ssingh22/llamia-verl-data
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ssingh22/llamia-verl-data
下载链接
链接失效反馈官方服务:
资源简介:
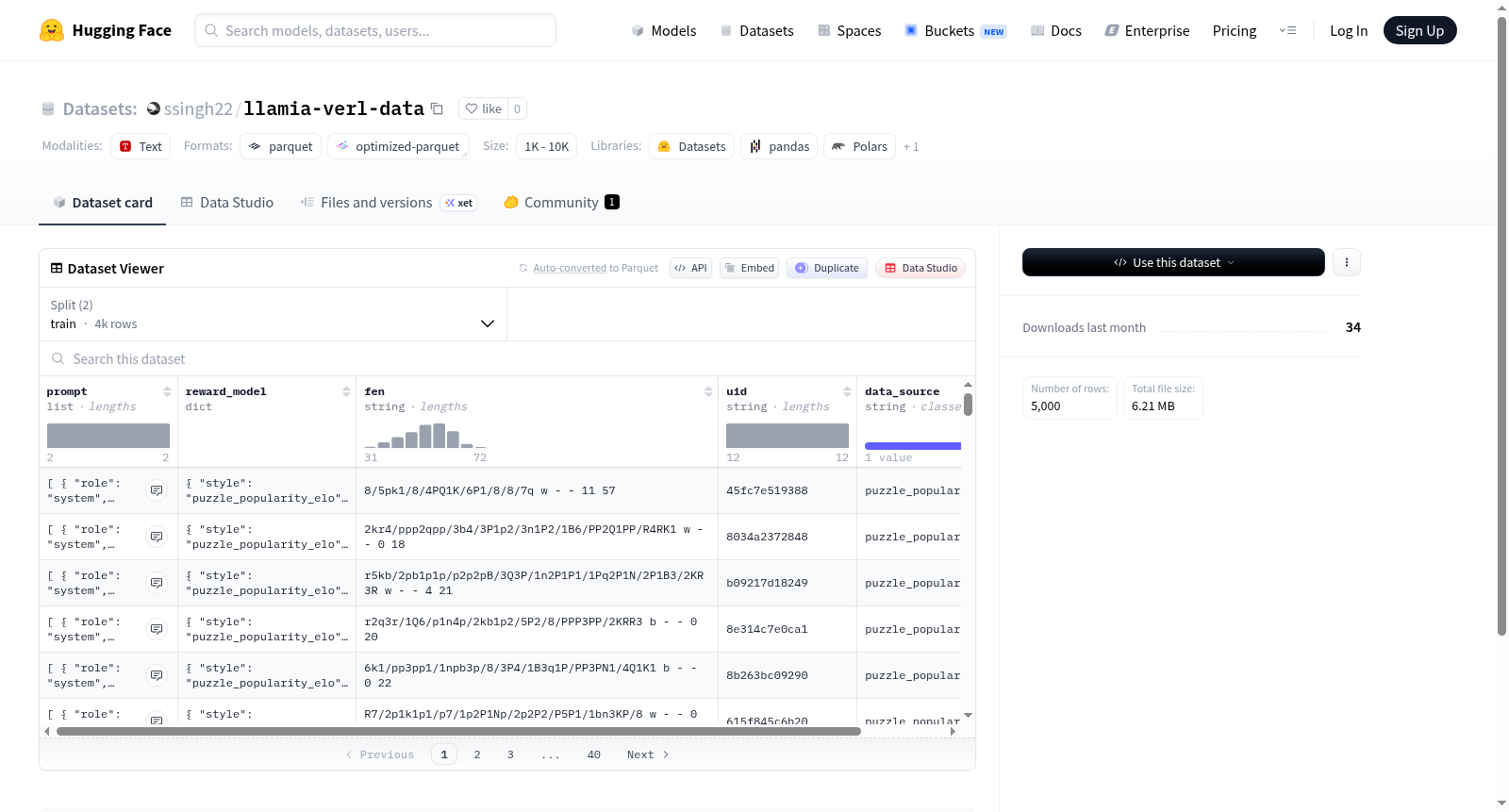
该数据集名为puzzle_popularity_elo,包含训练集和测试集,分别有4000和1000个样本。数据集特征包括提示(包含角色和内容)、奖励模型(包含风格和真实值,真实值又包含受欢迎程度和ELO评分)、FEN字符串、用户ID和数据来源。数据集主要用于存储与谜题相关的信息,特别是受欢迎程度和ELO评分。
The dataset, named puzzle_popularity_elo, includes training and test sets with 4000 and 1000 samples respectively. Features include prompts (with role and content), reward models (with style and ground truth, the latter containing popularity and ELO ratings), FEN strings, user IDs, and data sources. The dataset is primarily used to store information related to puzzles, particularly popularity and ELO ratings.
