Abzalbek89/kk-tokenizer-fertility-baseline
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Abzalbek89/kk-tokenizer-fertility-baseline
下载链接
链接失效反馈官方服务:
资源简介:
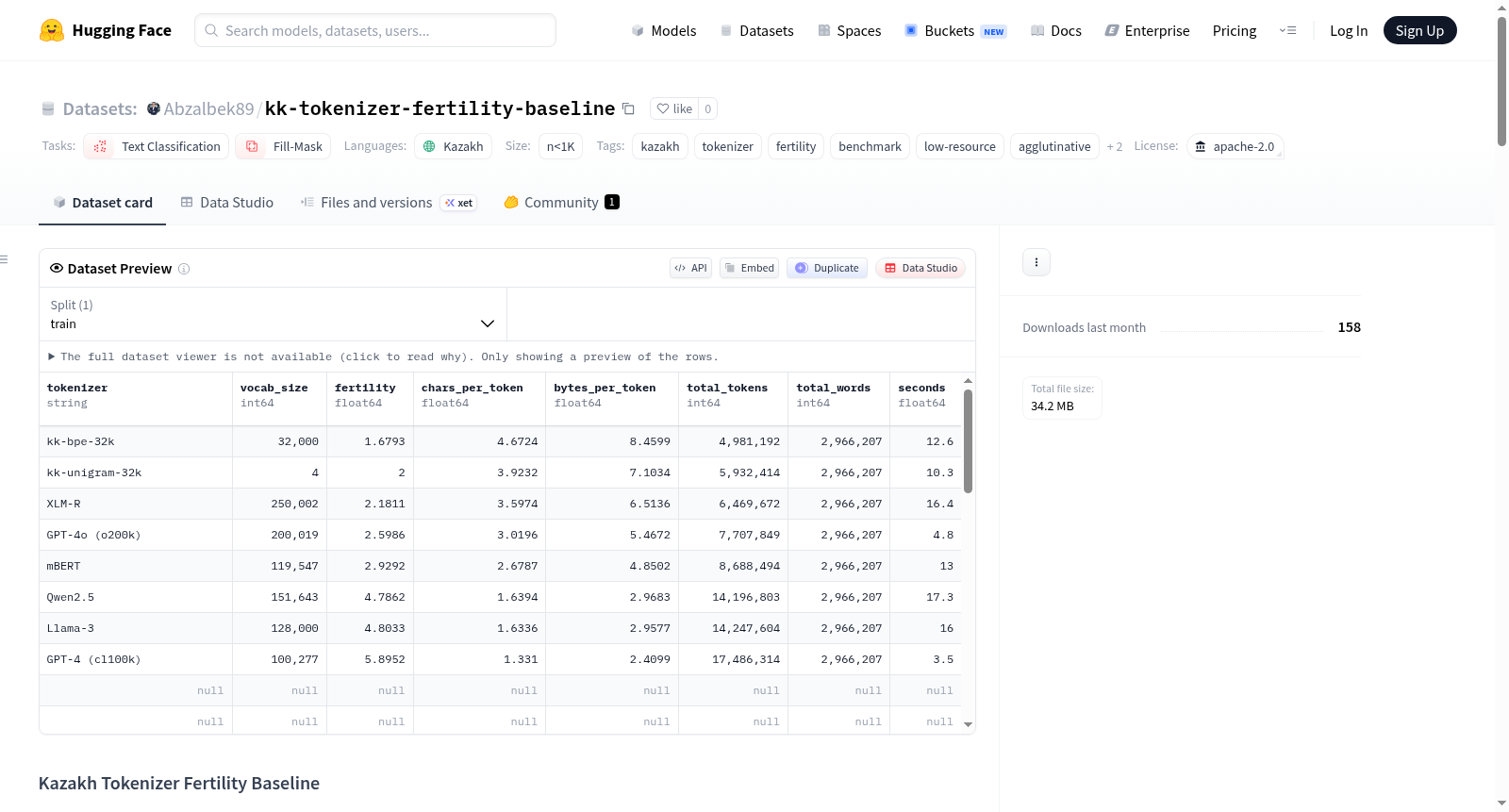
该数据集是关于哈萨克语分词器生育力基准的可重复性研究,作为论文《哈萨克语小语言模型的分词器优化》(准备中,目标:ACM TALLIP)的配套成果。数据集比较了不同分词器在哈萨克语文本上的性能,包括生育力(总标记数/总空格分隔词数,越低越好)和压缩率(字符/标记,越高越好)。评估集包含来自[`Abzalbek89/corpus_clean`](https://huggingface.co/datasets/Abzalbek89/corpus_clean)验证分割的2,966,207个空格分隔词(约15K文档)。数据集还提供了训练好的分词器(词汇量=32,000)和参考分词器(如mBERT、XLM-R、Llama-3等)的详细排名和性能指标。
This dataset is a reproducible fertility benchmark of subword tokenizers on the Kazakh language, serving as a companion artifact for the paper *"Tokenizer Optimization for Kazakh Small Language Models"* (in preparation, target: ACM TALLIP). It compares the performance of various tokenizers on Kazakh text, including fertility (total tokens / total whitespace-words, lower is better) and compression (chars/token, higher is better). The held-out evaluation set consists of 2,966,207 whitespace-words (≈15K documents) from the validation split of [`Abzalbek89/corpus_clean`](https://huggingface.co/datasets/Abzalbek89/corpus_clean). The dataset provides detailed rankings and performance metrics for trained tokenizers (vocab = 32,000) and reference tokenizers (e.g., mBERT, XLM-R, Llama-3, etc.).
