DynPose-100K
收藏arXiv2025-04-25 更新2025-04-26 收录
下载链接:
https://research.nvidia.com/labs/dir/dynpose-100k
下载链接
链接失效反馈官方服务:
资源简介:
DynPose-100K 是一个大规模的视频数据集,包含了带有相机标注的动态内容。该数据集由 100,131 个互联网视频组成,涵盖了多种场景。我们精心策划 DynPose-100K,以确保视频包含动态内容,同时确保相机可以被估计(包括内参和姿态)。为此,我们解决了两个具有挑战性的问题:(a) 识别适合相机估计的视频,(b) 改进动态视频的相机估计算法。
DynPose-100K is a large-scale video dataset containing dynamic content with camera annotations. This dataset comprises 100,131 internet videos spanning diverse scenarios. We meticulously curated DynPose-100K to ensure that the videos feature dynamic content and that their corresponding cameras can be estimated, including intrinsic parameters and poses. To this end, we addressed two challenging problems: (a) identifying videos suitable for camera estimation, and (b) improving camera estimation algorithms for dynamic videos.
提供机构:
英伟达(NVIDIA)1 密歇根大学2 纽约大学3
创建时间:
2025-04-25
搜集汇总
数据集介绍
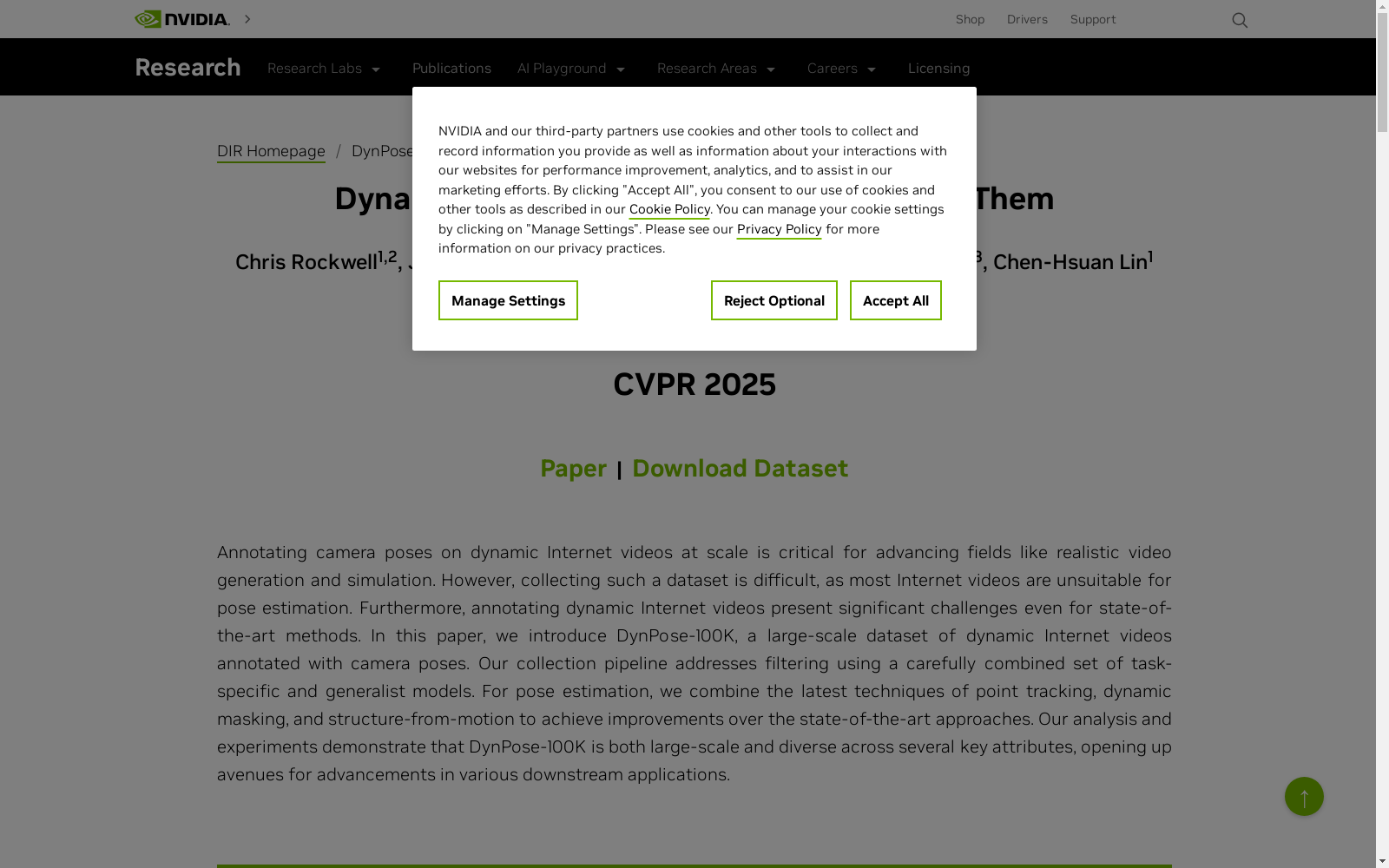
构建方式
DynPose-100K数据集的构建采用了多阶段筛选流程,结合了专业模型和通用视觉语言模型(VLM)的协同过滤策略。首先从Panda-70M的320万视频中,通过轻量级的手部交互检测、光流分析和焦距预测进行初步筛选,保留163万视频。随后依次应用畸变检测、点跟踪、动态掩码生成等专业模型,并最终通过GPT-4o mini进行综合质量评估,形成137K候选集。在姿态估计阶段,采用滑动窗口点跟踪(BootsTAP)、四模态动态掩码(语义/交互/运动/传播)和全局捆绑调整(Theia-SfM)的三阶段流程,确保在动态场景中准确恢复相机内外参数。
特点
该数据集的核心价值体现在三个维度:规模上包含100,131个动态网络视频,远超现有同类数据集;内容多样性覆盖人物互动、交通工具、运动场景等200余类语义类别,动词标签达150种;技术指标上提供12fps的相机位姿标注,视频平均时长4-10秒,动态目标表观尺寸呈双峰分布(5%-80%画面占比)。特别设计的轨迹质量指标显示,水平旋转累计超75度的视频占比38%,垂直旋转超50度的占21%,为视角合成和运动分析提供了丰富的运动模式样本。
使用方法
