AIMClab-RUC/PhD
收藏Hugging Face2025-04-06 更新2025-04-26 收录
下载链接:
https://hf-mirror.com/datasets/AIMClab-RUC/PhD
下载链接
链接失效反馈官方服务:
资源简介:
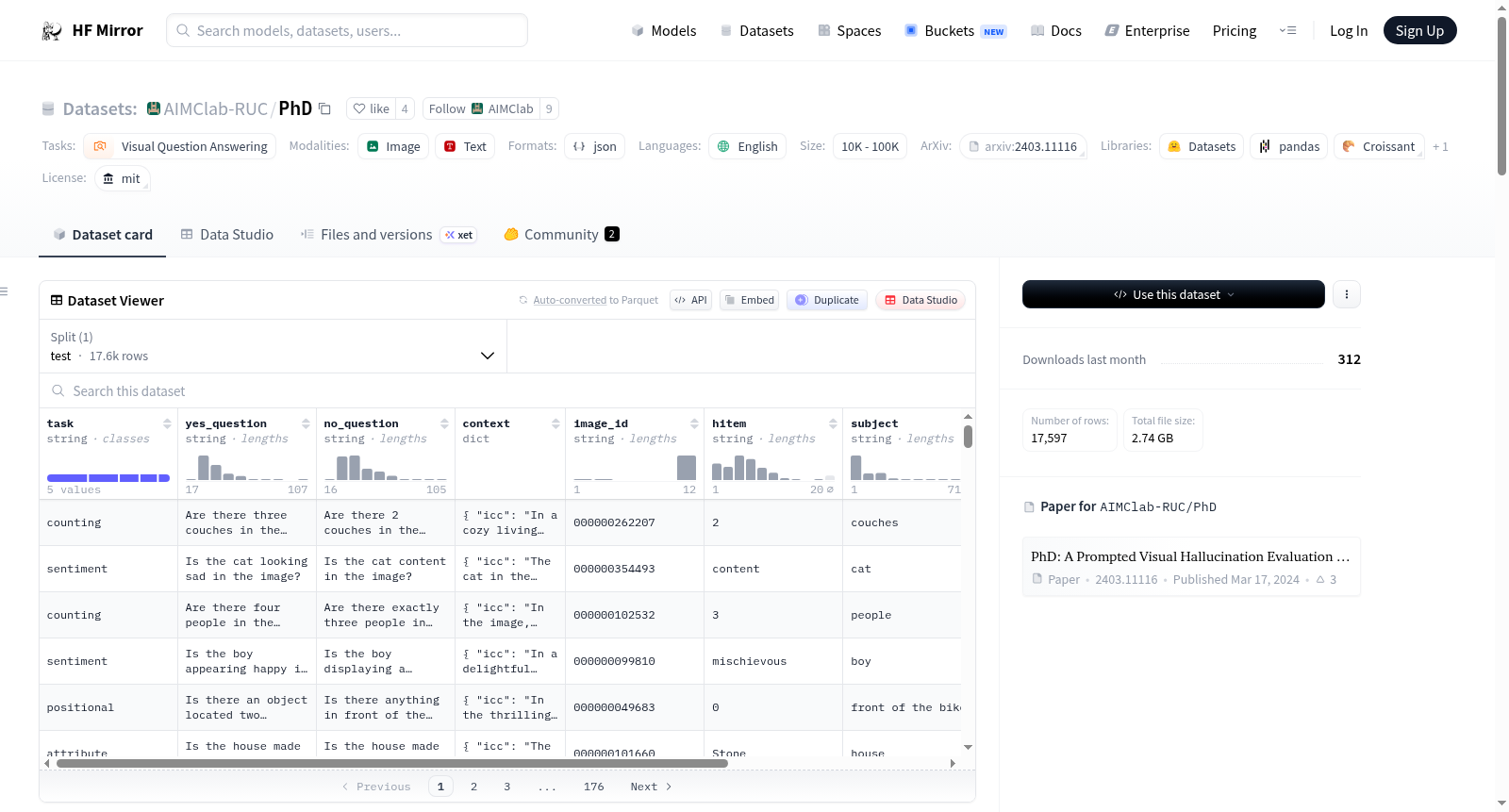
PhD数据集是一个用于视觉问答任务的数据集,包含四种模式:PhD-base、PhD-sec、PhD-icc和PhD-ccs。数据集使用COCO 2014图像和AI生成的图像,每个样本包含图像ID、任务类型、是/否问题、幻觉项、真实标签、问题主题以及上下文信息。PhD-base模式使用是/否问题,PhD-sec和PhD-icc模式结合上下文和问题,PhD-ccs模式包含AI生成图像的特定描述。
The PhD dataset is designed for visual question answering tasks, consisting of four modes: PhD-base, PhD-sec, PhD-icc, and PhD-ccs. It uses COCO 2014 images and AI-generated images. Each sample includes an image ID, task type, yes/no questions, hallucination item, ground truth, questioned subject, and context information. PhD-base mode uses yes/no questions, PhD-sec and PhD-icc modes combine context with questions, and PhD-ccs mode includes specific descriptions of AI-generated images.