提供机构:
Abzalbek89
搜集汇总
数据集介绍
构建方式
该数据集专为评估哈萨克语子词分词器的生育率(Fertility)而构建,旨在衡量分词器将文本分割为子词片段的有效性。研究团队从验证集中抽取了约2,966,207个空格词(约15K文档)作为保留评估集,以此为基础计算每个分词器的总tokens数与总空格词数的比值,从而得到生育率指标。此外,还引入了压缩率(Chars/Token)作为辅助评估维度。数据集中涵盖了七种定制分词器与六种多语言/工业级分词器,所有定制分词器均使用相同的训练语料与32,000词汇量进行训练,确保了对比的公平性。
特点
该数据集的核心价值在于其对低资源、黏着性语言——哈萨克语的专项优化评估。数据显示,针对哈萨克语训练的定制分词器在生育率上显著优于通用多语言分词器。例如,最优的kk-bpe-32k分词器生育率仅为1.679,而GPT-4(cl100k)的生育率高达5.895,即GPT-4的分词效率比最佳哈萨克语分词器差3.51倍,这直接转化为约72%的API成本节省与3.5倍的有效上下文窗口扩展。数据集不仅包含分词器排名,还附带了完整的实验脚本与结果文件,支持完全复现。
使用方法
使用者可通过Python环境快速复现实验结果。所需依赖包括datasets、transformers、tokenizers、sentencepiece等库,建议在具备≥30GB磁盘与≥16GB内存的云实例上运行。首先通过pip安装依赖并设置Hugging Face访问令牌,然后下载实验脚本experiment_morph.py并执行。完整运行耗时约30分钟(使用缓存Morfessor模型)至70分钟(冷启动)。此外,数据集仓库中提供了所有定制分词器的单独仓储链接,便于用户直接加载使用或进行二次开发。
背景与挑战
背景概述
该数据集由研究者Abzalbek Ulasbek于2026年创建,旨在系统评估子词分词器在哈萨克语这一低资源、黏着型语言上的效率性能。核心研究问题聚焦于如何设计针对哈萨克语的高效分词器,以降低其对多语言或工业级分词器(如GPT-4)的依赖性,并为哈萨克语小型语言模型的优化提供理论支撑。数据集通过量化13种分词器的生育率指标,首次构建了哈萨克语分词效率的公开基准。其对自然语言处理领域的影响力在于揭示了现代多语言分词器在黏着语上的显著劣势,为低资源语言的分词器设计与模型压缩指明方向,具有重要的学术参考与应用价值。
当前挑战
该数据集的核心挑战包括:其一,所解决领域问题为哈萨克语分词器效率评估与优化,由于哈萨克语形态复杂、词汇组合性强,通用分词器易产生高分割冗余,导致语言模型在处理该类语言时面临计算成本剧增与语义理解偏差的难题;其二,构建过程中遭遇的挑战主要在于确保评估的公平性与可复现性,需设计统一的训练语料、指标体系和实验流程,并解决跨库分词器(如HuggingFace Tokenizers与SentencePiece)的兼容性差异,同时引入形态学预分割方法以探索其对多语言分词器性能的影响,工作量繁复且技术细节众多。
常用场景
经典使用场景
在低资源语言的自然语言处理研究中,分词器(Tokenizer)的优劣直接决定了模型对文本的表示效率与下游任务性能。kk-tokenizer-fertility-baseline 数据集专门面向哈萨克语这一典型黏着语,提供了一个标准化的分词器费率(Fertility)评测基准。研究者可在此数据集上,通过测量每个空白词单元被分割成的子词数量,系统性地对比 BPE、Unigram 等经典子词分词算法,以及形态学预分割策略与通用多语言分词器(如 GPT-4、XLM-R)在哈萨克语上的分词稠密程度,从而筛选出最佳分词方案。
衍生相关工作
依托该基准已衍生出一系列面向哈萨克语的定制分词器仓库(如 kk-bpe-32k、kk-morph-hf-bpe-32k 等),以及配套的 Morfessor 形态分割模型。相关论文《Tokenizer Optimization for Kazakh Small Language Models》正在投稿 ACM TALLIP,系统论述了黏着语场景下分词器费率的优化路径。未来有望催生出更多针对突厥语族及其他黏着语族(如蒙古语、芬兰语)的类似基准,形成跨语言分词效能量化体系,并为设计形态感知型子词模型提供实验支撑。
数据集最近研究
最新研究方向
针对哈萨克语等低资源黏着语,子词分词器效率优化的基准评估与神经语言模型适配性研究。该数据集系统对比了13种分词器的生育率(Fertility)指标,发现专为哈萨克语训练的BPE分词器(kk-bpe-32k)相比GPT-4的cl100k分词器效率提升3.51倍,显著降低约72%的API调用成本并扩展有效上下文窗口。这一成果揭示了主流多语言分词器在形态丰富语言上的过度碎片化问题,为构建经济高效的小型语言模型(SLM)提供了可复现的优化基线。伴随LLM部署成本热议和低资源语言数字化需求增长,该工作通过形态感知分词与对比实验范式,推动了面向哈萨克语NLP基础设施的精简化发展,对中亚语言生态的智能化演进具有实证参考价值。
以上内容由遇见数据集搜集并总结生成


