MathLLMs/VoiceAssistant-Eval
收藏Hugging Face2025-10-21 更新2026-01-03 收录
下载链接:
https://hf-mirror.com/datasets/MathLLMs/VoiceAssistant-Eval
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
size_categories:
- 10K<n<100K
task_categories:
- question-answering
- visual-question-answering
- audio-to-audio
- any-to-any
- multiple-choice
- text-generation
pretty_name: VoiceAssistant-Eval
configs:
- config_name: listening_general
data_files:
- split: test
path: listening/test_listening_general*
- config_name: listening_music
data_files:
- split: test
path: listening/test_listening_music*
- config_name: listening_sound
data_files:
- split: test
path: listening/test_listening_sound*
- config_name: listening_speech
data_files:
- split: test
path: listening/test_listening_speech*
- config_name: speaking_assistant
data_files:
- split: test
path: speaking/test_speaking_assistant*
- config_name: speaking_emotion
data_files:
- split: test
path: speaking/test_speaking_emotion*
- config_name: speaking_instruction_following
data_files:
- split: test
path: speaking/test_speaking_instruction_following*
- config_name: speaking_multi_round
data_files:
- split: test
path: speaking/test_speaking_multi_round*
- config_name: speaking_reasoning
data_files:
- split: test
path: speaking/test_speaking_reasoning*
- config_name: speaking_robustness
data_files:
- split: test
path: speaking/test_speaking_robustness*
- config_name: speaking_roleplay
data_files:
- split: test
path: speaking/test_speaking_roleplay*
- config_name: speaking_safety
data_files:
- split: test
path: speaking/test_speaking_safety*
- config_name: viewing_multi_discipline
data_files:
- split: test
path: viewing/test_viewing_multi_discipline*
tags:
- audio
- multimodal
- listening
- speaking
- viewing
- question-answering
- audio-understanding
- reasoning
- instruction-following
- roleplay
- safety
- emotion
- robustness
---
# 🔥 VoiceAssistant-Eval: Benchmarking AI Assistants across Listening, Speaking, and Viewing













[[🌐 Homepage](https://mathllm.github.io/VoiceAssistantEval/)]
[[🔮 Visualization](https://mathllm.github.io/VoiceAssistantEval/#visualization)]
[[💻 Github](https://github.com/mathllm/VoiceAssistant-Eval)]
[[📖 Paper](https://arxiv.org/abs/2509.22651)]
[[📊 Leaderboard ](https://mathllm.github.io/VoiceAssistantEval/#leaderboard)]
[[📊 Detailed Leaderboard ](https://mathllm.github.io/VoiceAssistantEval/#detailedleaderboard)]
[[📊 Roleplay Leaderboard ](https://mathllm.github.io/VoiceAssistantEval/#roleplayleaderboard)]
<p align="center"><img src="https://raw.githubusercontent.com/mathllm/VoiceAssistant-Eval/main/assets/logos/vae_x8_cut.png" width="60%"></p>
## 🚀 Data Usage
```python
from datasets import load_dataset
for split in ['listening_general', 'listening_music', 'listening_sound', 'listening_speech',
'speaking_assistant', 'speaking_emotion', 'speaking_instruction_following',
'speaking_multi_round', 'speaking_reasoning', 'speaking_robustness',
'speaking_roleplay', 'speaking_safety', 'viewing_multi_discipline']:
data = load_dataset("MathLLMs/VoiceAssistant-Eval", split)
print(data)
# load user_audio_0 directly with torchaudio
import torchaudio
waveform, sample_rate = torchaudio.load(data["test"][0]["user_audio_0"])
print(waveform.shape, sample_rate)
# load user_audio_0 directly with soundfile
import soundfile as sf
import io
audio_bytes = data["test"][0]["user_audio_0"]
waveform, sample_rate = sf.read(io.BytesIO(audio_bytes))
print(waveform.shape, sample_rate)
# save user_audio_0 to disk
data = load_dataset("MathLLMs/VoiceAssistant-Eval", 'listening_general')
def save_to_file(data, output_file):
with open(output_file, "wb") as f:
f.write(data)
user_audio_0 = data["test"][0]["user_audio_0"]
save_to_file(user_audio_0, "user_audio_0.wav")
```
## 💥 News
- **[2025-09-27]** Qwen2.5-Omni-7B achieves 59.2\% accuracy on image + text queries but only 42.9\% on image + audio queries, reflecting a 16.3-point drop.
