5HT_Ki_Prediction
收藏Hugging Face2025-04-23 更新2025-04-24 收录
下载链接:
https://huggingface.co/datasets/sarahantgan/5HT_Ki_Prediction
下载链接
链接失效反馈官方服务:
资源简介:
5-HT受体结合亲和力预测数据集,该数据集从PDSP Ki数据库中整理而来,用于支持训练机器学习模型,预测配体与5-HT受体的结合亲和力(以nM为单位的Ki值)。数据集包含经过清洗的Ki数据集、分子表示的2048位Morgan(ECFP4)指纹、训练好的scikit-learn随机森林回归模型、测试集上的预测结果以及训练模型的完整Jupyter笔记本。
This 5-HT receptor binding affinity prediction dataset is curated from the PDSP Ki database, intended to support the training of machine learning models for predicting the binding affinity (Ki values in nM units) between ligands and 5-HT receptors. The dataset includes a cleaned Ki dataset, 2048-bit Morgan (ECFP4) fingerprints as molecular representations, a trained scikit-learn random forest regression model, prediction results on the test set, and a complete Jupyter notebook for model training.
创建时间:
2025-04-21
原始信息汇总
5-HT Ki预测数据集概述
基本信息
- 名称: 5-HT Ki Prediction Dataset
- 语言: 英语 (en)
- 许可证: CC-BY-4.0
- 数据规模: 100-1K
- 任务类型: 回归 (regression)
- 标签: 生物活性 (bioactivity)、化学信息学 (cheminformatics)、回归 (regression)、血清素 (serotonin)、结合亲和力 (binding-affinity)
数据集结构
- 特征:
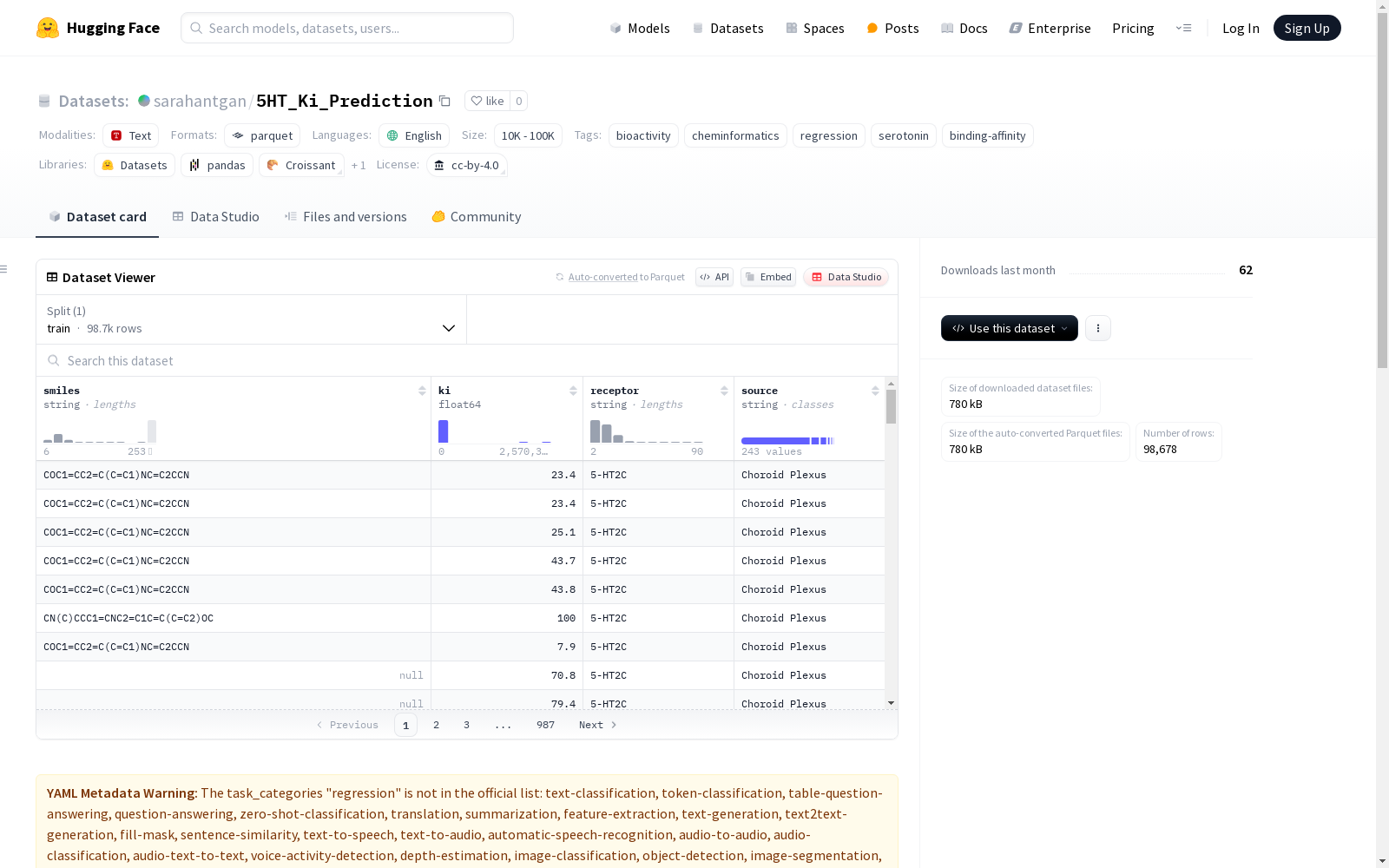
smiles: 字符串类型,表示分子的SMILES字符串ki: 浮点数类型,表示结合亲和力 (Ki in nM)receptor: 字符串类型,表示受体source: 字符串类型,表示数据来源
- 数据划分:
train: 58,304,93字节,98,678个样本
文件内容
curated_ki_database.csv: 经过清理的Ki数据集,筛选了5-HT目标fingerprints_with_ki.csv: 以2048位Morgan (ECFP4)指纹表示的分子rf_model.pkl: 训练好的scikit-learn RandomForestRegressor模型test_predictions.csv: 测试集上的预测值与实际Ki值train_model.ipynb: 包含训练代码和评估的完整Jupyter笔记本
建模方法
- 使用MolVS标准化分子
- 使用RDKit将SMILES字符串转换为2048位Morgan指纹 (ECFP4)
- 使用scikit-learn训练随机森林回归模型
- 在20%的测试集上评估模型
模型性能
- R²分数: 0.257
- RMSE: 4193.72 nM
引用与来源
- 来源: PDSP Ki Database (https://pdsp.unc.edu/databases/kidb.php)
- 引用要求: 使用此数据集时,请适当引用PDSP数据库
作者信息
