EduBench
收藏Hugging Face2026-02-14 更新2026-02-15 收录
下载链接:
https://huggingface.co/datasets/recogna-nlp/EduBench
下载链接
链接失效反馈官方服务:
资源简介:
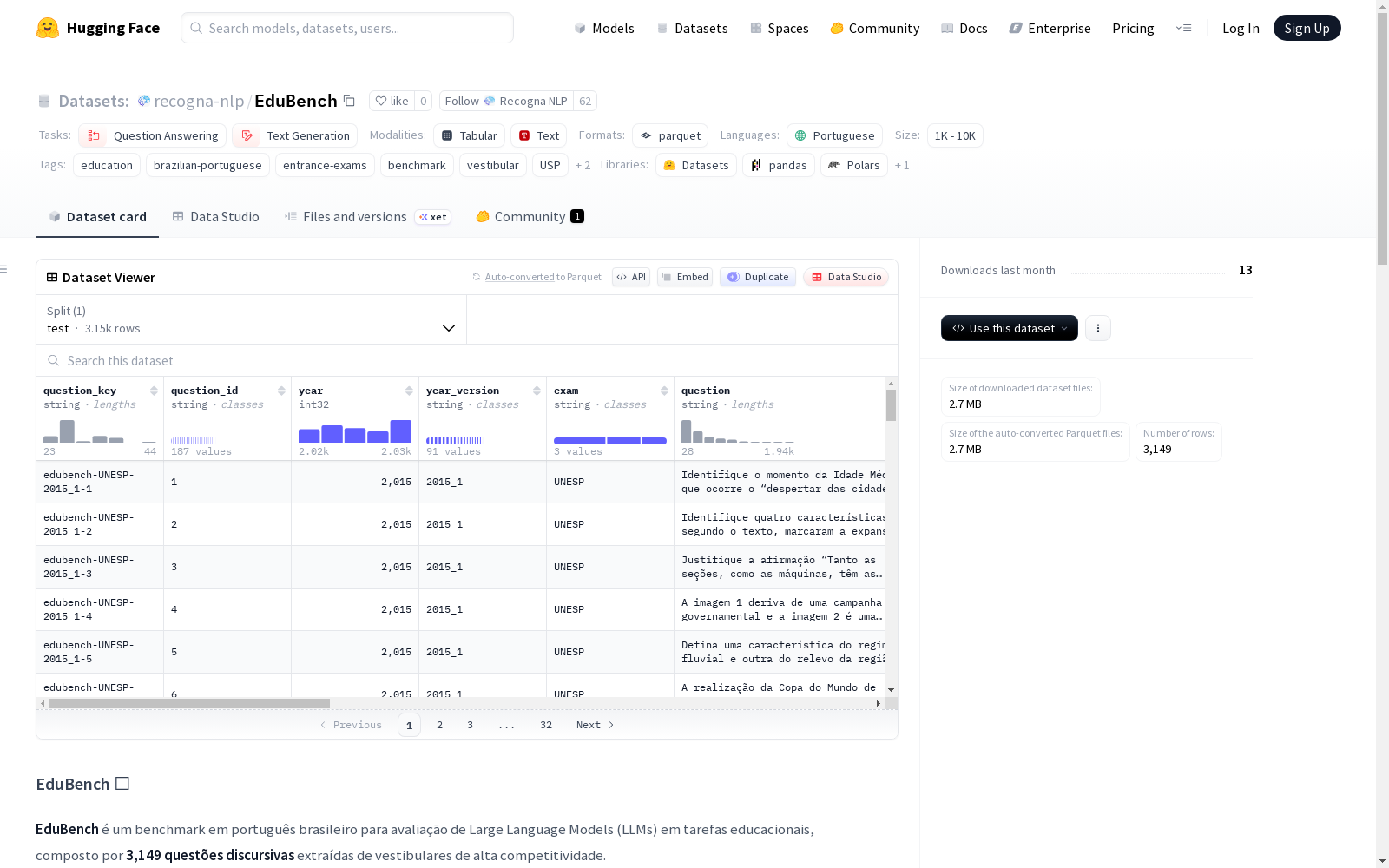
EduBench 是一个巴西葡萄牙语基准数据集,用于评估大型语言模型(LLMs)在教育任务中的表现。该数据集包含 3,149 道来自高竞争性入学考试(如 USP、UNICAMP 和 UNESP)的论述题,涵盖 2015 年至 2025 年的考试内容。数据集覆盖多个知识领域,包括人文科学(历史、地理、哲学、社会学)、精确科学(数学)、自然科学(物理、化学、生物)和语言(葡萄牙语、文学、英语)。数据集结构包含多个字段,如问题唯一标识符(question_key)、问题原始 ID(question_id)、考试年份(year)、考试版本(year_version)、考试机构(exam)、问题文本(question)、支持文本(supporting_texts)、完整答案(answer)、简短答案(short_answer)、评分指南(guidelines)、学科(subject)、难度估计(difficulty)、图像路径(image_paths)、图像描述(image_descriptions)、是否包含图像(has_images)和图像数量(num_images)。该数据集适用于问答和文本生成任务,特别适合用于教育领域的基准测试。
EduBench is a Brazilian Portuguese benchmark dataset developed to evaluate the performance of Large Language Models (LLMs) across educational tasks. It contains 3,149 essay questions sourced from highly competitive university entrance examinations including USP, UNICAMP and UNESP, covering exam content from 2015 to 2025. The dataset spans multiple knowledge domains, namely humanities (history, geography, philosophy, sociology), exact sciences (mathematics), natural sciences (physics, chemistry, biology), and language disciplines (Portuguese, literature, English). The dataset structure comprises multiple fields, including unique question identifier (question_key), original question ID (question_id), exam year (year), exam version (year_version), exam institution (exam), question text (question), supporting texts (supporting_texts), full answer (answer), short answer (short_answer), scoring guidelines (guidelines), subject (subject), difficulty estimate (difficulty), image