使用该数据集时建议采用三级质量控制:首先依据重投影误差(阈值1.37)筛选高精度子集,可提升78.1%的5像素内匹配精度;其次利用轨迹完整性标志(80%帧注册率)排除异常序列;对于生成任务推荐结合动态目标尺寸分布(图6)进行场景分层。在算法开发中,动态掩码组件可单独用于运动分割任务,而BootsTAP跟踪结果可直接服务于长期点对应研究。数据集中同步提供的语义标签和交互检测框支持多任务联合训练。
背景与挑战
背景概述
DynPose-100K是由NVIDIA、密歇根大学和纽约大学的研究团队于2025年推出的一个大规模动态视频数据集,旨在解决动态互联网视频中相机姿态标注的关键问题。该数据集包含100,131个互联网视频,涵盖了多样化的场景和动态内容,为计算机视觉和机器人学领域的多项任务,如真实感视频生成、仿真环境构建和视图合成等,提供了重要的数据支持。DynPose-100K的创建标志着在动态内容相机姿态估计领域的重要突破,其影响力不仅体现在数据规模上,还在于其精心设计的过滤和标注流程,为后续研究提供了高质量的基准。
当前挑战
DynPose-100K面临的挑战主要包括两个方面:首先,在领域问题方面,动态视频中的相机姿态估计极具挑战性,因为动态物体会遮挡静态场景,且静态场景的外观可能因光照和视角变化而发生显著改变,这使得传统的结构从运动(SfM)方法难以直接应用。其次,在数据集构建过程中,研究人员需要解决视频筛选的难题,即如何从海量互联网视频中识别出适合相机姿态估计的动态视频。此外,动态视频的相机姿态标注本身也是一个复杂问题,需要结合先进的点跟踪、动态掩码和全局束调整技术,以确保标注的准确性和鲁棒性。
常用场景
经典使用场景
DynPose-100K数据集在计算机视觉领域中被广泛应用于动态场景下的相机姿态估计研究。该数据集通过标注大规模互联网视频中的相机内参和姿态,为生成模型、视图合成和机器人仿真等任务提供了关键支持。其经典使用场景包括训练和评估动态视频中的相机姿态估计算法,特别是在处理复杂动态对象和光照变化的挑战性环境中。
衍生相关工作
基于DynPose-100K数据集,研究者们已开展多项创新工作。例如CamCo和B-Timer等并行研究利用类似数据实现了可控视频生成;MonST3R和MegaSaM等学习型方法通过该数据集提升了动态场景的三维重建能力。此外,数据集衍生的Lightspeed基准测试推动了光流估计和动态掩码技术的进步,为后续研究提供了标准化评估平台。
数据集最近研究
最新研究方向
近年来,DynPose-100K数据集在计算机视觉领域引起了广泛关注,特别是在动态视频相机姿态估计和三维场景重建方面。该数据集通过整合大规模互联网视频资源,并结合先进的相机姿态标注技术,为生成模型、视图合成和机器人仿真等应用提供了丰富的数据支持。前沿研究主要集中在提升动态场景下的相机姿态估计精度,利用先进的点跟踪和动态掩码技术优化结构从运动(SfM)流程。此外,该数据集还推动了基于学习的相机姿态估计方法的发展,通过结合合成数据和真实视频数据,显著缩小了仿真与现实的差距。DynPose-100K的多样性和规模使其成为训练和评估新算法的理想基准,尤其在处理复杂动态场景时表现出色。
相关研究论文
- 1Dynamic Camera Poses and Where to Find Them英伟达(NVIDIA)1 密歇根大学2 纽约大学3 · 2025年
以上内容由遇见数据集搜集并总结生成