提供机构:
ssingh22
搜集汇总
数据集介绍
构建方式
该数据集名为llamia-verl-data,聚焦于国际象棋谜题领域,旨在为强化学习与偏好对齐研究提供结构化数据支撑。其构建基于puzzle_popularity_elo配置,精心设计了包含prompt、reward_model、fen、uid及data_source等字段的特征体系。其中,prompt字段以多轮对话格式存储角色与内容信息,而reward_model字段则通过嵌套结构封装了风格属性及ground_truth中的流行度与ELO评分,从而实现对谜题质量的量化标注。数据被划分为训练集与测试集,分别包含4000条和1000条样本,确保了模型训练与评估的可靠性。
使用方法
使用者可通过HuggingFace Datasets库加载该数据集,指定配置为puzzle_popularity_elo,并选择训练或测试分片进行访问。数据以parquet格式存储,支持高效读取。在强化学习训练中,可将prompt字段作为模型输入,reward_model中的ground_truth作为奖励信号,从而构建偏好对齐或ELO预测任务。此外,fen字段可用于棋盘状态编码,而data_source字段则便于进行多源数据混合实验。建议在使用时结合现有强化学习框架,如TRL或verl,以实现无缝集成与高效训练。
背景与挑战
背景概述
在强化学习与语言模型对齐领域,基于偏好数据集的训练方法近年备受关注。llamia-verl-data数据集于2024年由相关研究团队创建,聚焦于国际象棋谜题(chess puzzle)的流行度与Elo评分预测任务。该数据集包含4000条训练样本和1000条测试样本,每一条样本均以对话形式呈现问题描述,并附带基于奖励模型的结构化标签,包括风格、真实流行度与Elo评分等字段。通过将国际象棋谜题的客观难度指标与主观流行度结合,该数据集为探索语言模型在策略游戏中的推理与偏好对齐能力提供了独特的评估基准,推动了将非语言信号融入语言模型训练的研究进展。
当前挑战
该数据集所解决的领域挑战在于,现有语言模型偏好对齐方法多基于显式文本反馈,而缺乏对结构化、数值化隐性知识(如棋局评分)的建模能力。llamia-verl-data要求模型从对话式提示中理解谜题特征,并同时预测两个具有不同分布特性的目标(流行度与Elo评分),这对模型的跨模态对齐与多任务学习能力构成严峻考验。构建过程中,挑战体现在如何从棋局表示(FEN格式)中提取有效特征,并确保标注的Elo与流行度数据具有一致的权威来源及无偏性,以避免模型学习到虚假关联或过拟合于稀疏标注空间。
常用场景
经典使用场景
llamia-verl-data数据集专注于国际象棋谜题的流行度与Elo评分预测任务,其经典使用场景在于为强化学习与偏好对齐研究提供结构化训练数据。在基于人类反馈的强化学习(RLHF)框架下,该数据集通过将谜题的流行度指标(Popularity)与Elo评分作为奖励模型的标注信号,使语言模型能够学习区分不同难度和受欢迎程度的棋局状态。研究人员通常利用此数据集训练奖励模型,以指导策略模型生成更符合人类偏好或更具挑战性的棋步。此外,该数据集的FEN字符串表示形式使其天然适用于结合序列建模与棋盘状态编码的混合架构探索。
解决学术问题
该数据集的核心贡献在于桥接了国际象棋计算与偏好学习之间的学术鸿沟。传统上,棋局质量多依赖引擎评估或胜率判断,但缺乏对谜题人文层面‘流行度’的量化建模。llamia-verl-data首次将Elo等级分与流行度统计共同作为奖励信号,使得探究‘何种棋步组合更具人类审美吸引力’成为可能。这为解决奖励稀疏性与主观偏好建模两大难题提供了锚点基准,并推动了将相对评价(Elo)与绝对指标(流行度)融合至强化学习奖励函数设计的理论发展。其意义在于开辟了游戏策略与人类认知心理的交叉研究新范式。
实际应用
在实际应用中,llamia-verl-data可用于构建面向国际象棋爱好者的智能教练系统与谜题推荐引擎。通过预测给定谜题的Elo难度与流行度,平台能够为用户动态生成个性化挑战序列,既避免因难度过高导致的挫败感,也防止谜题缺乏趣味性。在线象棋社区可借助基于该数据训练的推荐模型优化谜题排行榜的排序算法,提升用户参与度与留存率。此外,该数据还能辅助游戏设计者分析历史谜题数据中的冷热分布规律,为创作更符合大众喜好的原创棋谜提供量化依据。
数据集最近研究
最新研究方向
该数据集聚焦于国际象棋谜题流行度与Elo等级分的量化关联,标志着强化学习与棋类博弈交叉领域的前沿探索。在人工智能自我博弈与奖励模型校准的热潮中,llamia-verl-data提供了一种新颖的评估范式——通过将谜题解法质量映射为基于流行度的Elo评分,为离线偏好优化与生成式推理系统构建了可复现的基准。这一方向不仅推动了基于人类反馈的强化学习(RLHF)在符号推理任务中的落地,更为理解复杂策略空间中隐式价值函数的形成机制提供了关键数据支撑,对发展具有自适应博弈能力的通用智能体具有深远意义。
以上内容由遇见数据集搜集并总结生成