paths (image_paths), image descriptions (image_descriptions), whether images are included (has_images), and number of images (num_images). This dataset is applicable to question answering and text generation tasks, and is particularly ideal for benchmark testing in the educational field.
提供机构:
Recogna NLP
创建时间:
2026-02-14
原始信息汇总
EduBench 数据集概述
数据集基本信息
- 数据集名称:EduBench
- 主要语言:葡萄牙语(巴西)
- 数据规模:1K<n<10K
- 任务类别:问答、文本生成
- 标签:教育、巴西葡萄牙语、入学考试、基准测试、vestibular、USP、UNICAMP、UNESP
- 配置名称:default
- 数据分割:测试集
- 测试集样本数量:3149
- 测试集大小(字节):6856851
- 下载大小:2697547
- 数据集大小:6856851
数据集描述
EduBench 是一个用于评估大型语言模型在教育任务上表现的巴西葡萄牙语基准测试,由从高竞争性入学考试中提取的 3,149 道论述题 组成。
数据来源
数据来源于以下巴西顶尖大学的入学考试:
- USP:圣保罗大学
- UNICAMP:坎皮纳斯州立大学
- UNESP:圣保罗州立大学
时间范围
涵盖 2015 年至 2025 年,共 11 年的考试。
知识领域
- 人文科学(历史、地理、哲学、社会学)
- 精确科学(数学)
- 自然科学(物理、化学、生物)
- 语言(葡萄牙语、文学、英语)
数据结构
数据字段说明
| 字段名 | 数据类型 | 描述 |
|---|---|---|
question_key |
string | 唯一标识符(例如:"edubench-USP-2024_1-15") |
question_id |
string | 原始试卷中的题目ID |
year |
int32 | 考试年份 |
year_version |
string | 考试版本/阶段(例如:"2024_1") |
exam |
string | 考试机构(USP, UNICAMP, UNESP) |
question |
string | 题目文本 |
supporting_texts |
string | 支持文本、片段等 |
answer |
string | 完整预期答案 |
short_answer |
string | 简短答案 |
guidelines |
string | 评分指南(如可用) |
subject |
string | 学科/领域 |
difficulty |
int32 | 估计难度(1-10) |
image_paths |
sequence(string) | 题目相关图片路径 |
image_descriptions |
sequence(string) | 图片的文字描述 |
has_images |
bool | 题目是否包含图片 |
num_images |
int32 | 图片数量 |
使用方式
数据集可通过 Hugging Face datasets 库加载,仅包含测试集。支持按考试机构或学科进行过滤。
引用信息
该工作已被 LREC 2026 接收,正式引用信息将在出版后提供。
相关链接
- GitHub 仓库:https://github.com/pedropaiola/EduBench
搜集汇总
数据集介绍
构建方式
