MizanQA
收藏arXiv2025-08-22 更新2025-08-26 收录
下载链接:
https://huggingface.co/datasets/adlbh/MizanQA-v0
下载链接
链接失效反馈官方服务:
资源简介:
MizanQA 是一个专为评估大型语言模型在摩洛哥法律问答任务上的表现而设计的基准数据集。该数据集包含超过 1700 个选择题,涵盖了摩洛哥法律的各个方面,包括现代标准阿拉伯语、伊斯兰马利基法学、摩洛哥习惯法和法国法律的影响。数据集的构建过程经过了多个阶段,包括收集、时间筛选、组织、提取和验证。MizanQA 的目标是解决低资源语言领域(如阿拉伯语)中法律文本的理解和处理问题,并为评估法律 AI 的公平性和人类监督提供基准。
MizanQA is a benchmark dataset specifically designed to evaluate the performance of large language models (LLMs) on Moroccan legal question-answering tasks. This dataset contains over 1,700 multiple-choice questions covering all aspects of Moroccan law, including Modern Standard Arabic, Maliki Islamic jurisprudence, Moroccan customary law, and the influence of French law. The dataset was constructed through multiple stages, including collection, temporal filtering, organization, extraction, and validation. The goal of MizanQA is to address the challenges of understanding and processing legal texts in low-resource language domains such as Arabic, and to provide a benchmark for evaluating the fairness and human oversight of legal AI.
提供机构:
Polytechnic University
创建时间:
2025-08-22
原始信息汇总
MizanQA: 摩洛哥法律问答基准数据集概述
数据集摘要
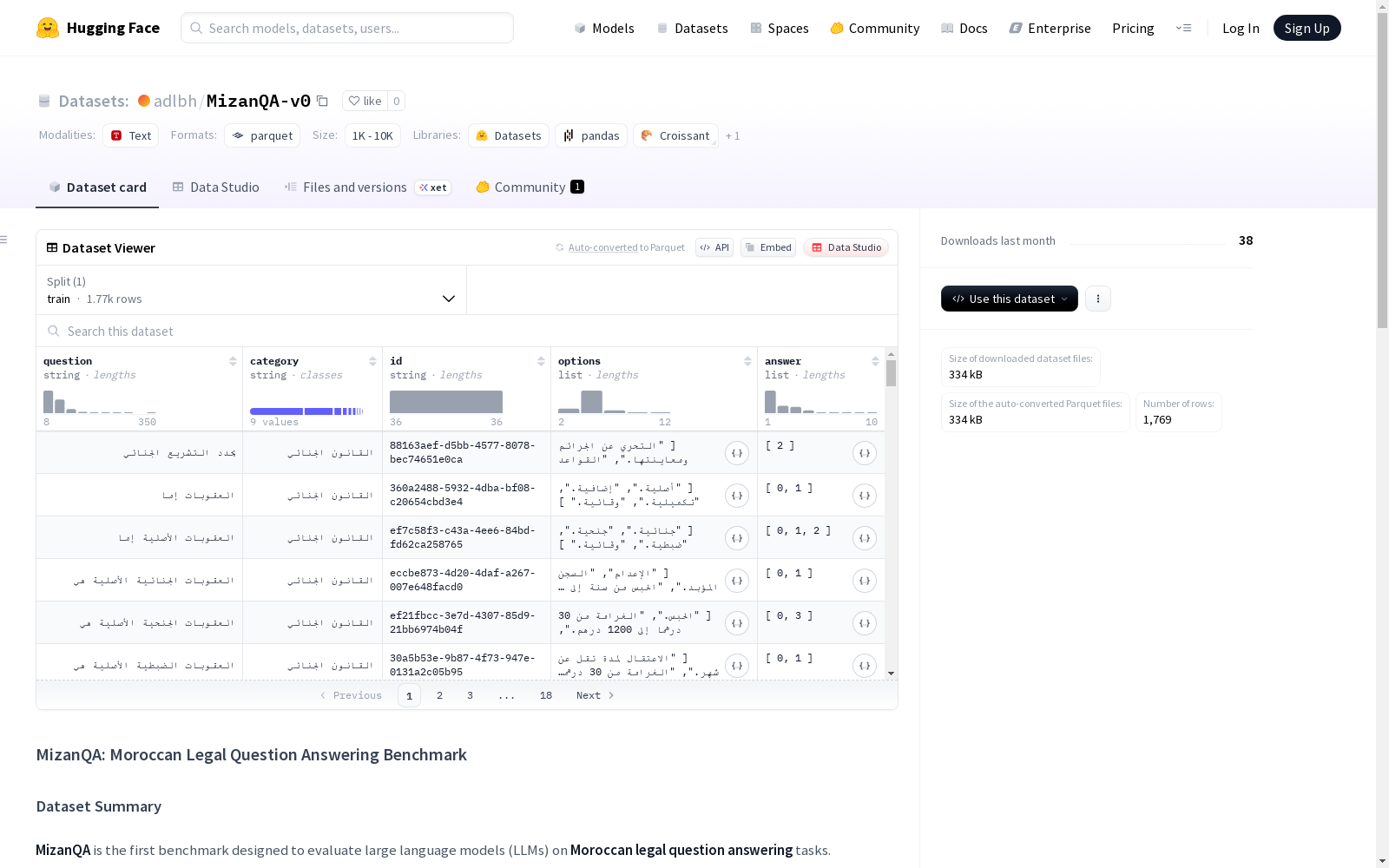
