ELAIPBENCH
收藏arXiv2025-10-12 更新2025-10-15 收录
下载链接:
https://huggingface.co/datasets/KangKang625/ELAIPBench
下载链接
链接失效反馈官方服务:
资源简介:
ELAIPBENCH是一个由领域专家精心策划的基准数据集,旨在评估大型语言模型(LLMs)对人工智能研究论文的理解能力。该数据集包含来自137篇论文的403个多项选择题,分为三个难度级别,强调非平凡的推理能力。数据集的创建过程采用了一种激励驱动的、对抗性的标注过程,以确保问题的难度和质量。实验表明,即使是表现最好的LLM,其准确率也只有39.95%,远低于人类的表现。这表明当前的LLM能力与真正理解学术论文之间存在着巨大的差距。
ELAIPBENCH is a benchmark dataset carefully curated by domain experts, designed to evaluate the ability of Large Language Models (LLMs) to comprehend artificial intelligence research papers. This dataset contains 403 multiple-choice questions sourced from 137 research papers, which are divided into three difficulty levels and emphasize non-trivial reasoning capabilities. The dataset was developed through an incentive-driven, adversarial annotation process to ensure the difficulty and quality of the questions. Experiments show that even the best-performing LLM achieves an accuracy of only 39.95%, which is far lower than human performance. This reveals a significant gap between the current capabilities of LLMs and genuine comprehension of academic research papers.
提供机构:
东南大学⋄Noah's Ark Lab
创建时间:
2025-10-12
原始信息汇总
ELAIPBench 数据集概述
数据集基本信息
- 许可证:MIT License
- 任务类别:问答、文本分类、文本检索
- 语言:英语
- 标签:学术、问题、证据、论文
- 规模:1K<n<10K
数据集描述
该数据集包含从研究论文中提取的学术问题及证据段落。每个问题都与源论文中的相关段落配对,为回答问题提供证据。该数据集被正式采用为CCKS 2025学术论文问答挑战赛的官方数据集。
数据集结构
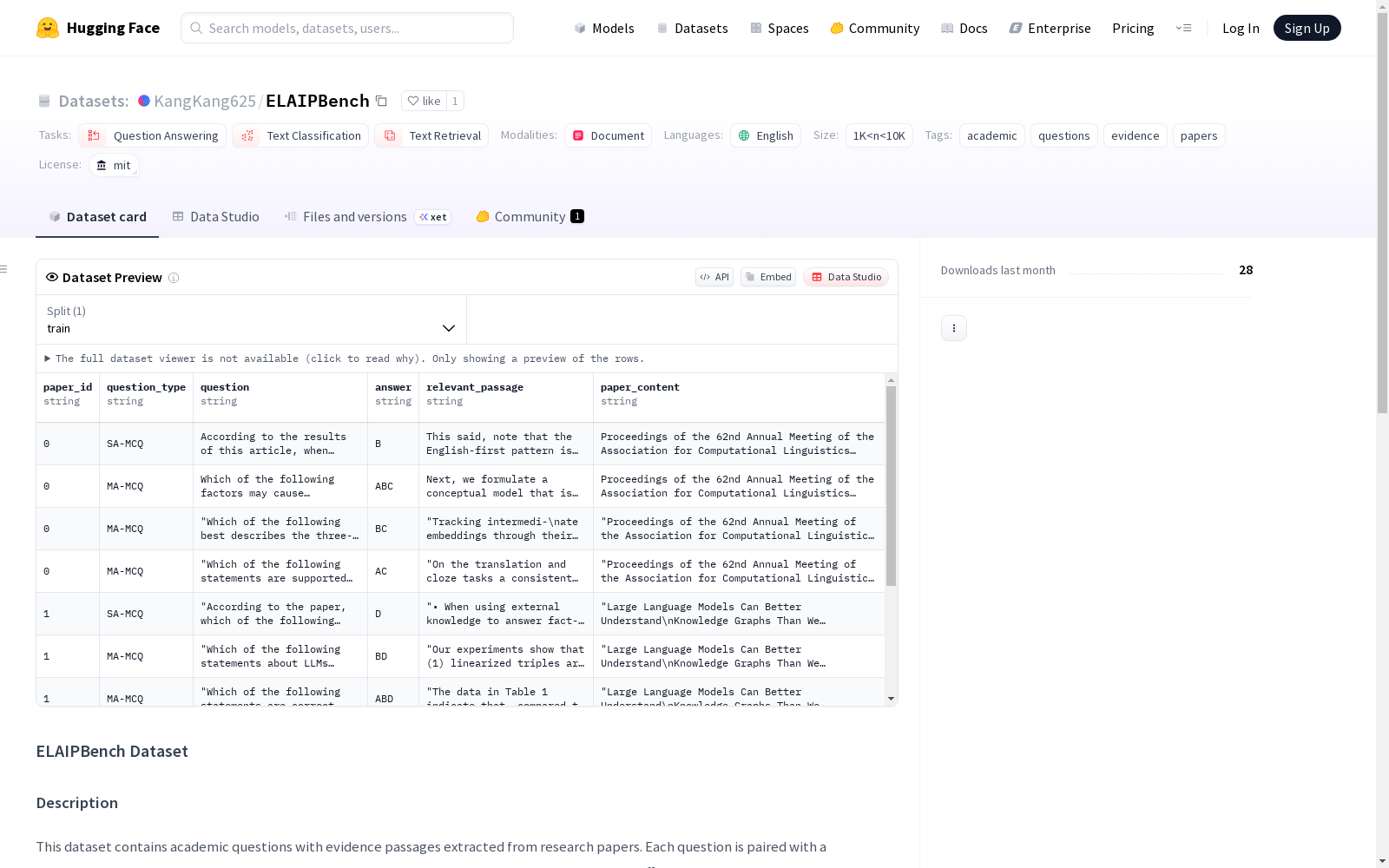
数据集包含403个问题,包含以下字段:
paper_id:源论文ID(对应papers.zip中的PDF文件名)question_type:问题类型(SA-MCQ、MA-MCQ等)question:问题文本answer:正确答案relevant_passage:从论文中提取的证据段落paper_content:源论文的全文内容
使用方法
python from datasets import load_dataset
加载数据集
dataset = load_dataset("KangKang625/ELAIPBench")
访问数据
data = dataset[test] print(f"问题数量: {len(data)}") print(f"第一个问题: {data[0][question]}") print(f"论文内容长度: {len(data[0][paper_content])}")
