russian-simple-vacancies-filtered
收藏Hugging Face2026-05-03 更新2026-05-04 收录
下载链接:
https://huggingface.co/datasets/browther/russian-simple-vacancies-filtered
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为俄罗斯简单职位—高参与度潜在客户生成(筛选版),专为快速、低摩擦的零工经济物流职位目标定位而设计。数据集经过严格筛选,保留了入门级、紧急、简单的任务和零工形式的职位,剔除了工程师、医生、律师和企业职位等不符合条件的记录。最终数据集包含91条记录,来源于avito.ru、hh.ru(AlekseyScorpi)和trudvsem.ru。数据集中包含21个字段,包括原始字段和三个新增的过滤输出字段(engagement_logic、engagement_score和conversion_potential)。数据集还详细记录了参与度评分分布和转化潜力,以及高频出现的参与模式(如по договорённости、звоните等)。此外,README还提供了扩展数据集的方法,包括通过HH.ru API、Avito或自定义JSONL文件进行数据采集和过滤。
The dataset is named Russian Simple Vacancies — Filtered (High-Engagement Lead Gen) and is designed for quick, low-friction targeting of gig economy logistics positions. The dataset has been rigorously filtered to retain entry-level, urgent, simple tasks and gig-style positions, while excluding records that do not meet the criteria, such as engineers, doctors, lawyers, and corporate positions. The final dataset contains 91 records sourced from avito.ru, hh.ru (AlekseyScorpi), and trudvsem.ru. It includes 21 fields, comprising original fields and three newly added filtered output fields (engagement_logic, engagement_score, and conversion_potential). The dataset also details engagement score distributions and conversion potential, as well as frequently occurring engagement patterns (e.g., по договорённости, звоните). Additionally, the README provides methods for expanding the dataset, including data collection and filtering via the HH.ru API, Avito, or custom JSONL files.
创建时间:
2026-05-02
原始信息汇总
数据集概述:Russian Simple Vacancies — Filtered (High-Engagement Lead Gen)
数据集简介