MizanQA是首个用于评估大语言模型在摩洛哥法律问答任务上表现的基准数据集。该数据集包含1,776个多项选择题(MCQs),其中许多题目具有多个正确答案,涵盖了摩洛哥法律的多个领域。数据集反映了摩洛哥的法律复杂性,其法规受到现代标准阿拉伯语、马利基法学、习惯法和法国法律的影响。
数据集从公开的摩洛哥法律考试题库和多项选择题中筛选而来,每个问题都经过专家手动验证以确保准确性。
支持任务与基准
- 多项选择法律问答:问题要求选择一个或多个正确答案
- 大语言模型评估:已用于评估LLaMA、Gemini以及阿拉伯语专注模型(如ALLAM)等模型
- 校准研究:包含部分正确性和置信度校准的评估指标
数据集结构
-
问题数量:1,776个
-
类别:涵盖14个法律领域,包括:
- 民事诉讼程序(460个问题)
- 刑法(847个问题)
- 家庭法典(38个问题)
- 家庭法(66个问题)
- 义务与合同法(37个问题)
- 王国司法系统(88个问题)
- 摩洛哥宪法(70个问题)
- 司法部门、考试及其他
-
每个问题的选项数量:2-12个
-
每个问题的正确答案数量:1-10个
技术规格
-
特征字段:
- question(字符串类型)
- category(字符串类型)
- id(字符串类型)
- options(字符串列表)
- answer(int64列表)
-
数据分割:
- train分割:829,913字节,1,769个样本
-
下载大小:333,743字节
-
数据集大小:829,913字节
搜集汇总
数据集介绍
构建方式
在摩洛哥法律问答基准MizanQA的构建过程中,研究团队采用半自动化的混合构建方法。首先从公开的摩洛哥法律多选题库中收集原始文档,由法律专家进行时效性筛选,剔除基于过时立法的内容。针对阿拉伯语PDF文档复制粘贴易产生乱码的问题,创新性地采用多模态大模型进行光学字符识别:将文档转换为图像批次后,使用Gemini-2.0-flash模型提取标准化格式的多选题。最后通过人工验证确保问题与原始内容的一致性,并按照法律领域进行精细化分类与归一化处理。
特点
MizanQA数据集显著体现了摩洛哥法律体系的多元文化特征,涵盖现代标准阿拉伯语、伊斯兰马利克法学、摩洛哥习惯法及法国法律影响的独特融合。该数据集包含1776道多选题,其独特之处在于支持多答案选项模式,单个问题的正确选项数量最多可达10个,选项数量范围为2至12个,极大增强了法律推理的复杂性。数据集覆盖14个法律领域,包括民事诉讼法、刑法、家庭法等,充分反映了摩洛哥法律术语的文化特异性和法律体系的混合性特征。
使用方法
