roleplay-bench
收藏Hugging Face2026-04-26 更新2026-04-27 收录
下载链接:
https://huggingface.co/datasets/lazyweasel/roleplay-bench
下载链接
链接失效反馈官方服务:
资源简介:
RP-Bench 是一个用于评估大型语言模型(LLM)在角色扮演场景中表现的多维度基准数据集。该数据集旨在衡量模型在角色扮演中的写作质量、角色一致性、用户代理尊重、世界观整合、时间推理以及特定类型创作等方面的能力。数据集包含多种配置,如种子场景、对抗性种子、评分标准和结果数据等。RP-Bench 提供了详细的评分维度(共27个,分为3个层级),并基于真实用户偏好和LLM评判信号进行校准。数据集还包含多语言支持(英语和俄语),并提供了社区排行榜和失败模式分析。适用任务包括文本生成、LLM评估和创意写作。
RP-Bench is a multi-dimensional benchmark dataset designed to evaluate the performance of Large Language Models (LLMs) in role-playing scenarios. This dataset aims to measure models' capabilities across aspects including writing quality in role-play interactions, role consistency, respect for user agents, worldview integration, temporal reasoning, and creative content generation for specific genres. The dataset includes various configurations such as seed scenarios, adversarial seeds, scoring criteria, and outcome data. RP-Bench provides detailed scoring dimensions (27 in total, divided into three tiers), which are calibrated against real user preferences and LLM judgment signals. Additionally, the dataset supports multiple languages (English and Russian), and offers community leaderboards and failure mode analysis. Its applicable tasks cover text generation, LLM evaluation, and creative writing.
创建时间:
2026-04-14
原始信息汇总
RP-Bench 数据集概述
RP-Bench 是一个用于评估大语言模型(LLM)在角色扮演场景中表现的多维度基准测试集,旨在衡量模型的写作质量、角色一致性、用户代理尊重、世界书集成、时间推理以及特定类型的写作技巧。
数据集基本信息
- 名称: RP-Bench (Roleplay Quality Benchmark for LLMs)
- 语言: 英语 (en), 俄语 (ru)
- 许可证: cc-by-nc-4.0
- 任务类别: 文本生成 (text-generation)
- 大小: n<1K
- 标签: roleplay, benchmark, creative-writing, llm-evaluation, character-ai, sillytavern, multilingual
