Simonlob/Kany_dataset_mk4_Base
收藏Hugging Face2024-06-05 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/Simonlob/Kany_dataset_mk4_Base
下载链接
链接失效反馈官方服务:
资源简介:
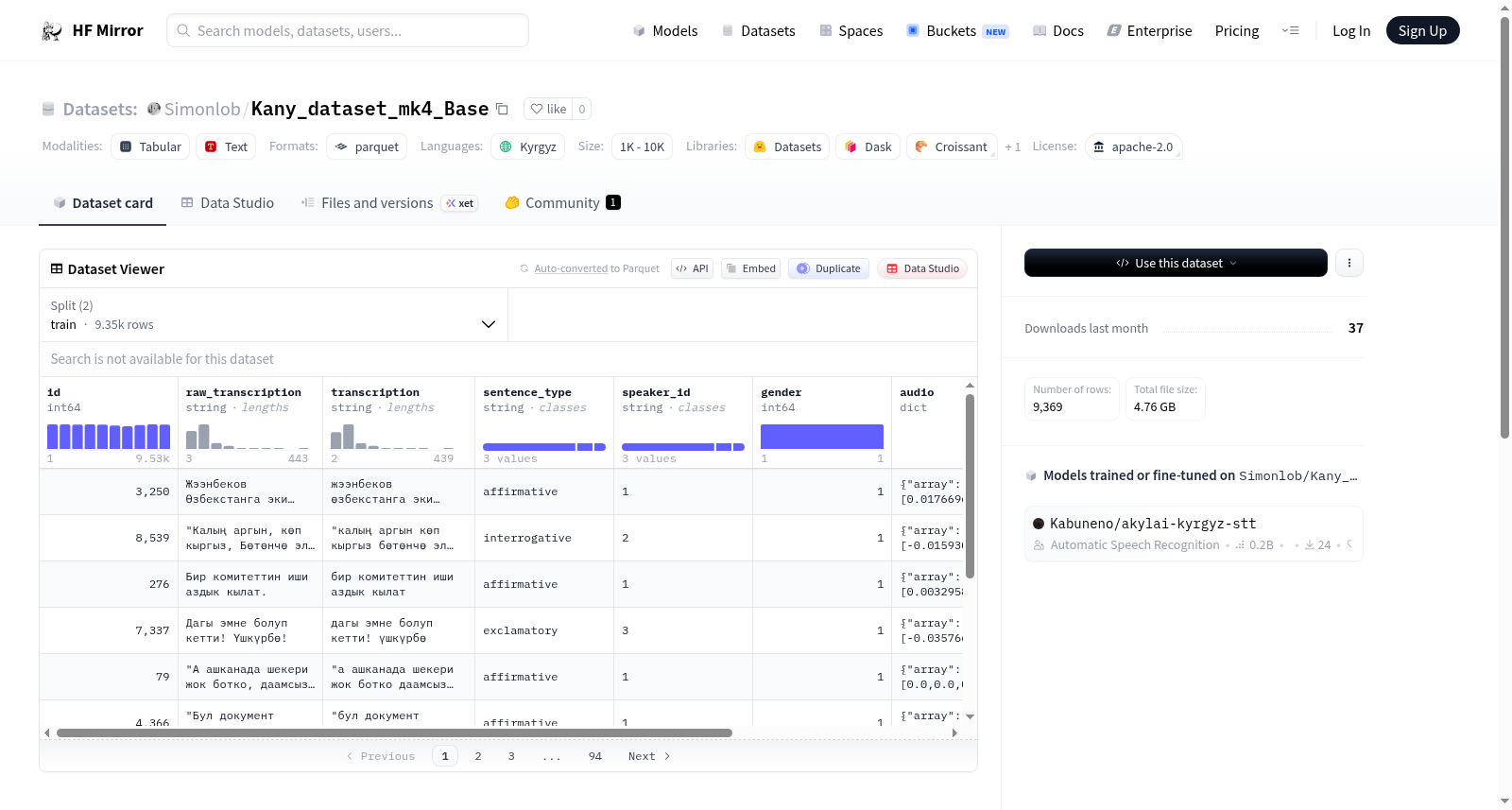
该数据集包含约7000个样本,采样率为44100 Hz,格式为float32,总语音时长为13小时。数据集的特征包括句子编号、原始文本、清理后的文本、句子类型、说话者ID、性别和音频数据。音频数据以字典形式呈现,包含采样率和音频数组等元数据。说话者为Kanykey Bakashova。数据集分为训练集和测试集,训练集包含9349个样本,测试集包含20个样本。
该数据集包含约7000个样本,采样率为44100 Hz,格式为float32,总语音时长为13小时。数据集的特征包括句子编号、原始文本、清理后的文本、句子类型、说话者ID、性别和音频数据。音频数据以字典形式呈现,包含采样率和音频数组等元数据。说话者为Kanykey Bakashova。数据集分为训练集和测试集,训练集包含9349个样本,测试集包含20个样本。
提供机构:
Simonlob
原始信息汇总
数据集概述
数据集特征
- id: 整数类型,句子编号。
- raw_transcription: 字符串类型,句子的文本。
- transcription: 字符串类型,小写文本,已清除标点符号。
- sentence_type: 字符串类型,句子类别(陈述句、疑问句、感叹句)。
- speaker_id: 字符串类型,说话者ID,始终为"1"。
- gender: 整数类型,说话者的性别,始终为"1"。
- audio: 结构体类型,包含以下子特征:
- array: 序列类型,浮点32位,音频数据。
- path: 字符串类型,音频文件路径。
- sampling_rate: 整数类型,采样率。
数据集分割
- train: 训练集,包含9349个样本,总大小为10662278090.528124字节。
- test: 测试集,包含20个样本,总大小为22809451.471875332字节。
数据集大小
- 下载大小: 4756967964字节
- 数据集总大小: 10685087542字节
配置文件
- config_name: default
- data_files:
- split: train, path: data/train-*
- split: test, path: data/test-*
许可
- 许可证: apache-2.0
语言
- 语言: ky (Kyrgyz)
搜集汇总
数据集介绍
背景与挑战
背景概述
这是一个吉尔吉斯语语音文本数据集,包含约9,369条样本,总语音时长约13小时,音频采样率为44100 Hz,录音质量高。数据集提供了原始转录文本、清理后文本、句子类型(如陈述句、疑问句、感叹句)和音频数据等特征,专门用于语音处理任务,说话人为Kanykey Bakashova。
以上内容由遇见数据集搜集并总结生成


