ASR_TEDx_Tunisie
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/KBayoud/ASR_TEDx_Tunisie
下载链接
链接失效反馈官方服务:
资源简介:
TEDxTN是一个用于代码切换的突尼斯阿拉伯语-英语的三向语音翻译语料库。该数据集包含突尼斯阿拉伯方言的音频片段及其转录文本,适用于自动语音识别和翻译任务。数据集特征包括16kHz的WAV音频片段、对应的转录文本、原始YouTube视频URL以及片段的时间戳信息。数据集由Fethi Bougares等人整理,采用CC BY-NC-ND 4.0许可协议,包含训练集、验证集和测试集。
TEDxTN is a three-way speech translation corpus focused on code-switching between Tunisian Arabic and English. This dataset comprises audio clips of Tunisian Arabic dialect and their corresponding transcriptions, tailored for automatic speech recognition and machine translation tasks. The dataset features 16kHz WAV audio clips, their aligned transcriptions, original YouTube video URLs, and timestamp information for each clip. It was curated by Fethi Bougares et al., released under the CC BY-NC-ND 4.0 license, and includes training, validation, and test splits.
创建时间:
2025-12-12
原始信息汇总
数据集概述
基本信息
- 数据集名称:TEDxTN
- 维护者:Fethi Bougares
- 许可协议:CC BY-NC-ND 4.0
- 主要任务类别:自动语音识别(Automatic-Speech-Recognition)
- 语言:突尼斯阿拉伯语(Tunisian Arabic)
- 标签:Tunisian, dialect, Arabic, ASR, Speech, Translation
- 数据规模:1M < n < 10M
数据集结构
配置与文件
- 默认配置名称:default
- 数据文件划分:
- 训练集:
data/train-* - 验证集:
data/validation-* - 测试集:
data/test-*
- 训练集:
特征字段
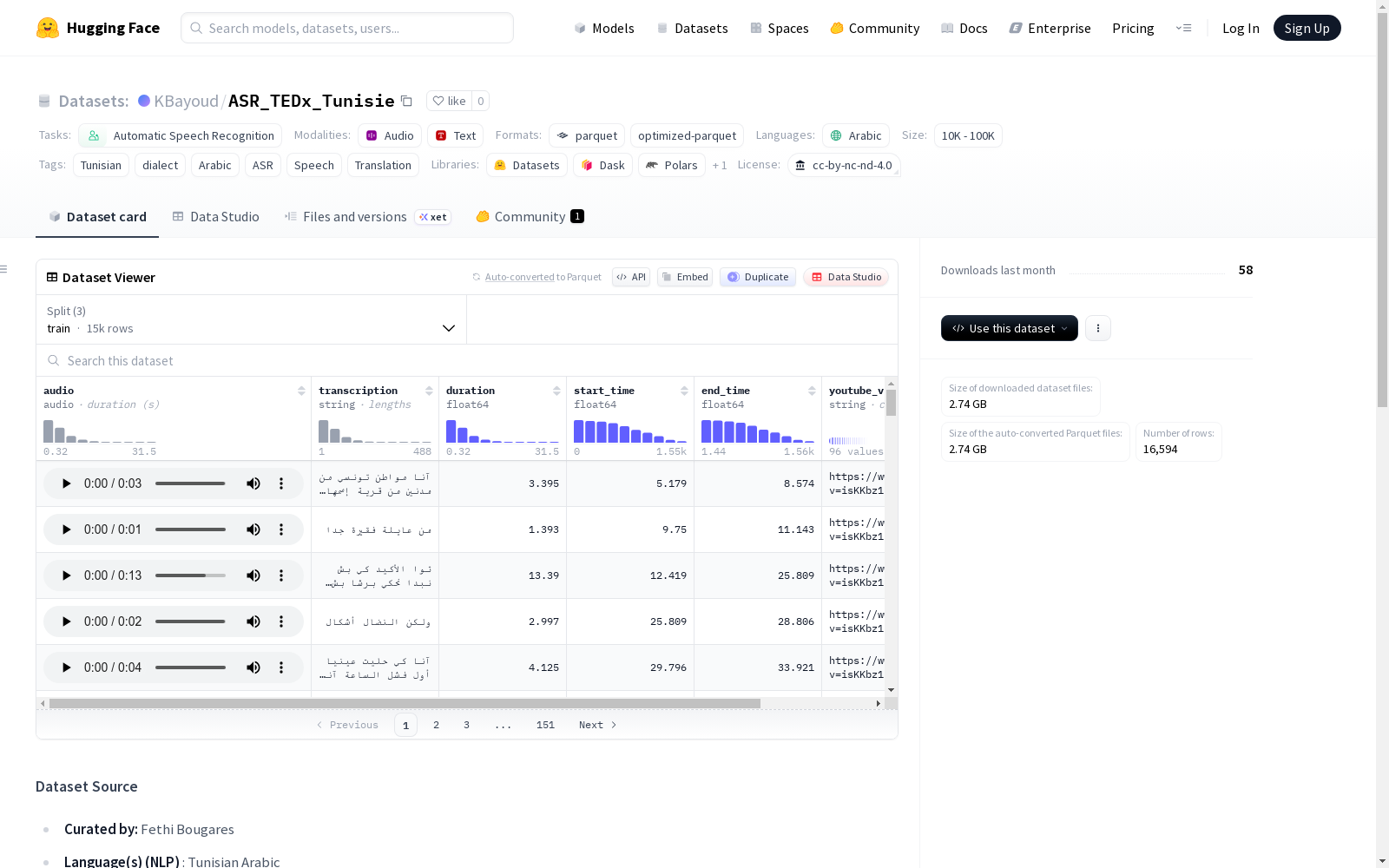