该数据集是面向零工经济物流领域的高参与度、低摩擦职位空缺的筛选数据集,原始数据经过多阶段过滤后,从 16,242 条记录精简至 91 条。
数据来源与分布
最终数据集包含来自三个俄罗斯招聘平台的记录:
- avito.ru:49 条
- hh.ru(来自 AlekseyScorpi):30 条
- trudvsem.ru:12 条
筛选流程(4 阶段)
| 阶段 | 过滤条件 | 移除记录数 | 剩余记录数 |
|---|---|---|---|
| Stage 0 | 移除 /worker/ 个人简历(非职位) |
2,680 | 13,562 |
| Stage 1 | 保留低摩擦职位(入门级、紧急任务、简单任务、零工格式);排除工程师、医生、律师、企业职位 | 2,671 | 10,891 |
| Stage 2 | 要求显式对话行动号召(地址隐藏、“请致电我们”、“по договорённости”) | 10,787 | 104 |
| Stage 3 | 仅保留安全领域(物流、仓储、配送、服务) | 13 | 91 |
参与度评分分布
评分基于对话触发机制的匹配情况(主要触发+1分,次要触发+0.5分,反触发-1分):
| 评分 | 记录数 | 含义 |
|---|---|---|
| 2.5 | 1 | 最高——多个对话触发点 |
| 2.0 | 3 | 高——2个以上强制联系钩子 |
| 1.5 | 34 | 中等——主要+次要钩子 |
| 1.0 | 53 | 最低——1个钩子存在 |
转化潜力分级
| 级别 | 记录数 |
|---|---|
| 高(评分 ≥ 2.0) | 4 |
| 中等(评分 1.5) | 34 |
| 低-中等(评分 1.0) | 53 |
数据集架构(21 列)
包含所有原始列 + 3 个新筛选输出列:
engagement_logic:匹配的钩子类型及评分细则engagement_score:数值评分(主要=1分,次要=0.5分,反触发=-1分)conversion_potential:高 / 中等 / 低-中等
关键参与模式
| 模式 | 频率(约) | 机制 |
|---|---|---|
по договорённости(可协商) |
~70/91 | 薪资/时间可讨论→强制对话 |
звоните / свяжитесь(请致电/联系) |
~15/91 | 显式行动号召 |
уточним по телефону/в чате(电话/聊天确认) |
~10/91 | 隐藏细节→必须联系 |
| 地址无门牌号 | ~25/91 | 需澄清地址 |
по согласованию(时间待协商) |
~8/91 | 需协调时间 |
搜集汇总
数据集介绍
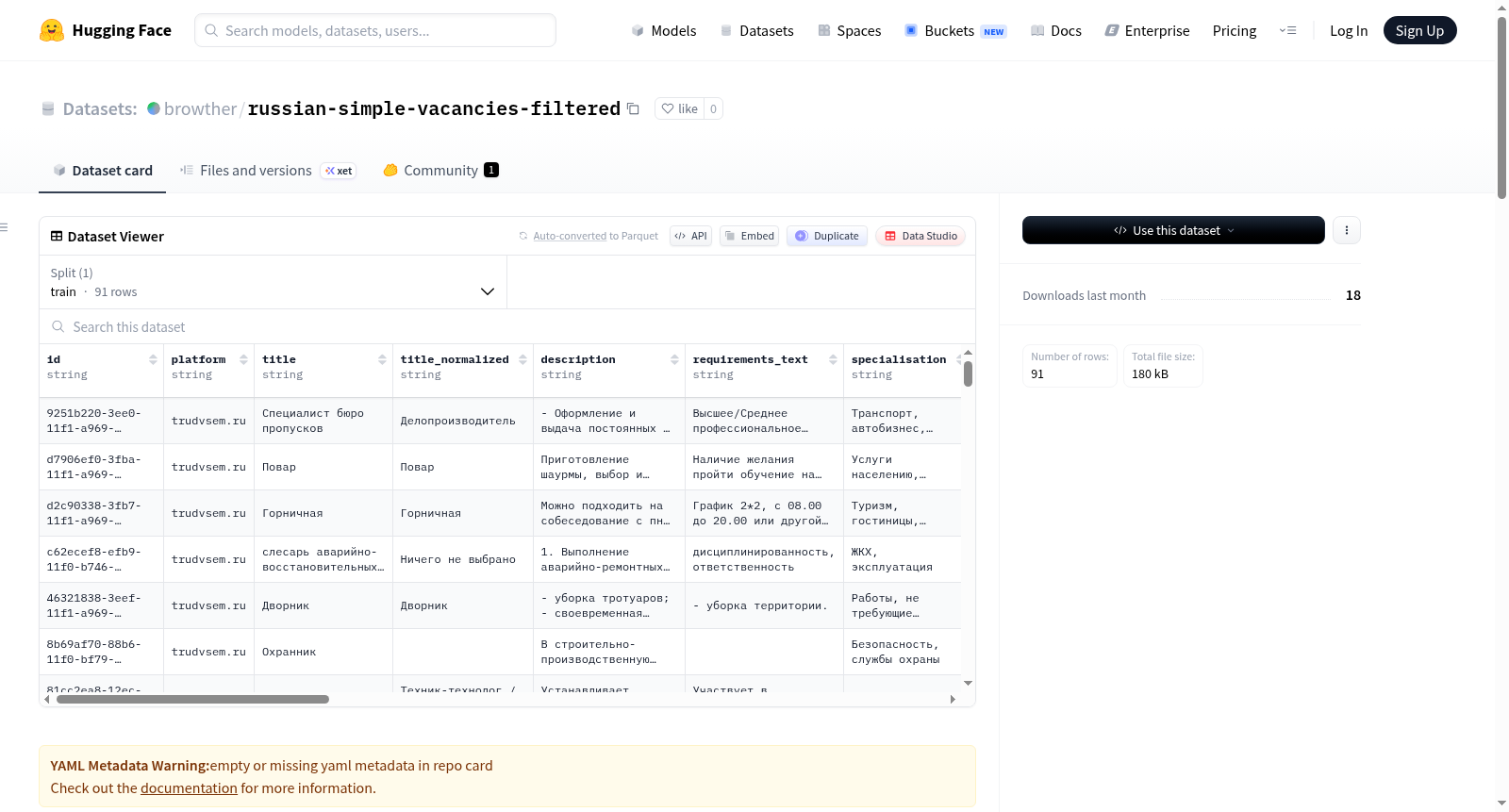
构建方式
本数据集源自俄罗斯主流招聘平台avito.ru、hh.ru及trudvsem.ru上收集的原始空缺职位数据,初始包含16,242条记录。为服务于零工经济物流领域的高效低摩擦用户触达任务,研究者设计了一套四阶段过滤流水线:首先剔除简历类内容,保留纯职位数据;其次筛选低摩擦岗位,移除高资质职业;再次保留高参与度职位,这些职位需包含明确对话触发标记,如联系人信息或薪资协商提示;最后仅保留合规安全类别,将范围限定于物流、仓储、配送和服务行业。经过层层精简,最终获得91条高质量记录。
特点
该数据集的核心特点在于其独特的高参与度评分机制,通过分析职位描述中的对话触发模式,为每条记录赋予一个从1.0到2.5的参与度得分。评分系统识别主要触发点(如“по договорённости”约定薪资)计1分,次要触发点(如“звоните请致电”)计0.5分,并根据转化潜力划分为高、中、低三个等级。数据集还包含21个字段,其中新增了engagement_logic、engagement_score和conversion_potential三个输出列,详细记录了匹配的钩子类型、详细评分及转化潜力评估,为高成效用户引导提供精准依据。
