multiple-choice-questions
收藏Hugging Face2024-07-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/mateus-hamade/multiple-choice-questions
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多项选择题,主要用于信息检索模型的开发。数据集涵盖计算机科学领域的多个主题,每个问题以JSON格式结构化,包含唯一标识符、标题、陈述和答案选项列表。由于研究重点是文档检索,因此未存储正确答案和问题难度级别。数据集语言为葡萄牙语-巴西(PT-BR)。
This dataset comprises multiple-choice questions primarily intended for the development of information retrieval models. It covers a variety of topics within the field of computer science. Each question is structured in JSON format, including a unique identifier, title, statement, and a list of answer options. Given that the research focuses on document retrieval, neither the correct answers nor the difficulty levels of the questions are stored in the dataset. The language of the dataset is Brazilian Portuguese (PT-BR).
创建时间:
2024-07-01
原始信息汇总
数据集概述
基本信息
- 任务类别: 文本分类, 问答
- 语言: 葡萄牙语
- 标签: 多项选择, 问题, 教育
- 数据集名称: Multiple Choice Questions Dataset
- 数据集大小: 1K<n<10K
- 许可证: MIT
数据集描述
- 内容: 包含多项选择题的数据集,主要用于信息检索模型的开发。
- 结构: 每个问题以JSON格式存储,包含以下字段:
- id: 问题的唯一标识符。
- title: 问题的标题,指示学科领域和子领域。
- statement: 问题的陈述。
- alternatives: 包含正确答案的选项列表。
注意事项
- 由于数据集主要用于文档检索,因此未存储正确答案和问题难度级别。
示例数据
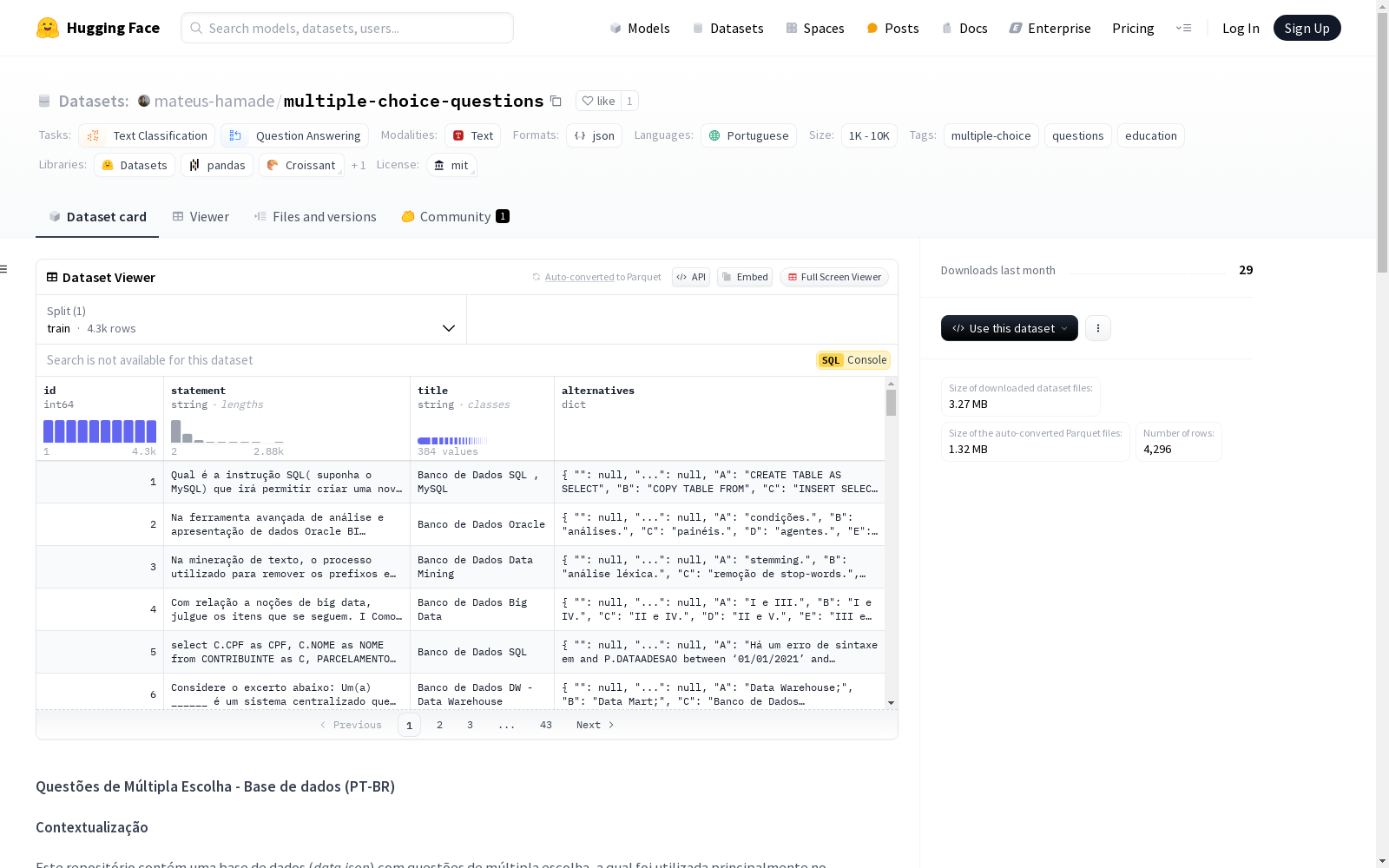
json { "title": "Banco de Dados SQL , MySQL", "statement": "Qual é a instrução SQL (suponha o MySQL) que irá permitir criar uma nova tabela com base nos resultados de uma consulta em uma tabela existente?", "alternatives": { "A": "CREATE TABLE AS SELECT", "B": "COPY TABLE FROM", "C": "INSERT SELECT (TABLE) INTO", "D": "CLONE TABLE WITH SELECT" } }