- **[2025-09-27]** Step-Audio-2-mini achieves more than double the listening accuracy of the 32B LLaMA-Omni2 model (40.06 vs. 16.00).
- **[2025-09-27]** We observe that 20 out of 22 models score higher on Speaking than on Listening, and this mismatch highlights the need for more balanced development.
- **[2025-09-27]** GPT-4o-Audio fails to surpass open-source models in 4 out of 13 tasks.
- **[2025-09-27]** Our dataset is now accessible at [huggingface](https://huggingface.co/datasets/MathLLMs/VoiceAssistant-Eval).
- **[2025-09-27]** Our paper is now accessible at [ArXiv Paper](https://arxiv.org/abs/2509.22651).
## 👀 Introduction
The growing capabilities of large language models and multimodal systems have spurred interest in voice-first AI assistants, yet existing benchmarks are inadequate for evaluating the full range of these systems' capabilities.
We summarize four key weaknesses of current benchmarks, highlighting the urgent need for a new evaluation framework:
1. **W1: Lack of voice personalization evaluation.**
Current benchmarks rarely test how well models mimic specific voices, which is key for personalized assistants (e.g., in healthcare). Without this, models may fail in real-world personalized applications.
2. **W2: Limited focus on hands-free interaction.**
Benchmarks often use text-based instructions, ignoring true voice-first, hands-free use. This limits reliability in critical contexts like driving or accessibility for visually impaired users.
3. **W3: Neglect of real-world audio contexts.**
Datasets seldom cover varied, realistic audio environments. Models aren't tested on understanding beyond speech (e.g., music, nature sounds), reducing their everyday usefulness.
4. **W4: Insufficient multi-modal (vision + audio) assessment.**
Benchmarks rarely test joint speech and visual input, missing key scenarios like smart tutors. This gap means benchmarks don't reflect real-world multimodal needs.
We introduce <img src="https://raw.githubusercontent.com/mathllm/VoiceAssistant-Eval/main/assets/logos/vae_inline.png" alt="Logo" style="height:1.2em; vertical-align:middle;"> **VoiceAssistant-Eval**, a comprehensive benchmark designed to assess AI assistants across listening, speaking, and viewing. **VoiceAssistant-Eval comprises 10,497 curated examples spanning 13 task categories.** These tasks include natural sounds, music, and spoken dialogue for listening; multi-turn dialogue, role-play imitation, and various scenarios for speaking; and highly heterogeneous images for viewing.
To demonstrate its utility, we **evaluate 21 open-source models and GPT-4o-Audio**, measuring the quality of the response content and speech, as well as their consistency. The results reveal **three key findings:** **(1)** proprietary models do not universally outperform open-source models; **(2)** most models excel at speaking tasks but lag in audio understanding; and **(3)** well-designed smaller models can rival much larger ones. Notably, the mid-sized Step-Audio-2-mini (7B) achieves more than double the listening accuracy of LLaMA-Omni2-32B-Bilingual.
However, **challenges remain:** multimodal (audio+visual) input and role-play voice imitation tasks are difficult for current models, and significant gaps persist in robustness and safety alignment. VoiceAssistant-Eval identifies these gaps and establishes a rigorous framework for evaluating and guiding the development of next-generation multimodal voice assistants.
---
<p align="left">
<img src="https://raw.githubusercontent.com/mathllm/VoiceAssistant-Eval/main/assets/images/figure1.png" width="100%"> <br>
Figure 1: (a) Scores of six prominent omni-models across 13 tasks. (b) Examples from four newly designed tasks for voice assistants: I. Example from the role-play task with reference audio. II. A truly voice-based multi-turn conversation, instead of providing multi-round context in text. III. Multi-modal (vision + audio) integration understanding. IV. An audio question with music context.
</p>
Please refer to our [project homepage](https://mathllm.github.io/VoiceAssistantEval/) and [the paper](https://arxiv.org/abs/2509.22651) for more details.
