askubuntu
收藏Hugging Face2026-01-29 更新2026-01-30 收录
下载链接:
https://huggingface.co/datasets/sentence-transformers/askubuntu
下载链接
链接失效反馈官方服务:
资源简介:
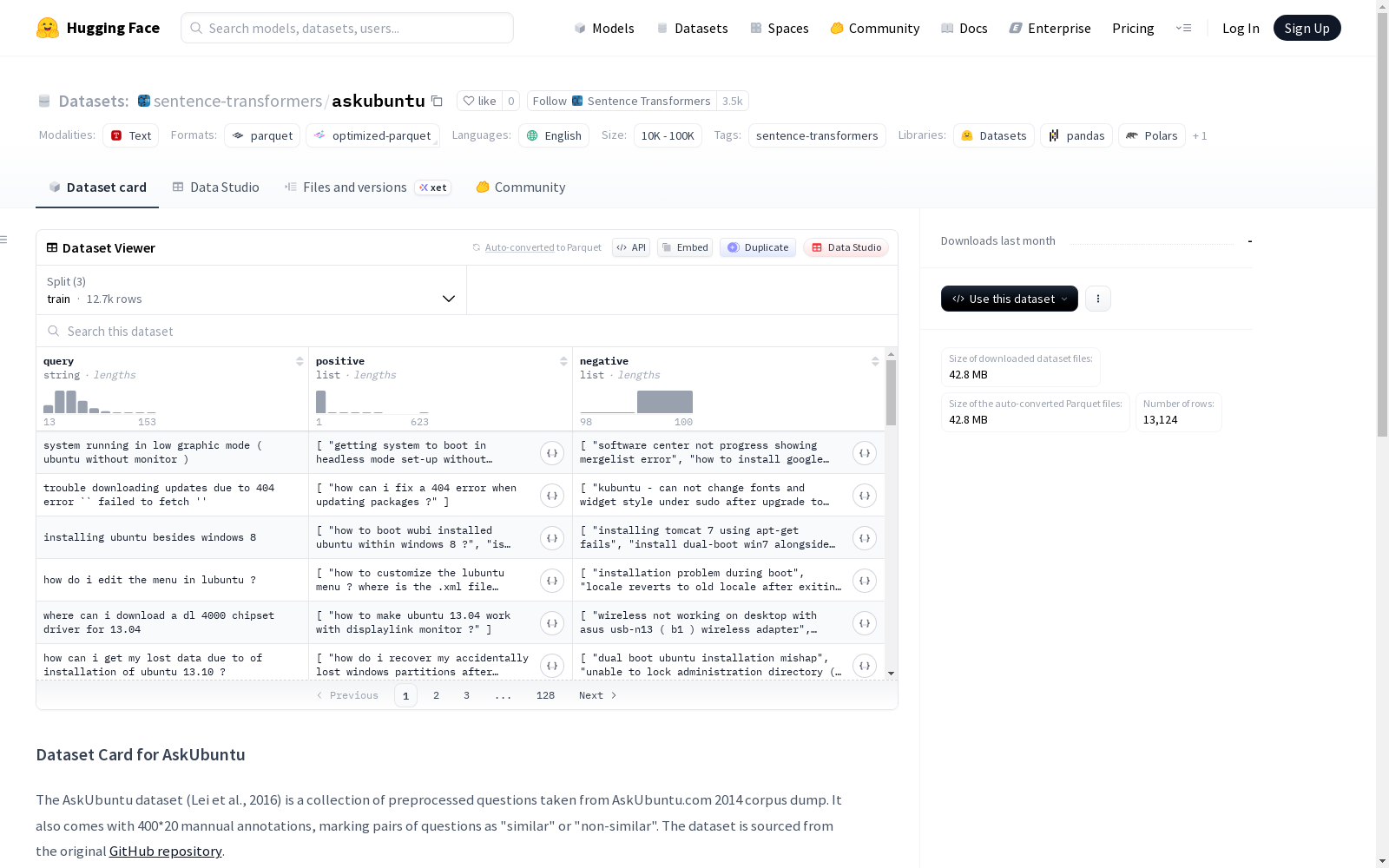
AskUbuntu数据集(Lei等人,2016)是一个从AskUbuntu.com 2014年语料库转储中提取并经过预处理的问题集合。该数据集包含400*20的手动标注,标注问题对为“相似”或“不相似”。数据集来源于原始的GitHub仓库。数据集包含三个分割:训练集(train)、开发集(dev)和测试集(test),分别包含12724、200和200个样本。每个样本包含三个字段:"query"(字符串类型,表示查询问题)、"positive"(字符串列表,表示与查询问题相似的问题列表)和"negative"(字符串列表,表示与查询问题不相似的问题列表)。对于训练集,"positive"列表是根据AskUbuntu自动判断的相似问题,而"negative"列表是随机选择的问题;对于开发集和测试集,"positive"列表是人工标注的,可能为空。数据集未进行去重处理,适用于句子相似性、信息检索等自然语言处理任务。
The AskUbuntu dataset (Lei et al., 2016) is a collection of questions extracted and preprocessed from the 2014 corpus dump of AskUbuntu.com. It contains 400×20 manually annotated question pairs labeled as "similar" or "dissimilar". The dataset is sourced from its original GitHub repository. It includes three splits: training set (train), development set (dev), and test set (test), containing 12724, 200, and 200 samples respectively. Each sample contains three fields: "query" (string type, representing the query question), "positive" (list of strings, a list of questions similar to the query), and "negative" (list of strings, a list of questions dissimilar to the query). For the training set, the "positive" list consists of similar questions automatically identified by AskUbuntu, while the "negative" list is randomly selected questions; for the development and test sets, the "positive" list is manually annotated and may be empty. The dataset has not been deduplicated and is applicable to natural language processing tasks such as sentence similarity and information retrieval.
