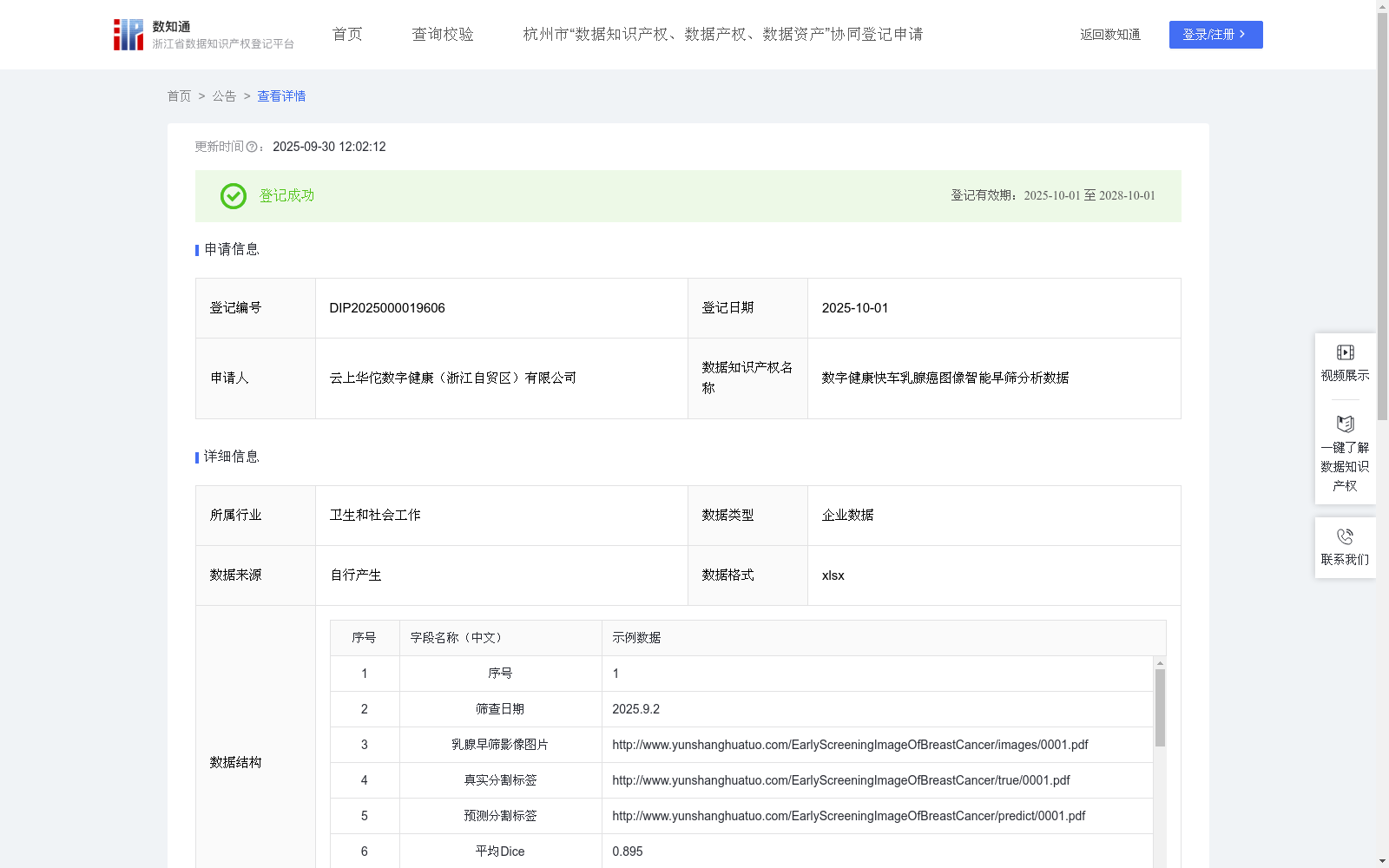
数字健康快车乳腺癌图像智能早筛分析数据
收藏资源简介:
一、适用条件与范围 条件:具备乳腺影像采集设备的医疗机构。 范围:成年女性乳腺癌早期筛查,尤其适用于医疗资源匮乏地区。 对象:基层医生、影像科医师、体检中心。 二、解决的核心问题 (1)筛查效率低:传统人工阅片耗时长,基层医生经验不足易漏诊。 (2)病灶量化难:病灶位置、形态、动态变化等特征需专业影像分析能力。 三、数据应用价值 智能分割病灶:微调SAM模型自动输出高精度乳腺早筛分割标签(平均Dice/IoU验证),标识病灶位置与范围。 多维特征融合:结合位置(距乳头距离)、空间(形态属性)、对比(与周围组织差异)等特征,生成结构化报告。 辅助诊断决策:为医生提供可视化病灶分析及风险评估依据,提升筛查敏感性与特异性。 四、外部复用价值 赋能基层医疗:降低对专家资源的依赖,缩短诊断周期(单次筛查分钟级完成)。 标准化输出:算法适配各类乳腺影像设备,推动筛查结果跨机构互认。一、数据采集 通过智能早筛数字健康快车,采集双侧乳腺(左侧L/右侧R)的早筛影像图片,收集影像相关的结构化特征信息。 核心字段: 乳腺早筛影像图片:通过URL存储乳腺早筛影像图片(URL链接已脱敏) 真实分割标签 预测分割标签 平均Dice 平均IoU 位置特征(左/右):量化病灶与乳头距离。 空间特征(左/右):描述形态属性。 时间特征(左/右):记录单次筛查的动力学变化。 对比特征(左/右):病灶与周围组织差异。 乳腺区域描述(左/右):含生物标记物信息。 辅助字段: 临床数据、图像数据、医生诊断结论用于人工复核。筛查日期用于数据管理。 二、数据处理 对所有乳腺早筛影像图片进行标准化预处理,确保输入一致性,包括:图像尺寸归一化、图像去噪处理、亮度与对比度调整。 目标:提升后续算法模型的鲁棒性和分割精度。 三、核心算法规则 (模型构建与训练) (1)采用预训练的视觉大模型 SAM (Segment Anything Model) 作为基础架构。 (2)使用采集的乳腺早筛影像图片,对SAM模型进行微调。 (3)输入预处理后的乳腺早筛影像图片,输出该图片上乳腺肿瘤区域的预测分割标签 (P)。核心映射关系表示为:P = f_θ(I),其中: f_θ代表微调后的SAM模型,参数为θ。 I代表输入的预处理乳腺早筛影像图片。 P代表模型预测的分割标签图。 性能评估:在训练和验证阶段,使用平均Dice系数和平均IoU作为核心指标,量化模型预测分割标签结果与真实分割标签之间的重叠精度。 四、数据应用 应用微调训练好的模型对新的乳腺早筛影像进行自动肿瘤区域分割。 输出的预测分割标签 P 用于标识乳腺早筛影像中可疑病灶的位置和范围。 结合预测分割标签的结果与原始影像特征(位置、空间、时间、对比特征),为后续的病灶分析、风险评估及辅助诊断提供关键依据。
1. Applicable Conditions and Scope Conditions: Medical institutions equipped with breast imaging acquisition equipment. Scope: Early breast cancer screening for adult females, especially suitable for areas with scarce medical resources. Target Users: Primary care physicians, radiologists, and physical examination centers. 2. Core Problems Solved (1) Low Screening Efficiency: Traditional manual film reading is time-consuming, and primary care physicians with insufficient experience are prone to missed diagnoses. (2) Difficulty in Quantifying Lesions: Features such as lesion location, morphology, and dynamic changes require professional medical image analysis capabilities. 3. Data Application Value Intelligent Lesion Segmentation: Fine-tune the SAM model to automatically output high-precision breast cancer early screening segmentation labels (verified by average Dice/IoU), marking the location and scope of lesions. Multi-dimensional Feature Fusion: Combine features such as location (distance from the nipple), spatial (morphological attributes), and contrast (difference from surrounding tissues) to generate structured reports. Auxiliary Diagnosis Decision-making: Provide doctors with visual lesion analysis and risk assessment basis, improving the sensitivity and specificity of screening. 4. External Reusability Value Empower Primary Care Healthcare: Reduce dependence on expert resources and shorten the diagnosis cycle (completed in minutes per screening). Standardized Output: The algorithm is compatible with various breast imaging equipment, promoting cross-institutional mutual recognition of screening results. 