引用要求
使用该数据集时,请引用原始ELAIPBench论文。
搜集汇总
数据集介绍
构建方式
在人工智能领域学术理解评估体系尚不完善的背景下,ELAIPBENCH通过竞争性激励标注机制构建高质量数据集。该机制聘请20名具备硕士以上学历的计算机科学研究者,分别担任问题撰写者、证据验证者和答案验证者角色,形成三重质量把控流程。问题撰写者需基于完整学术论文设计需深度推理的多选题,经预筛选后由证据验证者确认答案可基于论文证据推导,最后由答案验证者在限定时间内独立答题以划分难度等级。这种对抗性设计结合基础薪酬与绩效奖金,有效激励标注者创作兼具挑战性与科学严谨性的问题。
特点
该数据集涵盖机器学习、计算机视觉和自然语言处理三大领域,包含403道经专家精心设计的多选题,具有显著的深度推理特性。题目设计严格规避表面信息检索,要求模型整合论文多章节信息并进行科学常识推理,其选项常包含具有误导性的部分真实陈述。数据集按难度分为三个层级,其中难度最高的问题占比达51.9%,人类专家在限时测试中仅达到48.14%准确率,而最优模型表现仅为39.95%,凸显其作为专家级评估基准的严格性。每个问题均配备完整原文、标准答案及证据摘录,确保评估过程的可靠性与可复现性。
使用方法
研究者可通过 Hugging Face 平台获取该数据集,在评估大型语言模型时需提供完整论文文本与对应问题。评估采用严格准确率指标:单选题要求完全匹配正确答案,多选题需完整识别所有正确选项。建议设置32k以上上下文窗口以容纳长篇论文,基础模型可采用温度参数0.1和32个新生成令牌的配置,思维链模式则需扩展至4096令牌以容纳推理过程。实验表明,传统检索增强生成与思维链提示在该数据集上均未带来显著提升,建议重点考察模型在证据 grounding 与多步推理方面的核心能力。
背景与挑战
背景概述
ELAIPBENCH作为2025年发布的专家级人工智能论文理解基准数据集,由东南大学与诺亚方舟实验室联合开发,旨在填补大语言模型对学术论文深度理解能力的评估空白。该数据集聚焦于机器学习、计算机视觉和自然语言处理三大领域,通过竞争性激励标注机制构建了403道多选题目,涵盖三个难度层级,强调非表面推理与证据支持。其创新性在于采用对抗性标注流程,确保问题质量与挑战性,推动了学术文本理解评估向精细化、可靠化发展,为AI研究社区提供了关键基准工具。
当前挑战
ELAIPBENCH核心挑战在于解决学术论文深度理解这一复杂问题,要求模型超越浅层检索,实现跨段落推理与知识整合。构建过程中面临多重困难:一是高质量标注依赖领域专家,导致成本高昂且周期漫长;二是设计对抗性题目需平衡难度与可解答性,避免模型依赖记忆或简单匹配;三是评估中发现现有增强方法(如思维链或检索增强)反而引发推理瘫痪或噪声干扰,突显了当前技术与人类专家级理解间的显著差距。
常用场景
经典使用场景
在人工智能学术研究领域,ELAIPBENCH作为专业评估工具,被广泛用于测试大型语言模型对完整学术论文的深度理解能力。其经典应用场景包括模型在无外部知识干扰下,基于论文原文进行多轮推理判断,尤其擅长检验模型对隐含逻辑关系和跨段落信息整合的掌握程度。该数据集通过精心设计的对抗性标注机制,有效规避了传统评测中常见的表面匹配现象,为衡量模型真实学术素养提供了标准化环境。
解决学术问题
该数据集主要解决了当前自然语言处理领域对学术文本深度理解能力评估不足的核心问题。通过构建具有三个难度层级的多选题体系,有效区分了模型的浅层检索与深层推理能力,填补了现有基准在衡量复杂学术推理任务上的空白。其实验结果揭示了当前大模型在理解长篇学术文献时存在的推理瘫痪现象,为改进模型架构和训练策略提供了关键实证依据,推动了学术文本理解研究向更精细化方向发展。
衍生相关工作
基于ELAIPBENCH的评估范式,衍生出多项具有影响力的研究工作。其中最具代表性的是针对推理增强型大模型的深度分析,系统揭示了思维链机制在学术场景中的局限性。后续研究进一步探索了多模态学术理解基准的构建方法,并发展了基于对抗验证的自动题目生成技术。这些衍生工作共同推动了学术机器理解研究从表层匹配向深度推理的范式转变。
以上内容由遇见数据集搜集并总结生成