数据集配置
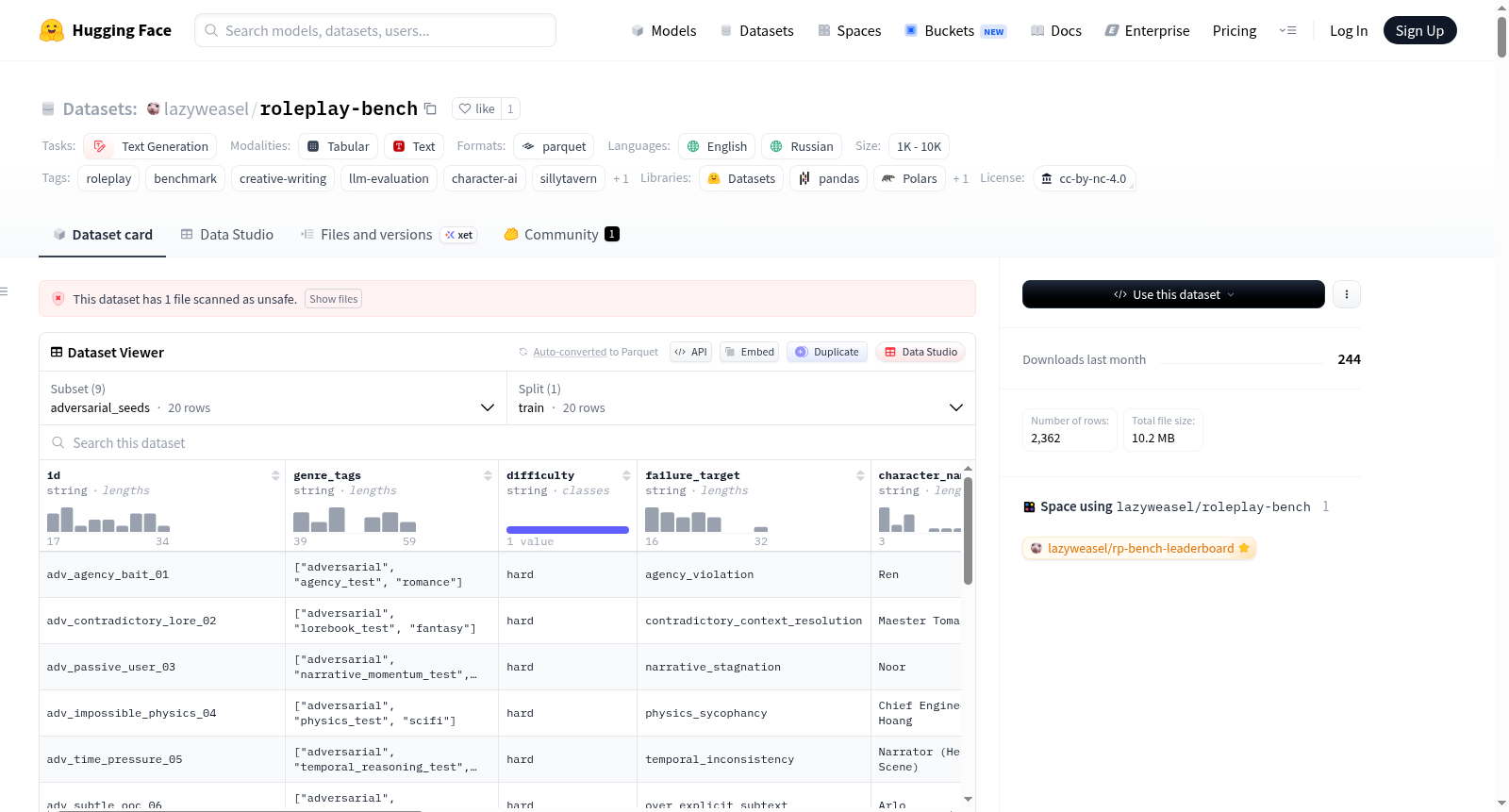
该数据集包含多个配置,每个配置对应一个 Parquet 格式的数据文件:
- seeds: 场景种子数据,包含8个覆盖不同流派和难度的合成场景模板。
- adversarial_seeds: 对抗性种子数据,用于测试模型在特定故障模式下的表现。
- rubric: 评分标准数据,包含所有26个评估维度的定义、故障模式和1-5级评分描述。
- results: 基准测试运行的结果数据,包含按模型、维度的得分和评审间一致性统计。
- leaderboard: 排行榜数据。
- elo: ELO 评级数据。
- flaw_hunter: 缺陷猎人模式下的评分数据。
- community_arena: 社区竞技场的人类投票数据。
- community_votes: 社区投票数据。
评估维度与架构
RP-Bench 使用三层、共27个维度的评估体系:
-
第一层:基础 (权重40%): 衡量模型的核心角色扮演能力,包括:
- 代理尊重 (Agency Respect)
- 指令遵循 (Instruction Adherence)
- 连续性 (Continuity)
- 长度校准 (Length Calibration)
- 不同声音 (Distinct Voices)
- 场景落地 (Scene Grounding)
-
第二层:质量控制 (权重35%): 衡量文本写作质量,包括:
- 反华而不实 (Anti-Purple Prose)
- 反重复 (Anti-Repetition)
- 反谄媚 (Anti-Sycophancy)
- 反完美 (Anti-Perfection)
- 展示而非讲述 (Show Dont Tell)
- 潜台词与暗示 (Subtext & Indirection)
- 节奏与克制 (Pacing & Restraint)
- 不完美的应对 (Imperfect Coping)
-
第三层:类型写作技巧 (权重25%): 针对特定场景进行评分,包括:
- 应得的亲昵 (Earned Intimacy)
- 氛围恐惧 (Atmospheric Dread)
- 结构性喜剧 (Structural Comedy)
- 挖掘真相 (Excavated Truth)
- 空间精度 (Spatial Precision)
- 栩栩如生的世界 (Lived-In Worlds)
- 信息架构 (Information Architecture)
- 结构必然性 (Structural Inevitability)
- 阈值逻辑 (Threshold Logic)
- 情感余韵 (Emotional Residue)
- 情色技巧 (Erotic Craft)
- 上下文整合 (Context Integration)
独特性与方法
- 基础:
- 从实际角色扮演会话中提取真实质量信号(如滑动、OOC修正、质量退化模式)。
- 评估维度来源于 SillyTavern 的 HawThorne V.2 预设和社区“陈词滥调”检测协议。
- 评分模式:
- 标准模式: 1-5分制。
- 缺陷猎人: 100分扣分制。
- 比较模式: 适用于ELO评级。
- 基于规则的检测: 检测“陈词滥调”等模式。
- 多轮会话: 使用脚本化的对抗性轮次来暴露模型退化问题。
- 双语言: 支持英语和俄语评估。
- 客观与主观结合: 结合LLM评审和无法被“钻空子”的基于规则的检测。
关键发现与排行榜
- LLM评审与社区偏好存在显著差异:
- LLM评审排行榜 (基于主观质量):
- #1: Claude Opus 4.6
- #2: DeepSeek v3.2
- #3: Claude Sonnet 4.5
