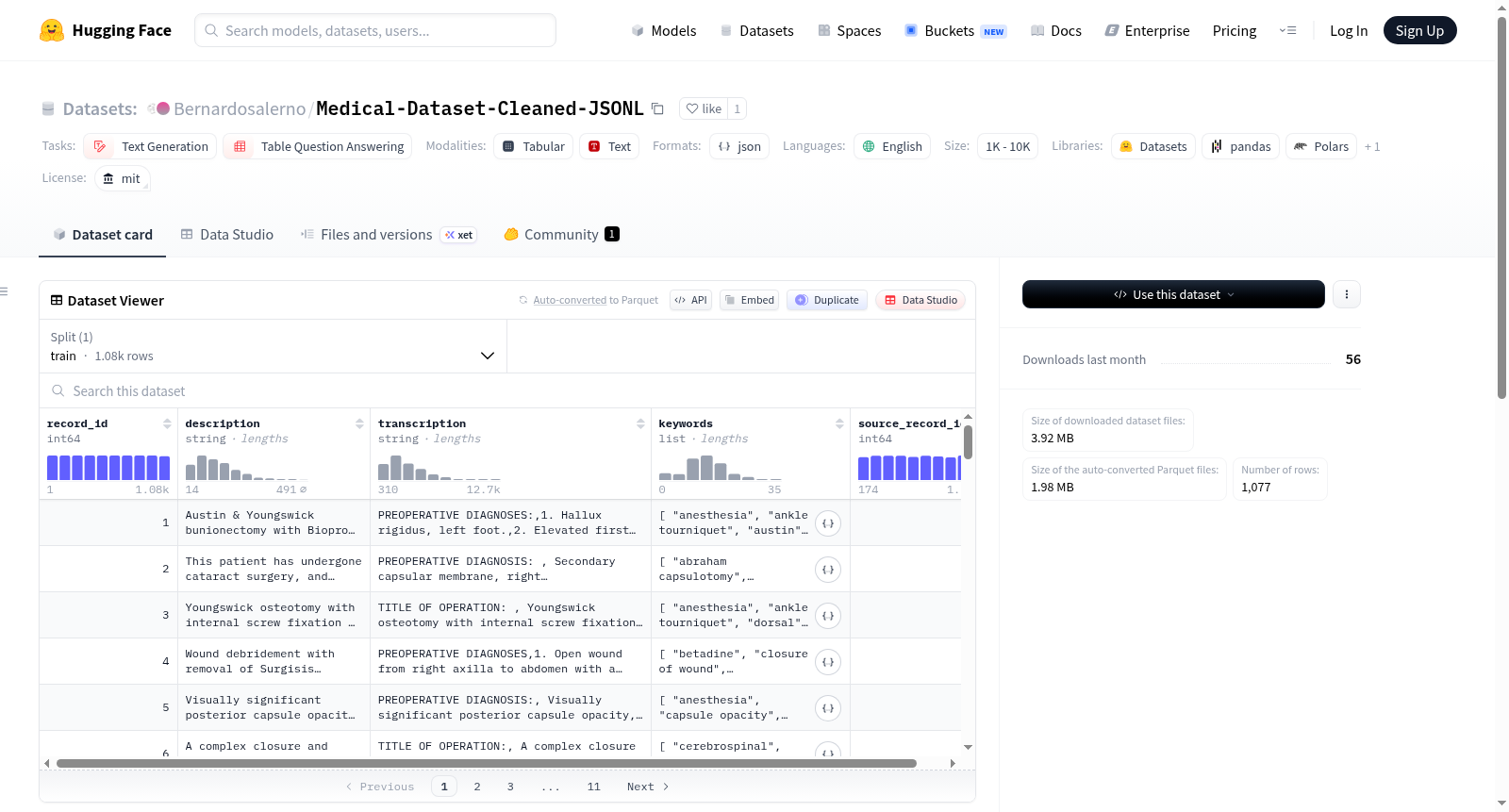
下载链接:
https://huggingface.co/datasets/Bernardosalerno/Medical-Dataset-Cleaned-JSONL
下载链接
链接失效反馈官方服务:
资源简介:
Medical Transcriptions - Cleaned JSONL Dataset 是一个经过清洗、标准化并严格格式化(JSONL格式)的医学转录文本数据集。该数据集源自原始的Medical Transcriptions数据,经过专门处理以直接适用于NLP训练任务。处理步骤包括:从原始CSV格式转换为验证过的JSONL格式;过滤不完整、噪声过多或过短的临床转录文本;应用正则表达式清理文本、处理隐藏字符并格式化字符串;通过自动化检查确保零重复和零关键空值。数据集最初来源于'tchebonenko/MedicalTranscriptions'(派生自MTSamples),适用于文本生成和表格问答等自然语言处理任务。数据集规模为1,000到10,000条样本之间,采用MIT许可协议。
The Medical Transcriptions - Cleaned JSONL Dataset is a cleaned, standardized and rigorously formatted medical transcription text dataset adhering to the JSONL format. This dataset is derived from the original Medical Transcriptions data, and has been specially processed to be directly applicable to NLP training tasks. The processing steps include: converting from the original CSV format to a validated JSONL format; filtering incomplete, overly noisy or overly short clinical transcription texts; applying regular expressions to clean text, handle hidden characters and format strings; and conducting automated checks to ensure zero duplicates and zero critical null values. The dataset was originally sourced from 'tchebonenko/MedicalTranscriptions' (derived from MTSamples), and is applicable to natural language processing tasks such as text generation and tabular question answering. The dataset contains between 1,000 and 10,000 samples, and is licensed under the MIT License.