搜集汇总
数据集介绍
构建方式
该数据集通过收集和整理计算机科学领域的多项选择题构建而成,每道题目均以JSON格式存储,包含唯一标识符、题目标题、题干描述以及多个选项。数据集的构建旨在支持信息检索模型的研究,因此未包含正确答案和难度等级信息。
特点
该数据集涵盖了计算机科学领域的广泛主题,题目结构清晰,每道题目均包含详细的题干和多个选项,便于模型进行信息检索和分类任务。数据集以葡萄牙语(巴西)为主要语言,适用于针对该语言的信息检索研究。
使用方法
该数据集可用于训练和评估信息检索模型,特别是在处理多项选择题的场景中。研究人员可以通过解析JSON格式的数据,提取题目内容和选项,构建模型输入。此外,该数据集还可用于多语言信息检索研究,尤其是针对葡萄牙语(巴西)的文本分类和问答系统开发。
背景与挑战
背景概述
Multiple Choice Questions数据集是一个专注于计算机科学领域的多项选择题数据集,主要用于信息检索模型的开发。该数据集由葡萄牙语(巴西)的题目组成,涵盖了数据结构、数据库等多个子领域。每个问题以JSON格式存储,包含唯一标识符、题目、题干以及多个选项。该数据集的创建旨在为信息检索任务提供高质量的标注数据,帮助研究人员训练和评估模型在复杂查询场景下的表现。尽管数据集未包含正确答案和难度级别,但其结构化的格式和多样化的题目内容使其成为信息检索领域的重要资源。
当前挑战
Multiple Choice Questions数据集在构建和应用过程中面临多重挑战。首先,信息检索任务本身要求模型能够从大量文本中准确提取相关信息,而多项选择题的复杂性增加了模型理解题干和选项之间关系的难度。其次,数据集的构建过程中,未存储正确答案和难度级别,这限制了其在某些任务(如自动评分系统)中的应用。此外,数据集的题目主要集中在计算机科学领域,可能限制了其在其他学科中的泛化能力。最后,数据集的规模相对较小(1K<n<10K),可能不足以支持大规模深度学习模型的训练需求。
常用场景
经典使用场景
在计算机科学教育领域,multiple-choice-questions数据集被广泛用于开发和评估信息检索模型。该数据集通过提供多样化的选择题,帮助研究人员测试和优化模型在理解和处理复杂问题时的表现。特别是在自然语言处理和机器学习领域,该数据集为模型训练提供了丰富的语言素材和问题类型。
实际应用
在实际应用中,multiple-choice-questions数据集被广泛应用于在线教育平台和考试系统中。通过利用该数据集,教育机构能够开发出更加智能的考试系统,自动生成和评估选择题,从而提高教学效率和评估准确性。此外,该数据集还被用于开发智能问答系统,帮助学生在学习过程中快速获取相关知识。
衍生相关工作
基于multiple-choice-questions数据集,许多经典的研究工作得以展开。例如,研究人员利用该数据集开发了多种信息检索模型,如基于深度学习的问答系统和自动评分系统。这些工作不仅推动了信息检索技术的发展,还为教育技术领域的创新提供了新的思路和方法。此外,该数据集还被用于跨语言信息检索的研究,进一步拓展了其应用范围。
以上内容由遇见数据集搜集并总结生成