- 作者: Sara Hantgan
- 机构: 密歇根大学
- 项目: BIOINF 595 Final Project
- 时间: 2025年冬季
搜集汇总
数据集介绍
构建方式
在神经药理学研究中,5-HT受体配体结合亲和力的精准预测对药物研发具有重要意义。该数据集从PDSP Ki数据库中精心筛选并标准化处理,聚焦于5-HT受体的配体结合数据。通过MolVS工具对分子结构进行标准化,利用RDKit将SMILES字符串转化为2048位摩根指纹(ECFP4),构建了包含98678个样本的训练集,每个样本均包含分子结构、Ki值、受体类型及数据来源等关键信息。
使用方法
该数据集为机器学习在计算药物化学领域的应用提供了标准化的研究平台。研究者可直接使用预计算的分子指纹进行模型训练,或基于原始SMILES开发更先进的分子表示方法。配套提供的Jupyter笔记本(train_model.ipynb)完整展示了从数据预处理到模型训练的全流程,预训练的随机森林模型(rf_model.pkl)可作为迁移学习的起点。测试集预测结果(test_predictions.csv)便于进行模型性能的对比验证。
背景与挑战
背景概述
5HT_Ki_Prediction数据集由密歇根大学的Sara Hantgan于2025年基于PDSP Ki数据库构建,专注于血清素(5-HT)受体配体结合亲和力的预测研究。该数据集整合了98678个分子样本,涵盖SMILES字符串、结合亲和力(Ki值)、受体类型等关键特征,旨在为计算化学和药物发现领域提供机器学习模型的训练基础。作为神经递质受体的重要亚型,5-HT受体与抑郁症、焦虑症等多种精神疾病密切相关,该数据集的建立为高通量虚拟筛选和药物设计提供了重要参考。
当前挑战
该数据集面临的核心挑战体现在科学问题与构建过程两个维度。在科学层面,血清素受体配体结合涉及复杂的分子相互作用机制,现有模型R²仅0.257的预测精度揭示构效关系建模的难度;PDSP原始数据中Ki值跨越多个数量级,数值分布的高度偏态对回归算法提出严峻考验。在技术层面,分子结构的标准化处理需克服互变异构体归一化等难题,而ECFP4指纹对三维构象信息的丢失可能限制模型性能。如何从有限且噪声明显的实验数据中提取有效的分子特征表征,成为亟待突破的关键瓶颈。
常用场景
经典使用场景
在神经药理学和计算化学领域,5HT_Ki_Prediction数据集为研究5-羟色胺受体(5-HT)与配体结合亲和力的定量关系提供了重要资源。该数据集通过整合PDSP Ki数据库中的实验数据,支持机器学习模型训练,用于预测配体与不同5-HT受体亚型的结合亲和力(Ki值)。经典应用场景包括构建定量构效关系(QSAR)模型,探索分子结构特征与生物活性之间的关联规律。
解决学术问题
该数据集有效解决了神经递质受体配体发现中的关键科学问题。通过提供标准化的结合亲和力数据,研究者能够系统评估计算方法对5-HT受体-配体相互作用的预测精度。其意义在于建立了连接分子描述符与药理活性的计算桥梁,为理解5-HT受体选择性机制提供了数据基础,显著推进了基于结构的神经药物设计研究。
实际应用
在实际药物研发中,该数据集支持抗抑郁药、抗精神病药等神经调节剂的早期发现阶段。制药企业可利用其训练的计算模型快速筛选候选化合物,显著降低实验筛选成本。临床前研究中,预测模型有助于识别对特定5-HT受体亚型具有选择性的先导化合物,优化药物设计流程。
数据集最近研究
最新研究方向
近年来,5-HT受体配体结合亲和力预测已成为计算药物发现领域的关键研究方向之一。随着人工智能技术的快速发展,基于机器学习的方法在化合物活性预测方面展现出巨大潜力。该数据集作为专门针对5-羟色胺受体系统的生物活性数据集合,为开发新型抗抑郁药、抗精神病药物提供了重要研究基础。当前前沿研究主要集中在多模态分子表征学习、图神经网络架构优化以及迁移学习策略的应用上,旨在突破传统指纹方法在预测精度上的限制。与此同时,该领域与阿尔茨海默症、抑郁症等神经精神疾病的靶向药物研发热点密切相关,其研究成果将直接影响精准医疗时代下个性化治疗方案的设计。
以上内容由遇见数据集搜集并总结生成