1. Data Collection Collect early screening images of bilateral breasts (left L/right R) via the intelligent early screening digital health express, and collect structured feature information related to the images. Core Fields: - Breast early screening images: Stored via URLs (URL links have been desensitized) - Ground-truth segmentation labels - Predicted segmentation labels - Average Dice coefficient - Average Intersection over Union (IoU) - Location feature (left/right): Quantify the distance between the lesion and the nipple. - Spatial feature (left/right): Describe morphological attributes. - Temporal feature (left/right): Record dynamic changes of a single screening. - Contrast feature (left/right): Difference between the lesion and surrounding tissues. - Breast region description (left/right): Contains biomarker information. Auxiliary Fields: - Clinical data, image data, and doctor's diagnosis conclusions are used for manual review. - Screening date is used for data management. 2. Data Processing Perform standardized preprocessing on all breast early screening images to ensure input consistency, including: image size normalization, image denoising, brightness and contrast adjustment. Objective: Improve the robustness and segmentation accuracy of subsequent algorithm models. 3. Core Algorithm Rules (Model Construction and Training) (1) Adopt the pre-trained visual large model SAM (Segment Anything Model) as the basic architecture. (2) Fine-tune the SAM model using the collected breast early screening images. (3) Input the preprocessed breast early screening images, and output the predicted segmentation label (P) of the breast tumor region on the image. The core mapping relationship is expressed as: P = f_theta(I), where: - f_theta represents the fine-tuned SAM model with parameter theta. - I represents the input preprocessed breast early screening image. - P represents the model's predicted segmentation label map. Performance Evaluation: In the training and validation stages, use the average Dice coefficient and average IoU as core indicators to quantify the overlap accuracy between the model's predicted segmentation labels and the ground-truth segmentation labels. 4. Data Application Apply the fine-tuned trained model to automatically segment tumor regions on new breast early screening images. The output predicted segmentation label P is used to identify the location and scope of suspicious lesions in breast early screening images. Combine the results of the predicted segmentation labels and the original image features (location, spatial, temporal, contrast features) to provide key basis for subsequent lesion analysis, risk assessment and auxiliary diagnosis.