使用方法
用户可通过三种途径扩展此数据集:使用HH.ru的免费API,设置访问令牌后运行爬虫脚本获取原始JSONL文件,再通过过滤流水线生成最终数据集;针对Avito平台,需配合代理服务器绕过反爬机制进行数据收集;或直接准备包含标题、描述和可选URL的JSONL文件,投入过滤流水线处理。所有操作均通过Python脚本实现,支持命令行参数配置,包括代理设置及向HuggingFace仓库推送结果,便于在零工经济场景中快速构建高参与度职位数据库。
背景与挑战
背景概述
在零工经济与物流行业迅猛发展的背景下,如何高效筛选出具备高转化潜力的低摩擦招聘信息,成为人力资源领域的一项关键挑战。russian-simple-vacancies-filtered数据集由研究团队于近期创建,其核心研究问题聚焦于从海量俄语招聘信息中,通过多层次过滤与对话参与度评分,精准定位适合简单任务和紧急岗位的优质线索。该数据集融合了来自avito.ru、hh.ru及trudvsem.ru三大平台的数据,最终形成91条高度精选的记录,对于提升招聘匹配效率、降低沟通成本具有重要的实践意义,尤其在高速度低摩擦的零工匹配场景中展现了突出的应用价值。
当前挑战
该数据集所解决的领域问题在于,传统招聘信息过于泛化,无法有效甄别那些迫切需要简单劳动力且激励应聘者主动发起对话的高潜力职位,导致匹配效率低下。构建过程中,团队面临多重挑战:首先是从原始16,242条记录中,剔除简历类内容并过滤掉工程师、医生等复杂职业,仅保留入门级和紧急的零工任务,这要求精确定义“低摩擦”标准;其次,设计高参与度过滤机制,通过识别“по договорённости”等明确对话触发模式,并从地址不完整等隐性线索中判断沟通必要性,极大地增加了数据标注与评分规则制定的复杂度;最后,还需确保合规安全,仅保留物流、仓储等安全领域,从而在极低留存率下(0.56%)实现高质量数据集的构建。
常用场景
经典使用场景
在零工经济与低技能劳动力市场的交叉领域中,russian-simple-vacancies-filtered数据集被精心设计为一种面向高参与度线索生成的筛选工具。该数据集从初始的16,242条原始职位记录出发,经过多阶段精细过滤,最终保留91条高度契合特定场景的样本,其核心目标在于识别和提取那些具备低摩擦、高转化潜力的简单职位空缺。经典用法聚焦于训练和评估用于自动检测高参与度招聘信息的模型,这些信息通常包含明确的行为召唤(如“请致电”、“商议薪资”)或隐含的对话触发点(如地址不完整、时间协调需求),从而模拟人力资源系统在快速匹配零工经济劳动力需求时的决策逻辑。
实际应用
在实际应用中,该数据集为俄罗斯零工经济平台(如物流、仓储、配送及服务行业)的招聘系统提供了精准引流解决方案。通过集成其过滤流水线,企业能够从Avito、HH.ru及Trudvsem.ru等来源的原始职位流中快速提取出那些最可能引发求职者主动联系的岗位。具体场景包括:自动筛选出标有“工资面议”的配送员或仓库工人职位,并优先推送给活跃求职者;在聊天机器人或招聘助手后台,利用参与度评分标记需要人工干预的高转化潜力线索,从而减少客服与候选人的无效沟通成本。这套方法在简易任务类用工领域实现了从流量到线索的高效转化,显著提升了匹配效率。
衍生相关工作
围绕russian-simple-vacancies-filtered数据集,衍生了一系列探索招聘意图识别与低摩擦转化建模的前沿工作。例如,研究者基于该数据集的参与度评分体系,开发了用于预测职位描述中对话触发点(如地址隐藏、时间协商)的多标签分类模型,并在真实招聘广告上验证了其迁移能力。此外,有工作借鉴其过滤流水线的多阶段设计,在乌克兰、哈萨克斯坦等邻国的招聘平台数据上复刻了类似的高参与度线索识别流程,推动了跨语言语境下零工经济敏捷匹配框架的泛化研究。这些衍生成果不仅深化了对“行为召唤”特征在简易职位中作用机制的理解,也启发了从劳动力供给端优化信息呈现策略的系统性思考。
以上内容由遇见数据集搜集并总结生成