使用MizanQA进行评估时,需采用专门设计的提示模板将问题和选项输入大语言模型,要求模型输出认为正确的选项列表及其置信度分数。评估体系包含严格准确度指标(ACC)和新型度量标准:F1类度量(F1-like)和部分匹配惩罚准确度(PMPA),这些指标能有效处理多正确答案场景。同时采用选项级校准(ECEopt)和集合级校准(ECEset)两种置信度校准方法,确保模型预测概率与实证频率的一致性,为摩洛哥法律领域的大模型评估提供全面可靠的基准框架。
背景与挑战
背景概述
MizanQA数据集由摩洛哥6Polytechnic大学研究团队于2025年创建,旨在评估大语言模型在摩洛哥法律问答任务中的表现。该数据集聚焦阿拉伯语法律语境下的低资源领域,涵盖现代标准阿拉伯语、伊斯兰马利基法学、摩洛哥习惯法及法国法律影响的多重法律体系。包含超过1700道多选题目,其中部分题目采用多答案格式,精准捕捉了摩洛哥法律推理的复杂性。作为首个针对摩洛哥法律体系的基准数据集,其发布填补了阿拉伯语法律NLP领域的研究空白,为跨文化法律人工智能的发展提供了重要数据支撑。
当前挑战
该数据集核心挑战在于解决摩洛哥法律问答中的语言与领域特异性问题:法律文本融合了古典阿拉伯语语法与地方性法律术语,需同时处理精确的法律表述和摩洛哥特有的法律概念;构建过程中面临多源数据整合难题,包括从非结构化PDF提取文本时的OCR识别误差、基于过时法规的内容筛选,以及多答案格式带来的标注复杂性。此外,数据覆盖度有限,未能全面体现地区特异性法律实践和最新立法更新,且多选题形式可能无法完全还原真实法律推理的复杂性。
常用场景
经典使用场景
在法律人工智能领域,MizanQA数据集为评估大语言模型在摩洛哥法律问答任务中的表现提供了标准化测试平台。该数据集通过1700余道多选题,涵盖伊斯兰马利基法学、摩洛哥习惯法及法国法律影响等多重法律渊源,精准模拟了真实法律推理中需处理的多选项判断场景。研究人员利用该基准测试各类多语言及阿拉伯语专用模型,系统分析模型对混合法律体系的理解能力,特别是在需要同时选择多个正确答案的复杂情境下的表现。
解决学术问题
该数据集有效解决了低资源语言领域法律人工智能评估体系缺失的学术难题。针对阿拉伯语法律文本特有的语言复杂性——融合现代标准阿拉伯语与地方性法律术语的现象,MizanQA通过构建文化背景嵌入的评估框架,填补了非英语法律NLP研究的空白。其创新的多答案评估指标(如PMPA和F1-like度量)为处理可变选项数量的法律问答任务提供了方法论突破,推动了领域特异性模型开发与评估标准的演进。
衍生相关工作
该数据集催生了多个方向的研究延伸,包括跨司法管辖区法律模型对比研究,如与沙特阿拉伯法律数据集AraLegaleval的对比分析。基于MizanQA揭示的模型校准问题,研究者提出了面向法律领域的置信度校准新方法(ECEopt/ECEset)。此外,其多答案评估框架被扩展应用于医疗、金融等专业领域,推动了Jais、ALLAM等阿拉伯语大模型在专业领域的优化迭代。
以上内容由遇见数据集搜集并总结生成


