LFAI_RAG_qa_v1
收藏LFAI_RAG_qa_v1 数据集概述
数据集详情
LFAI_RAG_qa_v1 包含 36 个问题/答案/上下文条目,旨在用于支持 LLM-as-a-judge 的 RAG 评估。
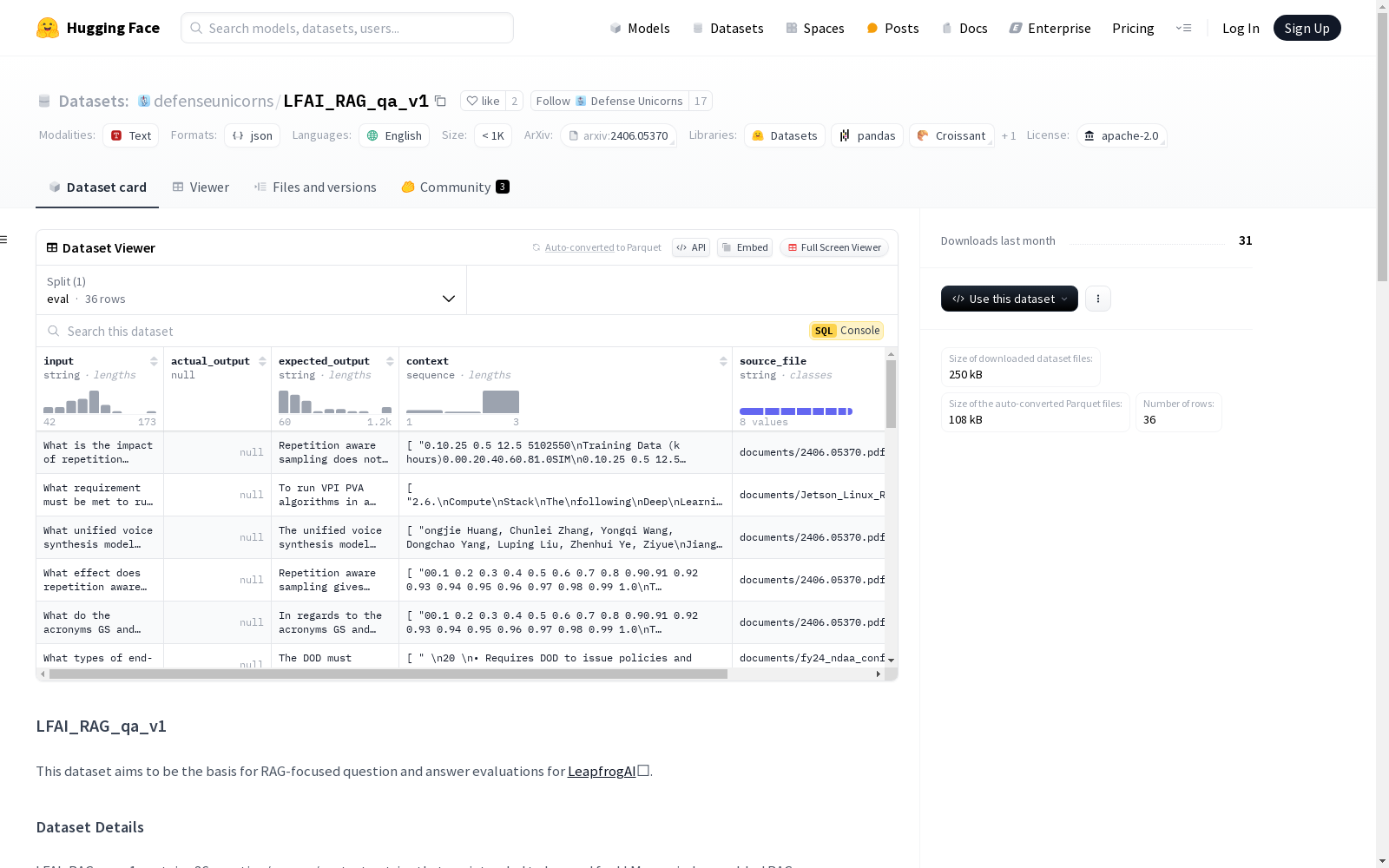
示例
json { "input": "What requirement must be met to run VPI PVA algorithms in a Docker container?", "actual_output": null, "expected_output": "To run VPI PVA algorithms in a Docker container, the same VPI version must be installed on the Docker host.", "context": [ "2.6. Compute Stack The following Deep Learning-related issues are noted in this release. Issue Description 4564075 To run VPI PVA algorithms in a docker container, the same VPI version has to be installed on the docker host. 2.7. Deepstream Issue Description 4325898 The pipeline gets stuck for multiu0000lesrc when using nvv4l2decoder. DS developers use the pipeline to run decode and infer jpeg images. NVIDIA Jetson Linux Release Notes RN_10698-r36.3 | 11" ], "source_file": "documents/Jetson_Linux_Release_Notes_r36.3.pdf" }
数据来源
数据来源于以下文档:
- https://www.humanesociety.org/sites/default/files/docs/HSUS_ACFS-2023.pdf
- https://www.whitehouse.gov/wp-content/uploads/2024/04/Global-Health-Security-Strategy-2024-1.pdf
- https://www.armed-services.senate.gov/imo/media/doc/fy24_ndaa_conference_executive_summary1.pdf
- https://dodcio.defense.gov/Portals/0/Documents/Library/(U)%202024-01-02%20DoD%20Cybersecurity%20Reciprocity%20Playbook.pdf
- https://assets.ctfassets.net/oggad6svuzkv/2pIQQWQXPpxiKjjmhfpyWf/eb17b3f3c9c21f7abb05e68c7b1f3fcd/2023_annual_report.pdf
- https://www.toyota.com/content/dam/toyota/brochures/pdf/2024/T-MMS-24Corolla.pdf
- https://docs.nvidia.com/jetson/archives/r36.3/ReleaseNotes/Jetson_Linux_Release_Notes_r36.3.pdf
- https://arxiv.org/pdf/2406.05370.pdf
文档本身可在 document_context.zip 中找到。
用途
该数据集已准备好用于 LLM-as-a-judge 评估,格式专门为与 DeepEval 兼容而设计。
数据集结构
数据集遵循 DeepEval 中 Test Case Goldens 的格式。
每个条目包含以下字段:
input:向 LLM 提出的问题expected_output:问题的标准答案context:包含或提供标准答案的文档来源
数据集创建
该数据集使用 DeepEval 的 Synthesizer 从源文档生成。
数据集经过以下精炼:
- 移除格式不佳或过于简单的问题条目
- 移除上下文中无意义的问题/答案对
- 修改问题以减少冗余并提高事实准确性
偏差、风险和限制
该数据集使用 GPT-4o 生成,因此带有模型和人工标注者的偏差。
数据集创建时使用的源文档不太可能出现在任何当前模型的训练数据中,但随着新模型的发布,这种情况可能会在几个月内发生变化。