tulu-sft
收藏Hugging Face2026-01-26 更新2026-01-27 收录
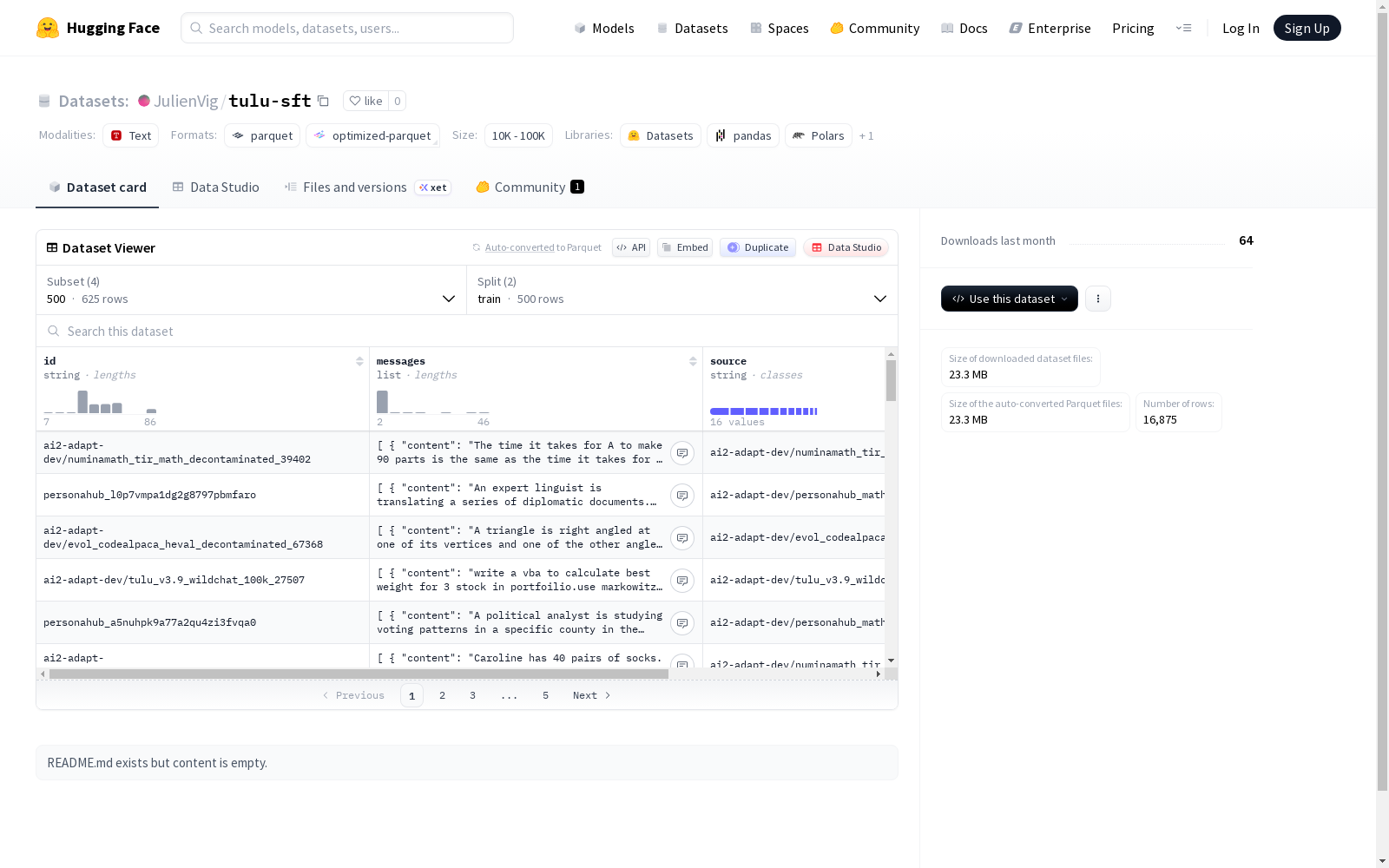
下载链接:
https://huggingface.co/datasets/JulienVig/tulu-sft
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含对话式消息数据,提供四种不同规模的配置(500条、1k条、2k条和10k条训练样本)。每个样本包含:唯一ID、消息列表(每条消息含内容和角色字段)、数据来源标识和token计数。数据集采用标准的训练集/测试集划分,测试集占比约20%(如10k配置含10k训练样本和2.5k测试样本)。消息内容以字符串形式存储,适用于对话系统训练、自然语言理解等任务。所有配置共享相同的数据结构,便于不同规模下的模型实验对比。
This dataset contains conversational message data, with four scale configurations available: 500, 1k, 2k, and 10k training samples. Each sample includes a unique ID, a list of messages (each message contains a content field and a role field), a data source identifier, and a token count. The dataset adopts a standard training/test split, where the test set accounts for approximately 20% of the total data; for instance, the 10k configuration consists of 10k training samples and 2.5k test samples. Message content is stored as strings, making the dataset applicable to tasks such as conversational system training and natural language understanding. All configurations share an identical data structure, which enables comparative model experiments across different dataset scales.