audio:音频片段,采样率为16000 Hztranscription:对应的转录文本duration:片段时长(浮点数)start_time:片段起始时间(浮点数)end_time:片段结束时间(浮点数)youtube_video:原始YouTube视频URL
数据划分统计
- 训练集:
- 样本数量:15023
- 字节大小:2425153587
- 验证集:
- 样本数量:731
- 字节大小:130598416
- 测试集:
- 样本数量:840
- 字节大小:143494811
- 总下载大小:2739037656
- 总数据集大小:2699246814
数据来源与处理
来源
- 相关论文:"TEDxTN: A Three-way Speech Translation Corpus for Code-Switched Tunisian Arabic - English"
- 作者:Fethi Bougares, Salima Mdhaffar, Haroun Elleuch, Yannick Estève
- 出版信息:Proceedings of The Third Arabic Natural Language Processing Conference, 2025年11月
- 论文链接:https://aclanthology.org/2025.arabicnlp-main.22/
- DOI:10.18653/v1/2025.arabicnlp-main.22
处理与调整
- 仅提取转录片段,跳过了
.en翻译文件。 - 为每个片段添加了YouTube视频URL。
- 标准化了音频片段文件名,以匹配YouTube视频ID和起止时间。
- 已验证音频片段可通过HuggingFace
datasets库加载。 - 保存为适用于机器学习流程的HuggingFace数据集格式。
搜集汇总
数据集介绍
构建方式
在阿拉伯语方言自动语音识别领域,ASR_TEDx_Tunisie数据集的构建体现了对突尼斯阿拉伯语这一特定语言变体的系统性采集与标注。该数据集源自TEDxTN语料库,通过提取TEDx演讲视频中的音频片段,并对应其原始突尼斯阿拉伯语转录文本而构建。构建过程中,研究者精心处理了音频与文本的对齐,确保了每个音频片段均配有精确的时间戳和对应的转录,同时保留了原始YouTube视频的链接信息,为后续的可追溯性和扩展研究提供了便利。整个数据集按照标准划分为了训练集、验证集和测试集,确保了其在机器学习任务中的直接可用性。
特点
该数据集的核心特征在于其专注于突尼斯阿拉伯语这一资源相对稀缺的方言,为阿拉伯语方言的语音识别研究提供了宝贵的资源。数据集中的音频采样率为16kHz,格式为WAV,确保了语音信号的质量。每条数据不仅包含音频和转录文本,还详细记录了片段的开始时间、结束时间、持续时间以及来源视频的URL,这种多维度信息的整合增强了数据集的实用价值与研究深度。其规模适中,总计超过一万六千条样本,为模型训练与评估提供了充足的数据基础。