提供机构:
Sentence Transformers
创建时间:
2026-01-29
原始信息汇总
AskUbuntu 数据集概述
数据集基本信息
- 数据集名称: AskUbuntu
- 数据集来源: 原始数据来自 AskUbuntu.com 2014 语料库转储,并经过预处理。数据集源自原始 GitHub 仓库。
- 创建/引用: Lei et al., 2016
- 语言: 英语 (en)
- 标签: sentence-transformers
数据集内容与结构
- 目的: 该数据集包含来自 AskUbuntu.com 的预处理问题,并附带 400*20 个人工标注,将问题对标记为“相似”或“不相似”。
- 主要特征(列):
query: 查询问题 (数据类型: string)positive: 相似问题列表 (数据类型: list[string])negative: 不相似问题列表 (数据类型: list[string])
- 数据划分:
train(训练集): 12,724 个样本,大小约 74,263,739 字节dev(开发集): 200 个样本,大小约 238,604 字节test(测试集): 200 个样本,大小约 239,279 字节
- 数据划分说明:
- 对于
train划分,“positive”列表是根据 AskUbuntu 标记的相似问题列表,“negative”列表是随机选择的问题列表。 - 对于
dev和test划分,“positive”列表是人工标注的,可能为空。 - 与原始数据集不同,本数据集中“positive”数据并非“negative”数据的子集,它们是互斥的。
- 对于
- 总下载大小: 42,752,991 字节
- 总数据集大小: 74,741,622 字节
数据格式与示例
- 数据文件配置 (
default):train划分路径:data/train-*dev划分路径:data/dev-*test划分路径:data/test-*
- 数据示例: python { "query": "system running in low graphic mode ( ubuntu without monitor )", "positive": [ "getting system to boot in headless mode set-up without display problems" ], "negative": [ "software center not progress showing mergelist error", "how to install google earth or draftsight for 64-bit os ?", "how to install a huawei ec-226 usb modem ?", ... ] }
数据收集与处理
- 收集策略: 从原始源下载
train_random.txt、dev.text和test.txt文件,并将查询 ID 映射到查询文本。 - 去重处理: 未进行去重。
相关资源
- 另请参阅 sentence-transformers/askubuntu-questions 以获取此数据集中所有 AskUbuntu 问题。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,社区问答平台的数据为语义相似性研究提供了丰富的资源。AskUbuntu数据集源自AskUbuntu.com 2014年的语料库转储,经过预处理提取了相关问答。其构建过程首先从原始GitHub仓库下载训练、开发和测试文件,随后将查询ID映射到对应的查询文本。训练集中的正例依据平台标注的相似问题生成,负例则随机选取;而开发集与测试集则包含了人工标注的相似与非相似问题对,确保了数据质量的可靠性。
特点
该数据集以三元组结构呈现,包含查询、正例列表和负例列表,专为句子嵌入和相似性匹配任务设计。其独特之处在于训练集的正负例互斥,避免了数据重叠,提升了模型训练的区分能力。开发集和测试集则基于人工标注,提供了高精度的评估基准。数据集规模适中,涵盖12724个训练样本和400个标注样本,适用于高效的模型训练与验证。
使用方法
研究人员可利用该数据集进行句子表示学习或语义相似性计算。典型应用包括使用如Sentence-BERT等框架,将查询与正负例编码为向量,通过对比学习优化模型。开发集和测试集可用于超参数调优和性能评估,确保模型在真实场景中的泛化能力。数据以标准分割提供,支持直接加载至机器学习流程,促进自然语言处理任务的快速迭代与创新。
背景与挑战
背景概述
AskUbuntu数据集由Lei等研究人员于2016年创建,基于AskUbuntu.com在2014年的语料库转储构建而成。该数据集旨在解决社区问答系统中语义相似性匹配的核心研究问题,通过提供用户查询及其对应相似与非相似问题对,为自然语言处理领域的句子嵌入和检索模型提供基准评估资源。其结构化设计显著推动了问答匹配、信息检索及语义理解等方向的研究进展,成为该领域广泛引用的重要数据集之一。
当前挑战
AskUbuntu数据集所针对的领域挑战在于如何精准识别社区问答平台上语义相近但表述各异的问题,这对模型的语义理解与泛化能力提出了较高要求。在构建过程中,研究人员需从海量非结构化问答数据中提取有效样本,并依赖人工标注确保相似性判定的准确性,这一过程既耗时又易受主观因素影响。此外,数据集的负例通过随机选择生成,可能无法充分涵盖语义相近但实际不相关的复杂情形,为模型训练带来潜在噪声。
常用场景
经典使用场景
在自然语言处理领域,AskUbuntu数据集常被用于训练和评估句子嵌入模型,特别是在社区问答系统中进行语义相似性匹配。该数据集通过提供查询问题及其相似与非相似问题对,为模型学习区分语义相近的文本提供了标准化的训练与测试环境,广泛应用于信息检索和问答系统优化研究。
实际应用
在实际应用中,AskUbuntu数据集被集成到智能客服系统和在线技术论坛中,用于自动匹配用户提问与历史解答,减少重复回答并提升响应速度。例如,在Ubuntu技术支持平台中,基于该数据集的模型能快速检索相似问题,辅助用户自助解决问题,优化用户体验。
衍生相关工作
该数据集衍生了多项经典研究工作,如Lei等人(2016)提出的注意力机制模型用于问答匹配,以及后续基于BERT和Sentence-BERT的语义相似性计算框架。这些工作进一步推动了预训练语言模型在社区问答任务中的应用,成为自然语言处理领域的重要参考文献。
以上内容由遇见数据集搜集并总结生成