提供机构:
AIMClab-RUC
搜集汇总
数据集介绍
构建方式
在视觉问答领域,评估模型对图像内容的理解能力至关重要。PhD数据集通过精心设计的四种模式构建而成,其基础数据源自COCO 2014图像库,涵盖训练集与验证集。针对PhD-base、PhD-sec及PhD-icc模式,研究者利用ChatGPT生成具有视觉幻觉特性的问题对,每个样本包含肯定与否定形式的问题,并标注了幻觉项、真实答案及上下文信息。而PhD-ccs模式则采用人工智能生成的图像,专门用于考察模型对常识违背场景的识别能力,每张图像均附有违反常识的描述,从而形成多维度、结构化的评估体系。
使用方法
使用该数据集时,研究者可通过加载统一的JSON文件灵活调用不同评估模式。对于PhD-base,直接提取样本中的问题字段即可构建测试项;而PhD-sec与PhD-icc需将特定上下文与问题拼接,并插入一致性遵循指令,以模拟真实场景中的信息冲突。PhD-ccs模式则依赖独立存储的生成图像及其反常识描述。数据集提供了完整的代码示例,指导用户根据图像ID自动匹配COCO图像路径或生成图像路径,并返回四种模式的结构化数据列表,便于集成至现有评估框架进行批量测试与结果分析。
背景与挑战
背景概述
在视觉语言模型迅猛发展的浪潮中,模型生成的幻觉问题日益凸显,成为制约其可靠应用的关键瓶颈。为系统评估和缓解此问题,中国人民大学高瓴人工智能学院AIMClab团队于2024年创建了PhD数据集,并作为CVPR2025高亮论文发布。该数据集旨在精准评估模型在视觉问答任务中产生与现实图像内容不符的幻觉回答的能力,其核心研究问题聚焦于模型对视觉信息的忠实理解与推理。通过构建包含基础、误导性语境及反常识图像在内的四种评测模式,PhD数据集为深入剖析模型幻觉的成因与类型提供了标准化基准,显著推动了视觉语言模型可信评估领域的研究进程。
当前挑战
PhD数据集致力于解决视觉问答领域中模型产生视觉幻觉这一核心挑战。具体而言,其设计旨在迫使模型在复杂场景下暴露缺陷:一是需在包含误导性文本语境的干扰中,依然坚守对图像内容的忠实理解;二是需对违背物理或常识的生成图像内容进行准确判断,这对模型的跨模态对齐与常识推理能力提出了极高要求。在构建过程中,挑战同样艰巨:如何利用大语言模型自动化生成高质量、多样化的幻觉诱导问题与干扰语境,以确保评测的广度与深度;同时,为创建反常识图像子集,需设计有效的生成流程以确保图像既违背常识,又在视觉上合理且评测目标明确,这对数据构建的严谨性与创造性构成了双重考验。
常用场景
经典使用场景
在视觉语言模型评估领域,PhD数据集被广泛用于系统性地检测模型产生的视觉幻觉现象。该数据集通过精心设计的四种模式——基础模式、误导性上下文模式、错误上下文模式以及反常识模式,构建了多层次的评估框架。研究人员利用这些模式生成针对性的问题,要求模型基于给定图像进行回答,从而精确量化模型在视觉理解与语言生成之间的一致性偏差,为模型幻觉的定量分析提供了标准化基准。
解决学术问题
PhD数据集有效解决了视觉语言模型中长期存在的幻觉评估难题。传统评估方法往往难以区分模型的知识缺陷与幻觉现象,而该数据集通过引入对抗性上下文与反常识图像,将幻觉问题解构为可测量的维度。它不仅揭示了模型在物体属性、空间关系、场景理解等五个核心任务上的幻觉模式,更推动了幻觉成因的理论研究,为构建可信赖的多模态人工智能系统奠定了实证基础。
实际应用
在实际部署场景中,PhD数据集已成为多模态模型质量监控的重要工具。企业研发团队在模型上线前,会利用该数据集的四种模式进行压力测试,识别模型在复杂视觉推理中的脆弱环节。教育科技领域借助其反常识评估模块,开发能够纠正认知偏差的智能辅导系统。自动驾驶系统的视觉问答模块也通过该数据集验证其环境描述的可靠性,确保感知系统不会产生危及安全的幻觉性描述。
数据集最近研究
最新研究方向
在视觉语言模型快速发展的背景下,视觉幻觉问题成为制约模型可靠性的关键瓶颈。PhD数据集作为CVPR2025高亮工作,通过ChatGPT构建的多模态评估基准,系统性地探索模型在基础视觉问答、误导性上下文及反常识场景下的幻觉行为。该数据集融合了真实图像与AI生成内容,推动了幻觉检测与缓解技术的前沿研究,为模型安全性与可信赖性评估提供了标准化工具,直接影响着自动驾驶、医疗影像分析等高风险领域多模态系统的部署与优化。
以上内容由遇见数据集搜集并总结生成