## 📐 Dataset Overview
<section class="section">
<div class="container">
| 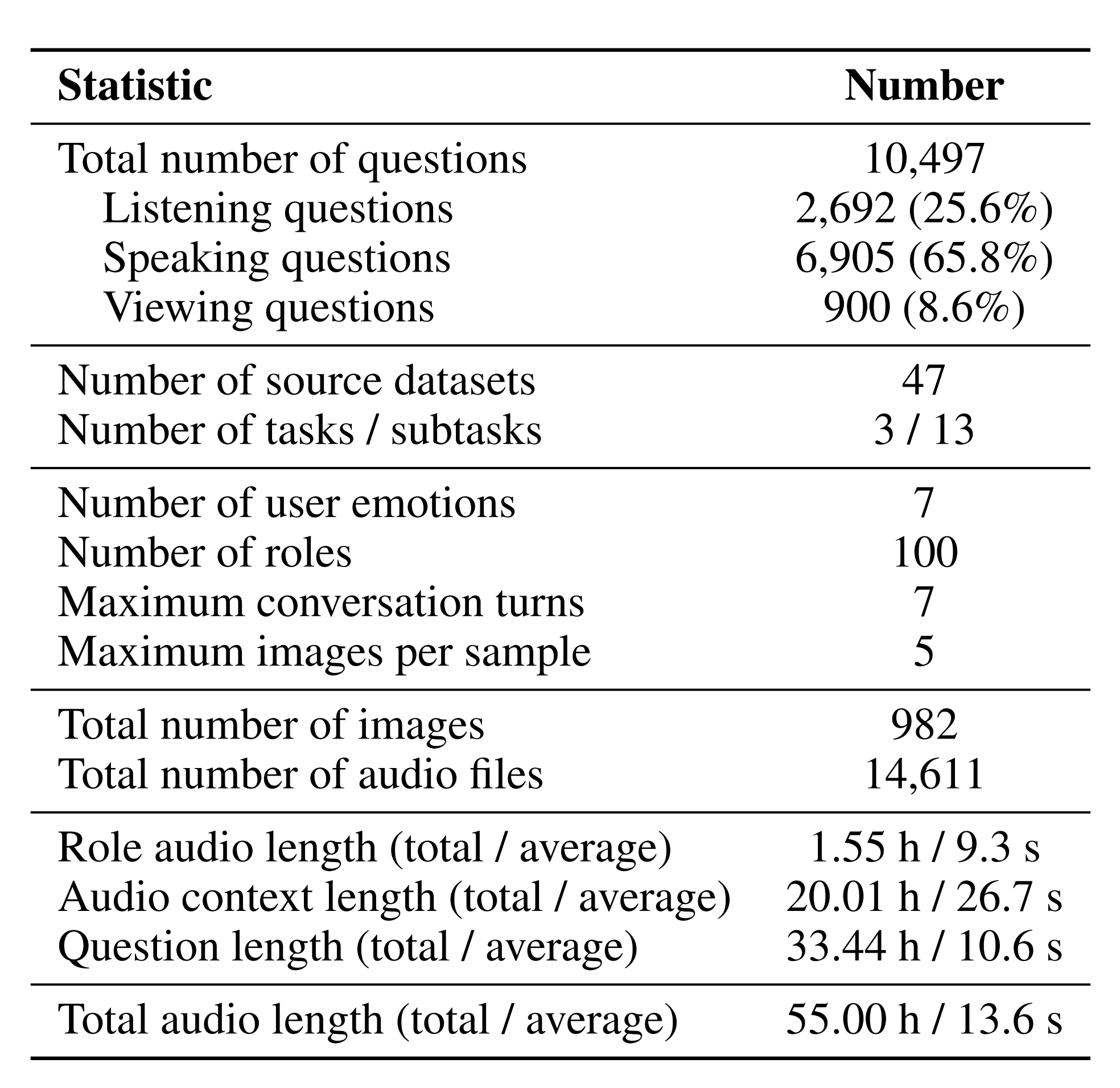 | 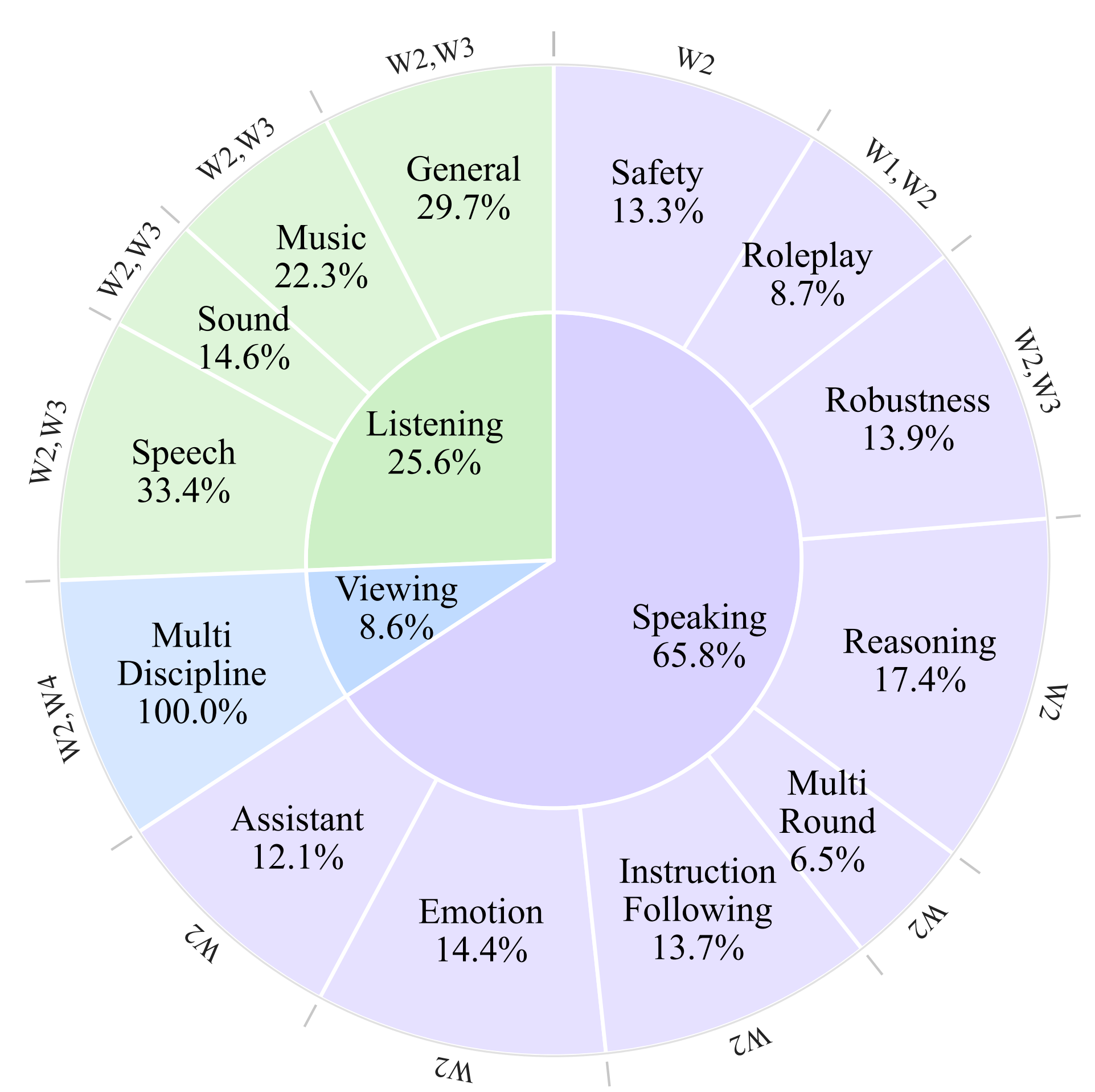 |
|:-----------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------:|
| Overview of principal statistics for **VoiceAssistant-Eval**. | Proportional distribution of tasks and the corresponding weaknesses addressed in **VoiceAssistant-Eval**. |
</div>
</section>
## 🏆 Leaderboards
Explore the comprehensive evaluation results of AI assistants across multiple dimensions:
- **Official Leaderboard:** [Overall scores across Listening, Speaking, and Viewing tasks](https://mathllm.github.io/VoiceAssistantEval/#leaderboard)
- **Detailed Leaderboard:** [In-depth scores across 13 specific tasks](https://mathllm.github.io/VoiceAssistantEval/#detailedleaderboard)
- **Roleplay Leaderboard:** [Performance on the Speaking Roleplay task](https://mathllm.github.io/VoiceAssistantEval/#roleplayleaderboard)
## 📈 Evaluation
See [[💻 Github](https://github.com/mathllm/VoiceAssistant-Eval)] for details.