在巴西高等教育入学评估领域,EduBench数据集的构建过程体现了严谨的学术规范。该数据集从巴西最具竞争力的三所公立大学——圣保罗大学、坎皮纳斯州立大学和圣保罗州立大学——2015年至2025年间的入学考试中,系统性地提取了3149道论述题。构建过程不仅采集了原始试题文本,还整合了配套的辅助材料、标准答案、评分指南以及视觉内容,并通过人工标注为每道题目赋予了学科分类与难度等级,从而形成了一个结构完整、来源权威的葡萄牙语教育评估语料库。
特点
EduBench数据集的核心特征在于其高度的专业性与丰富的元数据维度。作为专注于巴西葡萄牙语教育场景的基准测试,它全面覆盖了人文科学、自然科学、精确科学及语言学等多个核心学科领域。数据集中的每道题目均附有详细的元数据,包括唯一的题目标识、原始考试信息、预估难度系数以及是否包含图像等多媒体元素。这种多层次的结构设计使得该数据集不仅能评估模型的基础问答能力,更能深入检验其在复杂教育语境下的推理、理解和综合表达能力。
使用方法
在自然语言处理的研究与应用中,EduBench数据集主要服务于大型语言模型在葡萄牙语教育场景下的能力评估。研究者可通过Hugging Face的`datasets`库便捷加载该数据集,并利用其丰富的元数据字段进行灵活的筛选与分析,例如按考试机构、学科领域或题目难度进行子集划分。典型的使用流程包括加载测试集、遍历题目进行模型推理,并将模型的生成结果与数据集提供的标准答案及评分指南进行比对,从而定量评估模型在开放式教育问答任务上的性能表现。
背景与挑战
背景概述
EduBench数据集作为一项专注于巴西葡萄牙语教育评估的基准测试,由Recogna-NLP研究团队于近期构建,旨在系统评估大语言模型在复杂学术任务上的表现。该数据集精心收集了2015年至2025年间巴西顶尖高校(如圣保罗大学、坎皮纳斯州立大学和圣保罗州立大学)入学考试中的3149道论述题,覆盖人文科学、自然科学、精确科学及语言文学等多个学科领域。其核心研究问题在于探究大语言模型如何理解并回应需要深度推理、跨学科知识整合以及批判性思维的教育性问题,为葡萄牙语自然语言处理技术在教育智能化应用中的发展提供了重要的评估基础。
当前挑战
EduBench所针对的领域挑战在于,当前大语言模型在处理教育场景中的开放式论述题时,往往难以准确把握问题的深层意图、遵循学科特定的解答规范,并进行严谨的逻辑论证。构建过程中的挑战则体现在多方面:首先,从高度竞争的入学考试中提取并标准化论述题数据,需确保题目、参考答案及评分准则的完整性与准确性;其次,数据涉及多模态内容(如图像与文本结合),要求对图像信息进行恰当的描述与对齐;此外,涵盖长达十一年的试题演变,需统一不同年份、不同机构的命题风格与知识范围,以维持数据集的时效性与代表性。
常用场景
经典使用场景
在自然语言处理与教育技术交叉领域,EduBench数据集为评估大型语言模型在复杂教育任务中的表现提供了标准化基准。该数据集汇集了巴西顶尖大学入学考试中的开放式论述题,覆盖人文、自然科学、数学及语言等多个学科,要求模型不仅理解问题,还需生成连贯、准确的文本答案。研究者通常利用此数据集测试模型在知识推理、多模态信息整合及语言生成方面的能力,从而推动智能教育辅助系统的发展。
实际应用
在实际教育场景中,EduBench可被集成到自适应学习平台和智能辅导系统中,为学生提供个性化的练习与反馈。教育机构能够利用基于该数据集训练的模型,自动化评估学生答案的质量,辅助教师进行大规模作业批改。此外,它还能支持教育内容开发者创建更精准的模拟试题,优化备考资源,并为政策制定者提供数据驱动的见解,以改善教育评估体系。
衍生相关工作
围绕EduBench,学术界已衍生出一系列探索多语言教育基准、跨模态学习以及模型可解释性的研究工作。例如,研究者开发了针对葡萄牙语教育场景的专用评估框架,并利用该数据集进行了模型微调实验,以提升其在特定学科上的性能。同时,一些工作专注于结合图像描述与文本问题,推动视觉-语言模型在教育中的应用,进一步拓展了智能教育技术的边界。
以上内容由遇见数据集搜集并总结生成