使用方法
对于研究人员和开发者而言,该数据集可直接通过HuggingFace的`datasets`库进行加载和使用,极大简化了数据预处理流程。用户可依据标准的数据划分,直接将其应用于突尼斯阿拉伯语的自动语音识别模型的训练、验证与测试任务中。数据集中提供的精确时间戳信息,使得研究者能够进行细粒度的语音分析或对齐研究。此外,附带的YouTube视频链接为有兴趣进行多模态分析或数据验证的研究者开辟了额外的探索路径。
背景与挑战
背景概述
在阿拉伯语自然语言处理领域,方言语音资源的稀缺性长期制约着相关技术的发展。ASR_TEDx_Tunisie数据集由研究员Fethi Bougares及其团队于2025年构建,专注于突尼斯阿拉伯语这一特定方言的自动语音识别任务。该数据集源自TEDx演讲内容,旨在为代码切换环境下的突尼斯阿拉伯语-英语语音翻译研究提供高质量的三语料支持。其发布不仅丰富了阿拉伯语方言的语音语料库,也为跨语言语音处理模型在真实场景中的性能评估奠定了重要基础。
当前挑战
该数据集致力于解决突尼斯阿拉伯语自动语音识别与翻译中的核心难题,包括方言语音的高度变异性、与英语频繁代码切换带来的语言边界模糊,以及口语化表达导致的语法不规则性。在构建过程中,研究团队面临了从连续演讲流中精确切分语音片段、确保转录文本与方言发音准确对齐,以及处理背景噪音与演讲者口音差异等多重技术挑战。这些因素共同增加了数据标注的复杂性与模型训练的难度。
常用场景
经典使用场景
在阿拉伯语方言自动语音识别领域,ASR_TEDx_Tunisie数据集为研究突尼斯阿拉伯语方言提供了宝贵的资源。该数据集源自TEDx演讲,涵盖了真实场景下的口语表达,其经典使用场景在于训练和评估针对突尼斯方言的语音识别模型。研究人员利用其包含的音频片段与对应转录文本,能够构建端到端的语音识别系统,尤其适用于处理方言特有的语音变异和词汇特征,为方言语音技术发展奠定了数据基础。
解决学术问题
该数据集有效解决了方言语音识别中数据稀缺的核心学术问题。突尼斯阿拉伯语作为阿拉伯语的一种方言变体,长期以来缺乏大规模、高质量的标注语音数据,制约了相关模型的开发。ASR_TEDx_Tunisie通过提供超过1.5万条带精确时间戳的语音-文本对,为方言语音建模、代码切换现象分析以及低资源语言处理等研究提供了关键支持。其存在促进了方言语音技术领域的实证研究,缩小了主流语言与方言在技术资源上的差距。
衍生相关工作
围绕ASR_TEDx_Tunisie数据集,已衍生出多项经典研究工作。其原始论文提出了一个用于代码切换语音翻译的三语料库框架,为方言与英语间的翻译任务设立了基准。后续研究可能在此基础上,探索针对突尼斯方言的端到端语音识别架构、方言自适应预训练方法,或利用其进行多模态学习(结合视频URL信息)。这些工作共同推动了阿拉伯语方言计算语言学的发展,并为其他低资源方言的语音处理提供了可借鉴的技术路径。
以上内容由遇见数据集搜集并总结生成