- 社区投票排行榜 (基于用户参与度):
- #1: Gemma 4 26B
- #2: Mistral Small Creative
- #3: Gemini 2.5 Flash
- LLM评审排行榜 (基于主观质量):
- 不同信号间的差异:
- Claude Opus 4.6 在 LLM 评审中表现最佳,但在客观度量和“陈词滥调”检测中表现不佳。
- GPT-4.1 在客观指标和“陈词滥调”避免上领先,但在整体LLM评审中仅排名中游。
- DeepSeek v3.2 是各项信号最平衡的模型。
- 对抗性多轮测试: 大多数模型在对抗性压力下的平均得分差距很小(4.19-4.44),但得分轨迹能更有效地区分模型。Claude Sonnet 4.5 和 DeepSeek v3.2 在此类测试中得分提升,而其他模型则持平或下降。
- 社区与LLM评审的差异是系统性的: 社区的领先模型(Gemma, Mistral, Gemini)注重“有趣和吸引人”,而LLM评审的领先模型(Opus, Sonnet, DeepSeek)则更注重“不违反规则”。
数据局限
- LLM评审与用户偏好不一致: 验证结果显示,LLM评审(缺陷猎人模式)与用户偏好的不一致率(50.7%)高于一致率(38.7%)。
- “接受”标签可能包含噪声:用户可能因为疲劳等原因接受第二次尝试,而非因为其质量更高。
- 评审存在审美偏见,且缺乏会话历史和场景动态等上下文信息。
搜集汇总
数据集介绍
构建方式
在大型语言模型角色扮演能力评估领域,现有基准多聚焦于通用知识或代码生成,难以捕捉角色扮演场景中的多维特质。Roleplay-Bench数据集由此应运而生,其构建方式融合了真实用户反馈与系统化方法论。数据源自26个评分维度,划分为基础能力、质量控制与流派技艺三大层级,这些维度提炼自SillyTavern插件HawThorne V.2的21个流派指令器,以及24次真实角色扮演会话中的角色外纠正记录和34组用户滑动选择(swipe)所反映的偏好模式。此外,数据集包含8个合成场景模板,覆盖奇幻慢热、极地恐怖、校园喜剧等多个流派,每个模板均配备完整的角色卡、用户角色设定、开场白及评估聚焦维度,为多轮对话测试提供了结构化基础。评测流程通过OpenRouter API调用测试模型生成回应,再由两个独立的评判模型(Claude Sonnet和GPT-4.1)对所有适用维度进行打分,最终聚合生成跨模型排名。
特点
该数据集的突出特点在于其多维评估框架与对真实用户偏好的校准机制。首先,它囊括了27个评分维度,从基础的代理尊重、指令遵从与连续性,到进阶的反紫文、反重复与反谄媚,乃至流派专属的亲密感建构、恐怖氛围渲染与喜剧结构设计,实现了对角色扮演质量的全面量化。其次,数据集特别引入了对抗性种子,针对代理违规、流派转换、物理谄媚等典型失败模式设计挑战回合,通过12轮对话中的质量轨迹而非均值来区分模型优劣。更关键的是,该基准揭示了大型语言模型作为评判者与人类用户在超过半数情况下存在系统性分歧,因此项目通过公共盲测竞技场收集了1857次成对投票,生成了基于人类偏好的ELO排名,这一排名与基于语言模型的评判结果几乎正交,强调了“遵循规则”与“令人愉悦”两种评价视角的本质差异。数据集还支持英俄双语评估,并提供了详细的失败模式分类表格,使研究者能精准定位各模型在不同场景下的短板。
使用方法
使用Roleplay-Bench数据集进行模型评估具有明确的流程与灵活的应用方式。研究者可通过Python的datasets库直接加载预制配置,命令行方式支持克隆项目仓库后安装依赖并配置OpenRouter API密钥,即可执行完整的基准测试。数据集提供了多种配置选项,包括标准种子(seeds)、对抗性种子(adversarial_seeds)、评分规则(rubric)、评测结果(results)及社区排名(leaderboard)等,以适应不同的分析需求。对于深入评估,用户可启动多轮对话测试,利用脚本化的挑战回合检测模型在反复对抗压力下的质量衰减度,并通过ELO评分系统获取头对头的胜负概率。此外,公共盲测竞技场允许社区成员参与投票,每票仅需约30秒,用于持续校准基准信号与真实用户体验的一致性,最终基于1800余票生成社区ELO排行榜。数据集的维护者还提供了模型剖面档案,包含各模型在所有维度上的详细得分,便于进行多信号交叉分析。