创建时间:
2026-01-20
原始信息汇总
Tulu-SFT 数据集概述
数据集基本信息
- 数据集名称: Tulu-SFT
- 数据集地址: https://huggingface.co/datasets/JulienVig/tulu-sft
数据集配置
该数据集包含四个不同规模的配置版本。
配置一:10k
- 训练集样本数: 10000
- 测试集样本数: 2500
- 训练集大小: 31104383 字节
- 测试集大小: 7776095 字节
- 下载大小: 16143942 字节
- 数据集总大小: 38880478 字节
配置二:1k (默认配置)
- 训练集样本数: 1000
- 测试集样本数: 250
- 训练集大小: 3110438 字节
- 测试集大小: 777609 字节
- 下载大小: 2060891 字节
- 数据集总大小: 3888047 字节
配置三:2k
- 训练集样本数: 2000
- 测试集样本数: 500
- 训练集大小: 6220876 字节
- 测试集大小: 1555219 字节
- 下载大小: 4005236 字节
- 数据集总大小: 7776095 字节
配置四:500
- 训练集样本数: 500
- 测试集样本数: 125
- 训练集大小: 1555219 字节
- 测试集大小: 388804 字节
- 下载大小: 1094918 字节
- 数据集总大小: 1944023 字节
数据结构
所有配置版本共享相同的特征结构:
- id: 字符串类型,样本唯一标识符。
- messages: 列表类型,包含对话消息。
- content: 字符串类型,消息内容。
- role: 字符串类型,消息角色。
- source: 字符串类型,数据来源。
- token_counts: 整数类型(int64),词元计数。
数据文件组织
每个配置版本的数据文件按以下模式组织:
- 10k配置:
10k/train-*,10k/test-* - 1k配置:
1k/train-*,1k/test-* - 2k配置:
2k/train-*,2k/test-* - 500配置:
500/train-*,500/test-*
搜集汇总
数据集介绍
构建方式
在人工智能监督微调领域,tulu-sft数据集通过精心设计的结构化对话格式构建而成。该数据集采用多轮对话形式组织,每条记录均包含角色与内容字段,并标注了来源信息与词元数量。数据以不同规模配置呈现,涵盖500至10000条训练样本的多个版本,每个版本均划分训练集与测试集,确保数据划分的科学性与可复现性。这种分层设计使得研究者能够根据计算资源灵活选择适当规模进行实验,为模型微调提供了梯度化的数据支撑。
特点
tulu-sft数据集展现出鲜明的模块化特征,其核心在于提供标准化的对话序列格式。每条数据记录均采用消息列表结构,明确区分用户与助手角色,并附带来源标识与词元统计信息。数据集提供四种不同规模的配置选项,从精简的500条到完整的10000条样本,每种配置均保持相同的字段结构与数据划分比例。这种设计既保证了数据的一致性,又赋予研究者根据实验需求选择合适数据体量的灵活性,为监督微调任务提供了高度适配的数据基础。
使用方法
针对大语言模型的监督微调任务,tulu-sft数据集提供了即用型的数据接口。研究者可通过加载指定配置直接获取格式化对话数据,利用消息字段中的角色与内容信息构建训练样本。数据集内置的训练-测试划分允许直接进行模型训练与评估,而词元计数字段则为批次大小优化提供了参考依据。该数据集兼容主流机器学习框架,支持从最小规模开始渐进式实验,为探索不同数据量对微调效果的影响提供了系统化研究平台。
背景与挑战
背景概述
Tulu-SFT数据集是近年来为推进大型语言模型(LLM)的监督式微调(SFT)研究而构建的专门资源。该数据集由研究社区于2023年左右发布,旨在应对开源模型在遵循复杂指令与进行多轮对话方面的性能瓶颈。其核心研究问题聚焦于如何通过高质量、多样化的指令-响应对数据,有效提升模型在开放域任务中的泛化能力与人类对齐水平。该数据集的构建显著促进了指令微调技术的标准化与透明化,为后续的模型评估与比较提供了重要基准。
当前挑战
该数据集致力于解决监督式微调领域的关键挑战,即如何使模型精准理解并执行涵盖广泛主题与风格的开放式人类指令,同时确保生成内容的准确性、安全性与有用性。在构建过程中,挑战主要源于数据质量与规模的平衡:需要从海量网络文本中筛选、清洗并构建高质量对话数据,同时需精心设计多样化的任务与角色扮演场景以避免模型过拟合。此外,确保数据标注的一致性、消除潜在的偏见与有害内容,亦是构建过程中需持续应对的复杂问题。
常用场景
经典使用场景
在大型语言模型(LLM)的监督微调(SFT)领域,tulu-sft数据集以其结构化对话格式成为模型对齐与指令遵循能力训练的核心资源。该数据集通过包含多轮对话的messages字段,模拟真实人机交互场景,使模型能够学习从用户查询到系统回复的连贯生成模式。研究人员通常利用其不同规模配置(如500至10k样本)进行渐进式训练,以优化模型在复杂对话任务中的响应质量和一致性,从而推动开放域对话系统的性能边界。
衍生相关工作
围绕tulu-sft数据集,学术界衍生出多项经典研究工作,例如基于其多轮对话结构探索模型增量学习机制的实验,以及利用其角色标注研究对话策略优化的算法。该数据集常被整合进如Alpaca、Vicuna等开源LLM训练流程中,作为提升模型指令遵循能力的关键组件。后续研究进一步扩展了其在安全对齐、多语言对话生成等方向的评估框架,形成了以数据为中心的模型迭代范式。
数据集最近研究
最新研究方向
在大型语言模型指令微调领域,Tulu-SFT数据集作为高质量对话式指令数据集合,正推动模型对齐与泛化能力的前沿探索。当前研究聚焦于利用其结构化多轮对话格式,优化模型对人类意图的理解与响应生成,特别是在复杂推理与多步骤任务中的表现。随着开源模型社区对可复现微调流程的需求增长,该数据集促进了低资源高效微调方法的创新,如参数高效微调与数据混合策略,以降低训练成本并提升模型适应性。这些进展不仅加速了对话智能体的实用化部署,也为构建更安全、可靠的AI系统提供了关键数据支撑。
以上内容由遇见数据集搜集并总结生成