| Dimension | Method | Models Used | Output Range |
|-----------|--------|-------------|--------------|
| **Emotion** | Emotion Classification | emotion2vec | Probability distribution |
| **Speaker Similarity** | Voice Verification | WeSpeaker | 0-1 similarity score |
| **Content Quality** | LLM Judgment | gpt-oss-20b | 0-100% |
| **Speech Quality** | MOS Prediction | UTMOS22 | 0-100 (MOS×20) |
| **Consistency** | Modified WER | Whisper-Large-v3 | 0-100% (100-WER) |
This comprehensive evaluation framework enables thorough assessment of multimodal AI assistants across listening, speaking, and viewing capabilities, providing both granular insights and unified performance metrics.
## 📝 Citation
If you find this benchmark useful in your research, please consider citing this BibTex:
```
@misc{wang2025voiceassistantevalbenchmarkingaiassistants,
title={VoiceAssistant-Eval: Benchmarking AI Assistants across Listening, Speaking, and Viewing},
author={Ke Wang and Houxing Ren and Zimu Lu and Mingjie Zhan and Hongsheng Li},
year={2025},
eprint={2509.22651},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.22651},
}
```
## 🧠 Related Work
- **[MathVision🔥]** [Measuring Multimodal Mathematical Reasoning with the MATH-Vision Dataset](https://mathllm.github.io/mathvision/)
- **[MathCoder-VL]** [MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning](https://github.com/mathllm/MathCoder)
- **[CSV]** [Solving Challenging Math Word Problems Using GPT-4 Code Interpreter with Code-based Self-Verification](https://wangk.org/publications/1_iclr2024_csv/)
- **[MathGenie]** [MathGenie: Generating Synthetic Data with Question Back-translation for Enhancing Mathematical Reasoning of LLMs](https://github.com/MathGenie/MathGenie)
- **[MathCoder]** [MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning](https://github.com/mathllm/MathCoder)
- **[MathCoder2]** [MathCoder2: Better Math Reasoning from Continued Pretraining on Model-translated Mathematical Code](https://mathllm.github.io/mathcoder2/)
license: mit
size_categories:
- 10K<n<100K
task_categories:
- 问答
- 视觉问答
- 音频转音频
- 任意到任意
- 多项选择
- 文本生成
pretty_name: VoiceAssistant-Eval
configs:
- 配置名称:通用听力
数据文件:
- 拆分:测试集
路径:listening/test_listening_general*
- 配置名称:音乐听力
数据文件:
- 拆分:测试集
路径:listening/test_listening_music*
- 配置名称:声音听力
数据文件:
- 拆分:测试集
路径:listening/test_listening_sound*
- 配置名称:语音听力
数据文件:
- 拆分:测试集
路径:listening/test_listening_speech*
- 配置名称:助手对话
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_assistant*
- 配置名称:情感表达
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_emotion*
- 配置名称:指令遵循
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_instruction_following*
- 配置名称:多轮对话
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_multi_round*
- 配置名称:推理表达
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_reasoning*
- 配置名称:鲁棒性表达
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_robustness*
- 配置名称:角色扮演