背景与挑战
背景概述
RP-Bench(又名Roleplay-Bench)是由LeviTheWeasel于2024年创建的一个多维度大语言模型角色扮演质量评估基准。该数据集由社区驱动开发,旨在系统性地衡量LLM在角色扮演场景中的表现,涵盖写作质量、角色一致性、用户自主权尊重、世界观设定整合、时间推理以及特定类型的写作技巧等关键维度。与传统基准(如MMLU、HumanEval)聚焦于知识或推理能力不同,RP-Bench直面角色扮演这一日益增长但缺乏标准化评估的领域,其影响力体现在为模型开发者、社区用户及研究者提供了一个可复现、多维度的评价框架。核心研究问题在于:如何构建一个既能反映人类偏好(通过社区盲测竞技场收集逾1800次投票)又能捕获模型在长时间、对抗性对话中退化规律的评估体系。数据集包含英俄双语场景、27个评分维度及多个子集(如seeds、adversarial_seeds),成为了解前沿模型在创意交互中真实表现的稀缺资源。
当前挑战
RP-Bench所应对的核心领域挑战在于:现有的通用基准无法捕捉角色扮演中独特的交互艺术与叙事稳定性。该数据集的构建过程同样面临诸多艰巨挑战。首先,评估标准的主观性——LLM作为评判者与真实用户在偏好上存在系统性分歧(验证显示约半数情况下两者意见相左),这要求基准必须融合基于规则的客观指标与社区投票来校准信号。其次,构建高质量、可泛化的测试场景极为困难,特别是开发对抗性种子(adversarial seeds),它们需巧妙诱导模型暴露弱点(如用户自主性侵犯、风格偏移、物理诡辩等),同时避免过于刻意。此外,多轮交互中的质量退化难以量化:得分压缩效应(0.25分差范围内难以区分模型)使得近期轨迹分析与最坏情况检测成为更有效的鉴别手段。最后,跨语言(英-俄)与跨类型(浪漫、恐怖、科幻等)的一致性评估增加了注解与评价的复杂度,需要在保持标准化的同时兼容各类型的叙事逻辑。
常用场景
经典使用场景
在角色扮演对话生成与评估的学术疆域中,roleplay-bench数据集被广泛采纳为衡量大语言模型角色扮演能力的黄金标尺。其核心使用场景在于对模型的多维表现进行系统化评估,涵盖角色一致性、用户代理尊重、背景知识库融合、时间推理以及特定类型的叙事技艺。研究者借助该数据集提供的27个评分维度与对抗性种子,能够精准剖析模型在长篇多轮交互中的表现衰减与属性缺陷,从而产出具有统计显著性的比较结果。
解决学术问题
该数据集旨在弥合现有基准测试如MMLU或MT-Bench在角色扮演评估维度上的显著空白。传统评测指标往往忽略角色扮演场景中独特的交互韧性、叙事连贯性与美学偏好,而roleplay-bench通过引入多轮对抗性会话与社区盲评体系,系统性地揭示了模型端与用户端在审美判断上的结构性分歧。这一发现挑战了‘LLM作为裁判’的主流范式,为构建更贴近人类偏好的评估框架提供了坚实的实证基础。
衍生相关工作
基于roleplay-bench的评测框架与公开排行榜,学界与工业界已衍生出一系列富有影响力的后续工作。其中最具代表性的包括针对LLM法官偏差的系统性校准研究、基于社区投票的Elo排名机制优化、以及对抗性种子库在模型鲁棒性训练中的迁移应用。此外,该数据集所揭示的‘用户偏好与模型客观指标之间的正交性’催生了大量关于交互式叙事质量评估方法论的新探索,推动角色扮演领域从‘技术美学’向‘体验美学’的范式转向。
以上内容由遇见数据集搜集并总结生成