创建时间:
2026-03-26
原始信息汇总
数据集概述
基本信息
- 数据集名称: Medical Transcriptions - Cleaned JSONL Dataset
- 托管平台: Hugging Face
- 页面地址: https://huggingface.co/datasets/Bernardosalerno/Medical-Dataset-Cleaned-JSONL
- 语言: 英语 (en)
- 许可证: MIT
- 任务类别: 文本生成 (text-generation)、表格问答 (table-question-answering)
- 数据规模: 1K<n<10K (介于1千到1万条之间)
数据集描述
该数据集是原始医学转录数据集经过清洗、标准化并严格格式化为 JSONL 格式的版本。它经过专门处理,旨在使其可直接用于自然语言处理训练任务。
数据处理要点
- 格式转换: 从原始 CSV 格式转换为经过验证的
JSONL格式。 - 数据过滤: 移除了不完整、噪声过多或过短的临床转录文本。
- 文本标准化: 应用正则表达式清洗文本,处理隐藏字符并格式化字符串。
- 数据验证: 通过自动化检查确保数据中零重复项和零关键空值。
数据来源与致谢
- 本数据集是对原始数据的处理和精炼版本。
- 原始数据由
tchebonenko/MedicalTranscriptions提供(源自 MTSamples)。
相关资源
- 代码与完整文档: 完整的 Python 源代码(Jupyter Notebook)和综合技术手册(PDF)可在 GitHub 仓库获取:https://github.com/Bernardosalerno/Data-cleaning-and-documentation-process-full-guide
搜集汇总
数据集介绍
构建方式
在临床医学文本处理领域,原始数据的规范化与结构化是确保后续分析可靠性的基石。本数据集源自公开的医学转录文本,通过系统性的数据清洗流程构建而成:原始CSV格式的临床记录首先被转换为严格验证的JSONL格式,以规避常见解析错误;随后应用正则表达式对文本进行标准化处理,清除隐藏字符并统一字符串格式;在此基础上,通过自动化筛选机制移除了不完整、噪声过高或过短的转录条目,并执行了重复项与关键空值的校验,最终形成一个无重复、无关键缺失值的洁净数据集。
特点
该数据集的核心特征体现在其高度的规范性与即用性。所有医学转录文本均经过深度清洗与归一化处理,确保了文本内容的一致性与可解析性;数据结构采用JSONL格式,明确支持嵌套信息,便于直接应用于自然语言处理任务。数据集规模适中,涵盖数千条临床记录,每条记录均经过完整性过滤,避免了低质量数据对模型训练的干扰。整体而言,该数据集以即插即用的特性,为医疗文本生成、表格问答等任务提供了高质量、低噪声的基准数据源。
使用方法
在医疗自然语言处理应用中,本数据集可直接用于模型训练与评估。用户可通过加载JSONL文件,便捷地访问每条标准化后的医学转录记录,无需额外预处理步骤。数据集适用于文本生成任务,如临床报告自动生成;也支持表格问答场景,可从结构化文本中提取关键医疗信息。建议结合提供的完整源代码与技术文档,复现或调整清洗流程,以适应特定研究需求。使用时应遵循原始数据许可,并确认其适用于目标临床或研究语境。
背景与挑战
背景概述
医学转录文本数据集在自然语言处理领域扮演着关键角色,为临床文本分析与医疗人工智能应用提供基础语料。Medical-Dataset-Cleaned-JSONL源于原始医学转录数据集,由研究人员或机构通过数据清洗与重构工作创建,旨在解决医疗文本数据中的噪声与不一致性问题。该数据集聚焦于文本生成与表格问答任务,其核心研究问题在于如何将非结构化的临床记录转化为标准化、机器可读的格式,以支持诊断辅助、病历自动化等下游应用,对推动医疗NLP技术的可靠性与实用性具有显著影响。
当前挑战
该数据集致力于应对医疗文本处理中的领域挑战,包括临床术语的多样性、缩写歧义以及隐私信息脱敏的复杂性,这些因素使得模型在理解医学语境与生成准确回答时面临困难。在构建过程中,挑战主要体现在原始数据的噪声过滤、缺失值处理以及格式统一化方面,例如需通过正则表达式清除隐藏字符、去除不完整或过短的转录文本,并确保JSONL结构的严格验证,以避免常见的数据解析错误,从而提升数据集在训练任务中的即用性与可靠性。
常用场景
经典使用场景
在医疗自然语言处理领域,Medical-Dataset-Cleaned-JSONL数据集常被用于训练和评估文本生成模型。其经过清洗和标准化的临床转录文本,为研究者提供了结构化的医疗叙述数据,支持从症状描述到诊断建议的自动生成任务。这一场景不仅促进了医疗文档的自动化处理,还提升了临床决策支持的效率,成为医疗AI应用中的基础资源。
实际应用
在实际医疗环境中,该数据集支持临床文档自动生成、电子健康记录整理以及患者咨询自动化回复等应用。医疗机构可利用其训练AI助手,快速生成标准化的医疗报告,减轻医护人员文书负担。同时,它还能集成到智能诊断系统中,辅助分析患者症状描述,提升医疗服务的响应速度与准确性,优化医疗资源分配。
衍生相关工作
基于该数据集衍生的经典工作包括医疗文本分类模型、临床问答系统以及多模态医疗AI框架。例如,研究者利用其构建了针对特定疾病(如心血管或呼吸系统疾病)的自动转录分析工具,并开发了结合结构化表格的问答模型。这些工作不仅扩展了数据集的适用范围,还推动了医疗自然语言处理技术的创新与标准化进程。
以上内容由遇见数据集搜集并总结生成