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_roleplay*
- 配置名称:安全表达
数据文件:
- 拆分:测试集
路径:speaking/test_speaking_safety*
- 配置名称:多学科视觉
数据文件:
- 拆分:测试集
路径:viewing/test_viewing_multi_discipline*
tags:
- 音频
- 多模态
- 听力
- 表达
- 视觉
- 问答
- 音频理解
- 推理
- 指令遵循
- 角色扮演
- 安全
- 情感
- 鲁棒性
# 🔥 VoiceAssistant-Eval:跨听、说、视维度的AI助手基准测试













[[🌐 主页](https://mathllm.github.io/VoiceAssistantEval/)]
[[🔮 可视化](https://mathllm.github.io/VoiceAssistantEval/#visualization)]
[[💻 Github](https://github.com/mathllm/VoiceAssistant-Eval)]
[[📖 论文](https://arxiv.org/abs/2509.22651)]
[[📊 排行榜 ](https://mathllm.github.io/VoiceAssistantEval/#leaderboard)]
[[📊 详细排行榜 ](https://mathllm.github.io/VoiceAssistantEval/#detailedleaderboard)]
[[📊 角色扮演排行榜 ](https://mathllm.github.io/VoiceAssistantEval/#roleplayleaderboard)]
<p align="center"><img src="https://raw.githubusercontent.com/mathllm/VoiceAssistant-Eval/main/assets/logos/vae_x8_cut.png" width="60%"></p>
## 🚀 数据使用
python
from datasets import load_dataset
for split in ['listening_general', 'listening_music', 'listening_sound', 'listening_speech',
'speaking_assistant', 'speaking_emotion', 'speaking_instruction_following',
'speaking_multi_round', 'speaking_reasoning', 'speaking_robustness',
'speaking_roleplay', 'speaking_safety', 'viewing_multi_discipline']:
data = load_dataset("MathLLMs/VoiceAssistant-Eval", split)
print(data)
# 使用torchaudio直接加载user_audio_0
import torchaudio
waveform, sample_rate = torchaudio.load(data["test"][0]["user_audio_0"])
print(waveform.shape, sample_rate)
# 使用soundfile直接加载user_audio_0
import soundfile as sf
import io
audio_bytes = data["test"][0]["user_audio_0"]
waveform, sample_rate = sf.read(io.BytesIO(audio_bytes))
print(waveform.shape, sample_rate)
# 将user_audio_0保存到磁盘
data = load_dataset("MathLLMs/VoiceAssistant-Eval", 'listening_general')
def save_to_file(data, output_file):
with open(output_file, "wb") as f:
f.write(data)
user_audio_0 = data["test"][0]["user_audio_0"]
save_to_file(user_audio_0, "user_audio_0.wav")
## 💥 最新动态
- **[2025-09-27]** Qwen2.5-Omni-7B在图像+文本查询上达到59.2%的准确率,但在图像+音频查询上仅为42.9%,相差16.3个百分点。
- **[2025-09-27]** Step-Audio-2-mini的听力准确率是32B量级LLaMA-Omni2模型的两倍多(40.06 vs. 16.00)。
- **[2025-09-27]** 我们观察到22个模型中有20个在表达任务上得分高于听力任务,这种失衡凸显了均衡发展的必要性。
- **[2025-09-27]** GPT-4o-Audio在13个任务中的4个未能超越开源模型。
- **[2025-09-27]** 我们的数据集现已在[Hugging Face](https://huggingface.co/datasets/MathLLMs/VoiceAssistant-Eval)开放获取。
- **[2025-09-27]** 我们的论文现已在[ArXiv](https://arxiv.org/abs/2509.22651)开放获取。
## 👀 引言
大语言模型(Large Language Models)和多模态系统的能力持续提升,推动了以语音为核心的AI助手研究热潮,但现有基准测试不足以评估这类系统的完整能力范围。
我们总结了当前基准测试的四个关键弱点,强调构建新评估框架的迫切性:
1. **W1:缺乏语音个性化评估**
当前基准测试极少验证模型模拟特定语音的能力,而这是个性化助手(如医疗场景)的核心需求。缺乏该评估将导致模型在实际个性化应用中失效。
2. **W2:对免手持交互关注不足**
基准测试常采用文本指令,忽视真正的语音优先、免手持使用场景。这限制了模型在驾驶或视障用户无障碍访问等关键场景中的可靠性。
3. **W3:忽略真实世界音频语境**
数据集很少覆盖多样、真实的音频环境。模型未被测试语音之外的理解能力(如音乐、自然声音),降低了日常实用性。
4. **W4:多模态(视觉+音频)评估不足**
基准测试极少验证语音与视觉输入的联合处理能力,缺失智能导师等关键场景。这一差距导致基准测试无法反映真实世界的多模态需求。
