UrBench
收藏OpenDataLab2026-05-24 更新2025-02-01 收录
下载链接:
https://opendatalab.org.cn/OpenDataLab/UrBench
下载链接
链接失效反馈官方服务:
资源简介:
随着人工智能技术的飞速发展,大型多模态模型(LMMs)在多个领域展现出了卓越的能力。然而,在城市环境这一特定领域,对 LMMs 的评估仍存在不足。大多数现有的基准测试仅关注于单一视角下的区域级城市任务,无法全面评估 LMMs 在复杂城市环境中的表现。为此,上海人工智能实验室联合中山大学等多家单位,推出了 UrBench,这是一个专为评估 LMMs 在多视角城市场景中表现而设计的综合基准测试。
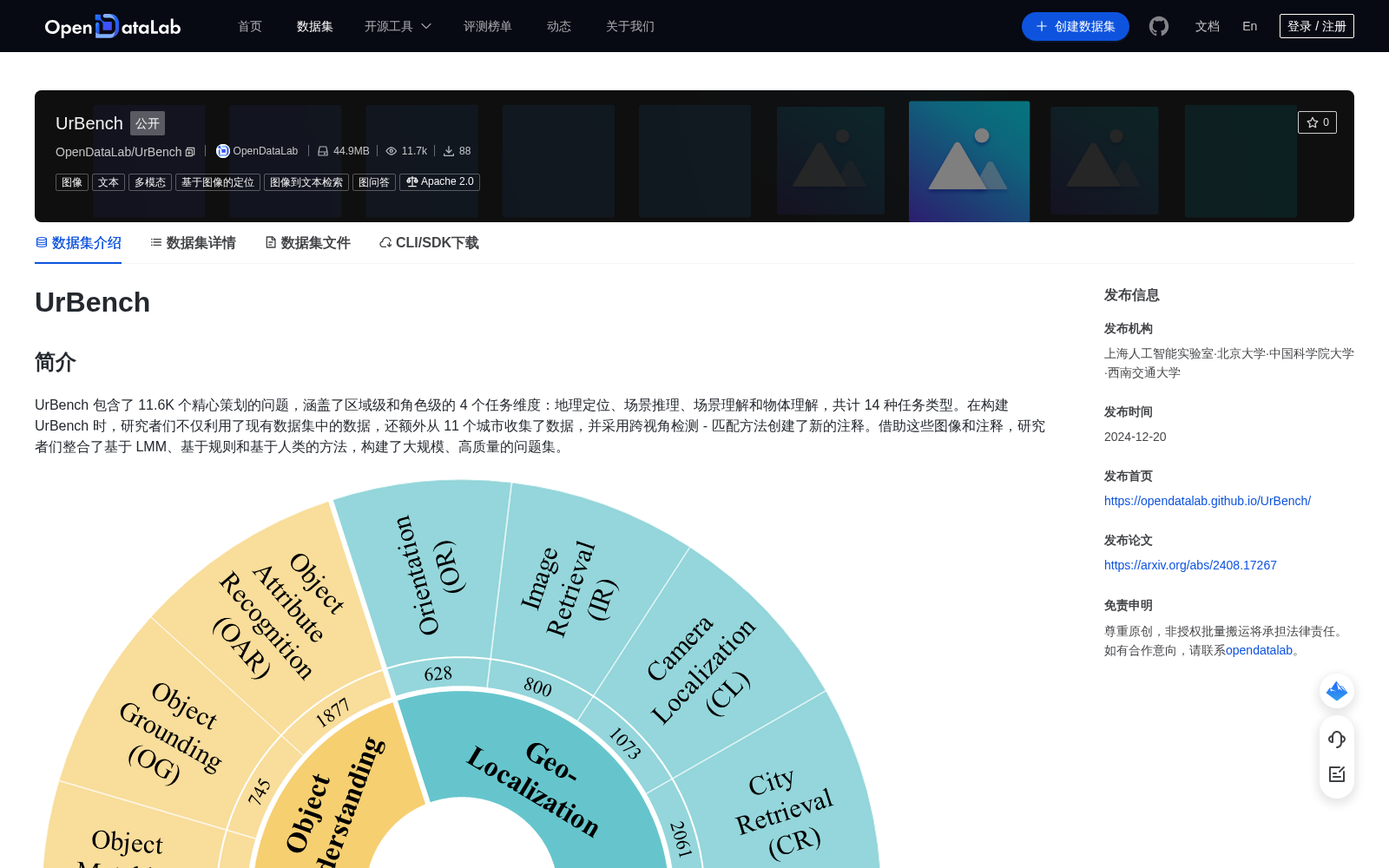
UrBench 包含了 11.6K 个精心策划的问题,涵盖了区域级和角色级的 4 个任务维度:地理定位、场景推理、场景理解和物体理解,共计 14 种任务类型。在构建 UrBench 时,研究者们不仅利用了现有数据集中的数据,还额外从 11 个城市收集了数据,并采用跨视角检测 - 匹配方法创建了新的注释。借助这些图像和注释,研究者们整合了基于 LMM、基于规则和基于人类的方法,构建了大规模、高质量的问题集。
对 21 个 LMMs 的评估结果显示,当前的 LMMs 在城市环境中存在诸多不足。即使是表现最佳的 GPT-4o,在大多数任务中也落后于人类,从简单的计数任务到复杂的定向、定位和对象属性识别任务,平均性能差距达 17.4%。此外,该基准测试还揭示了 LMMs 在不同城市视角下表现出不一致的行为,尤其是在理解跨视角关系方面。
With the rapid advancement of artificial intelligence technology, large multimodal models (LMMs) have demonstrated exceptional capabilities across various domains. However, there remains a critical gap in the evaluation of LMMs within the specific domain of urban environments. Most existing benchmarks only focus on regional-level urban tasks from a single perspective, failing to comprehensively assess LMM performance in complex urban settings. To address this issue, the Shanghai AI Laboratory, together with Sun Yat-sen University and other institutions, has introduced UrBench, a comprehensive benchmark specifically designed to evaluate LMM performance in multi-view urban scenarios.
UrBench encompasses 11.6K meticulously curated questions, spanning 4 task dimensions at both regional and role levels: geolocation, scene reasoning, scene understanding, and object understanding, totaling 14 task categories. When constructing UrBench, researchers not only utilized data from existing datasets but also collected additional data from 11 cities and adopted cross-view detection-matching methods to create new annotations. Leveraging these images and annotations, researchers integrated LMM-based, rule-based, and human-based approaches to build a large-scale, high-quality question set.
Evaluation results on 21 LMMs reveal that current LMMs suffer from numerous shortcomings in urban environments. Even the best-performing GPT-4o lags behind humans on most tasks, with an average performance gap of 17.4% across tasks ranging from simple counting to complex orientation, localization, and object attribute recognition. Furthermore, this benchmark reveals that LMMs exhibit inconsistent performance across different urban perspectives, particularly in understanding cross-view relationships.
提供机构:
OpenDataLab
创建时间:
2025-01-22
搜集汇总
数据集介绍
背景与挑战
背景概述
UrBench是一个多模态基准数据集,包含11.6K个精心策划的问题,涵盖地理定位、场景推理、场景理解和物体理解四个维度,共14种任务类型。它基于现有数据和从11个城市收集的新数据,采用跨视角检测-匹配方法创建注释,并整合了多种方法构建高质量问题集。
以上内容由遇见数据集搜集并总结生成


