QuantiPhy
收藏QuantiPhy (Validation Set) 数据集概述
数据集简介
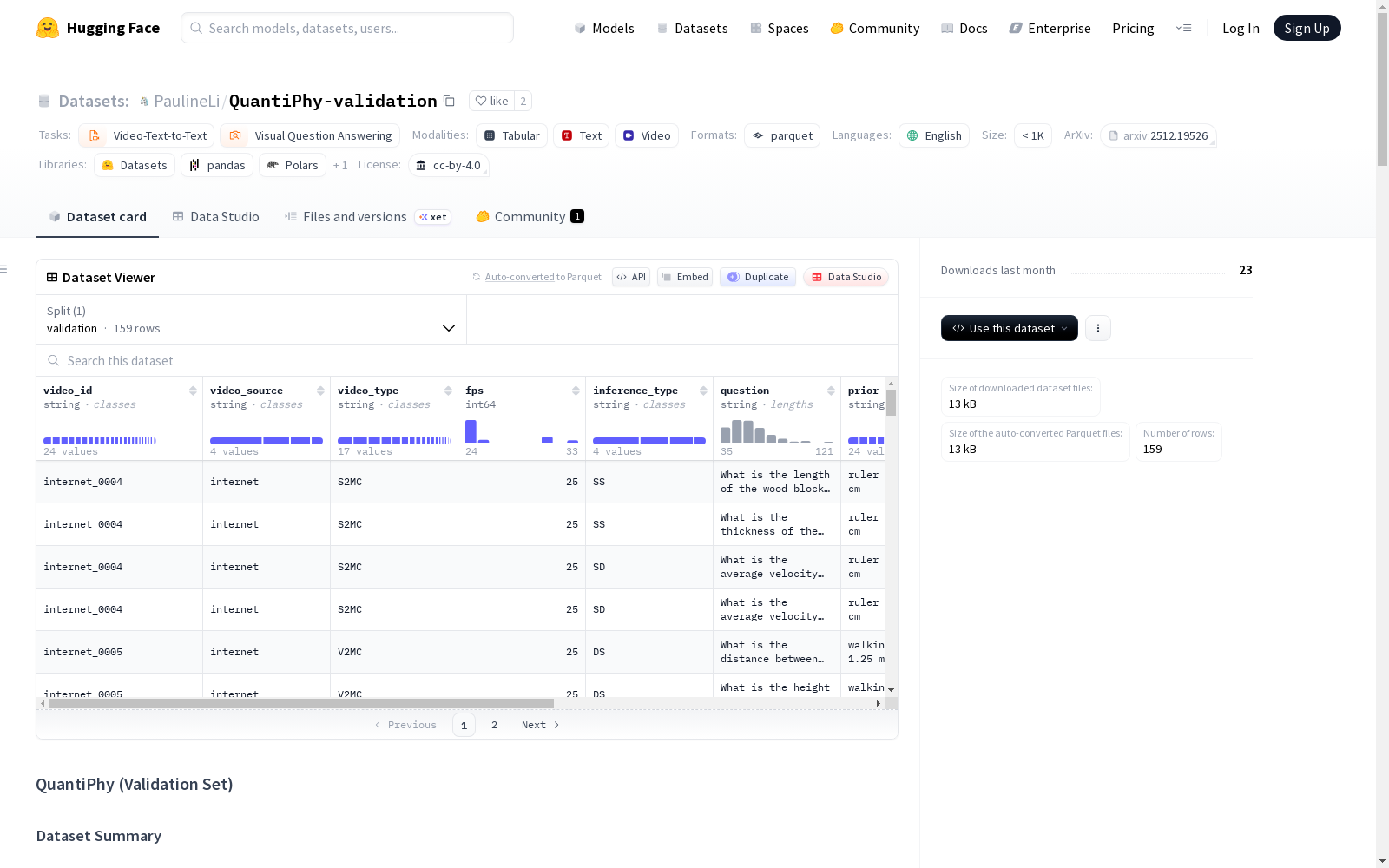
QuantiPhy 是一个用于评估视觉-语言模型是否能从视觉证据进行定量物理推理的基准,而非产生看似合理但无根据的数值猜测。本仓库包含 QuantiPhy 的官方验证集,用于支持模型开发、消融研究和初步评估。该验证集约占完整基准的4%,包含 159 个视频-问题-答案对。每个实例要求模型在给定一个短视频和一个自然语言问题后,输出一个单一的连续数值(例如,物体大小、速度或加速度),单位为真实世界单位。
预期用途
此验证集旨在用于:
- 模型调试和提示词开发
- 超参数调优
- 消融和错误分析
- 在完整基准评估前的完整性检查 它不应用作完整 QuantiPhy 基准的替代品。完整数据集(包括训练和测试分割)将另行发布。
支持的任务
- 基于视频的数值回归
- 定量视觉推理
- 视觉-语言模型评估 任务涵盖三个核心运动学属性:
- 大小
- 速度
- 加速度 所有问题均为开放式,需要预测一个实值标量。
数据集结构
每个实例表示为一个结构化的视频-文本记录,包含以下字段:
| 字段 | 描述 |
|---|---|
video_id |
视频的唯一标识符 |
video_source |
数据来源 (simulation, lab, 或 internet) |
video_type |
编码任务配置的四字符代码 |
fps |
视频的帧率 |
inference_type |
静态或动态的先验/目标配置 |
question |
带有明确物理单位的自然语言问题 |
prior |
以世界单位提供的物理先验(例如,物体大小、速度或加速度) |
depth_info |
3D 配置的深度/距离信息(如适用) |
answer |
真实数值(浮点数,真实世界单位) |
视频较短(通常 2–3 秒),并使用静态摄像机录制,以确保运动学推理定义明确。
任务设计概述
每个实例为模型提供:
- 一个描绘物体运动的短视频
- 一个物理先验(以世界单位表示,如物体大小、特定时间戳的速度或加速度) 模型随后被要求推断一个目标运动学量(可能针对不同物体),并以真实世界单位表示。
任务在四个维度上变化:
- 物理先验:大小 (S)、速度 (V)、加速度 (A)
- 维度:2D(平面运动)或 3D(具有深度变化)
- 物体设置:单物体 (S) 或多物体 (M)
- 背景复杂度:简单 (X)、简单 (S)、复杂 (C)
验证集统计信息
- 159 个 QA 对
- 涵盖所有三种物理先验 (S / V / A)
- 包括 2D 和 3D 配置
- 视频来源:
- Blender 模拟
- 实验室捕获
- 精选的互联网视频 此子集旨在相对于完整基准具有代表性但非穷尽性。
数据来源与质量控制
- 模拟:使用精确物理真实值的 Blender 渲染场景。
- 实验室捕获:使用校准深度和多视角设置的真实世界录制。
- 互联网/作者录制视频:经过精心筛选、满足严格物理约束的单目视频。 所有视频都经过人工审查,以移除:
- 过度运动模糊
- 严重遮挡
- 无法追踪的运动
- 个人身份信息
许可协议
本仓库中的标注和元数据根据 Creative Commons Attribution 4.0 (CC BY 4.0) 许可发布。 视频来源于模拟环境、实验室录制和公开可用的资源。每个视频仍受其原始许可和使用条款约束。 此发布旨在用于研究和评估目的。
作者
Puyin Li*, Tiange Xiang*, Ella Mao*, Shirley Wei, Xinye Chen, Adnan Masood, Li Fei-Fei†, Ehsan Adeli†
- 同等贡献。
引用
如果您在您的工作中使用此验证集,请引用: bibtex @article{li2025quantiphy, title = {QuantiPhy: A Quantitative Benchmark Evaluating Physical Reasoning Abilities of Vision-Language Models}, author = {Li, Puyin and Xiang, Tiange and Mao, Ella and Wei, Shirley and Chen, Xinye and Masood, Adnan and Li, Fei-Fei and Adeli, Ehsan}, journal = {arXiv preprint arXiv:2512.19526}, year = {2025} }