我们引入 <img src="https://raw.githubusercontent.com/mathllm/VoiceAssistant-Eval/main/assets/logos/vae_inline.png" alt="Logo" style="height:1.2em; vertical-align:middle;"> **VoiceAssistant-Eval**,一个全面的基准测试,旨在评估AI助手的听、说、视能力。**VoiceAssistant-Eval包含10,497个精心挑选的样本,覆盖13个任务类别**。这些任务包括听力维度的自然声音、音乐和对话;表达维度的多轮对话、角色扮演模仿及各类场景;视觉维度的高度异构图像。
为验证其效用,我们**评估了21个开源模型和GPT-4o-Audio**,测量响应内容与语音质量及一致性。结果揭示**三大关键发现**:**(1)** 闭源模型并非普遍优于开源模型;**(2)** 多数模型擅长表达任务但音频理解能力滞后;**(3)** 设计精良的小型模型可匹敌大型模型。值得注意的是,中型模型Step-Audio-2-mini(7B)的听力准确率是LLaMA-Omni2-32B-Bilingual的两倍多。
然而,**挑战依然存在**:多模态(音频+视觉)输入和角色扮演语音模仿任务对当前模型仍具难度,鲁棒性与安全对齐方面仍有显著差距。VoiceAssistant-Eval识别了这些差距,并为下一代多模态语音助手的评估与开发提供了严谨框架。
---
<p align="left">
<img src="https://raw.githubusercontent.com/mathllm/VoiceAssistant-Eval/main/assets/images/figure1.png" width="100%"> <br>
图1:(a) 六个主流全模态模型在13个任务上的得分。(b) 四个新设计的语音助手任务示例:I. 带参考音频的角色扮演任务示例;II. 真正的语音多轮对话(非文本上下文);III. 多模态(视觉+音频)整合理解;IV. 音乐语境下的音频问题。
</p>
更多细节请参考我们的[项目主页](https://mathllm.github.io/VoiceAssistantEval/)和[论文](https://arxiv.org/abs/2509.22651)。
## 📐 数据集概览
<section class="section">
<div class="container">
|  |  |
|:-----------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------:|
| VoiceAssistant-Eval的主要统计概览 | VoiceAssistant-Eval的任务比例分布及对应解决的弱点 |
</div>
</section>
## 🏆 排行榜
探索AI助手在多维度的综合评估结果:
- **官方排行榜**:[听、说、视任务综合得分](https://mathllm.github.io/VoiceAssistantEval/#leaderboard)
- **详细排行榜**:[13个具体任务的深度得分](https://mathllm.github.io/VoiceAssistantEval/#detailedleaderboard)
- **角色扮演排行榜**:[表达角色扮演任务的性能](https://mathllm.github.io/VoiceAssistantEval/#roleplayleaderboard)
## 📈 评估
详情请见 [[💻 Github](https://github.com/mathllm/VoiceAssistant-Eval)]。
| 维度 | 方法 | 使用模型 | 输出范围 |
|-----------|--------|-------------|--------------|
| **情感** | 情感分类 | emotion2vec | 概率分布 |
| **说话人相似度** | 语音验证 | WeSpeaker | 0-1相似度得分 |
| **内容质量** | LLM判断 | gpt-oss-20b | 0-100% |
| **语音质量** | MOS预测 | UTMOS22 | 0-100(MOS×20) |
| **一致性** | 改进WER | Whisper-Large-v3 | 0-100%(100-WER) |
该综合评估框架支持对多模态AI助手听、说、视能力的全面评估,提供细粒度洞察与统一性能指标。
## 📝 引用
若您的研究使用本基准测试,请考虑引用以下BibTex:
@misc{wang2025voiceassistantevalbenchmarkingaiassistants,
title={VoiceAssistant-Eval: Benchmarking AI Assistants across Listening, Speaking, and Viewing},
author={Ke Wang and Houxing Ren and Zimu Lu and Mingjie Zhan and Hongsheng Li},
year={2025},
eprint={2509.22651},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.22651},
}
## 🧠 相关工作
- **[MathVision🔥]** [使用MATH-Vision数据集测量多模态数学推理能力](https://mathllm.github.io/mathvision/)
- **[MathCoder-VL]** [MathCoder-VL:桥接视觉与代码以增强多模态数学推理](https://github.com/mathllm/MathCoder)
- **[CSV]** [使用GPT-4代码解释器与基于代码的自验证解决挑战性数学应用题](https://wangk.org/publications/1_iclr2024_csv/)
- **[MathGenie]** [MathGenie:通过问题回译生成合成数据以增强LLM的数学推理能力](https://github.com/MathGenie/MathGenie)
- **[MathCoder]** [MathCoder:LLM中的无缝代码集成以增强数学推理](https://github.com/mathllm/MathCoder)
- **[MathCoder2]** [MathCoder2:通过模型翻译数学代码的持续预训练提升数学推理能力](https://mathllm.github.io/mathcoder2/)
提供机构:
MathLLMs


