AEGIS
收藏Hugging Face2026-01-08 更新2026-01-09 收录
下载链接:
https://huggingface.co/datasets/DongSky/AEGIS
下载链接
链接失效反馈官方服务:
资源简介:
AEGIS(即**A**ssessing **E**diting, **G**eneration, **I**nterpretation-**U**nderstanding for **S**uper-intelligence)是一个全面的多任务基准测试,旨在评估统一多模态模型(UMMs)在多样化任务中应用世界知识的能力。该数据集包含1,050个具有挑战性的手动标注问题,涵盖21个主题(包括STEM、人文、日常生活等)和6种推理类型。AEGIS通过视觉理解、生成、编辑和交错生成任务,具体评估UMMs在世界知识范围内的表现,并提出了确定性基于检查表的评估(DCE)协议,以增强评估的可靠性。实验结果表明,大多数UMMs在世界知识方面存在严重缺陷,且性能随着推理复杂度的增加而显著下降。此外,简单的插件推理模块可以部分缓解这些缺陷,为未来研究指明了方向。
AEGIS (short for **A**ssessing **E**diting, **G**eneration, **I**nterpretation-**U**nderstanding for **S**uper-intelligence) is a comprehensive multi-task benchmark designed to evaluate the ability of unified multimodal models (UMMs) to apply world knowledge across diverse tasks. This dataset comprises 1,050 challenging manually annotated questions, covering 21 topics (including STEM, humanities, daily life, etc.) and six types of reasoning. AEGIS specifically assesses the performance of UMMs within the scope of world knowledge through visual understanding, generation, editing and interleaved generation tasks, and proposes a Deterministic Checklist-based Evaluation (DCE) protocol to enhance the reliability of the assessment. Experimental results demonstrate that most UMMs suffer from severe deficiencies in world knowledge, and their performance declines significantly as the complexity of reasoning increases. Furthermore, simple plug-in reasoning modules can partially alleviate these deficiencies, providing clear directions for future research.
创建时间:
2026-01-02
原始信息汇总
AEGIS数据集概述
数据集基本信息
- 数据集名称: AEGIS
- 许可证: MIT
- 任务类别: 图像-文本到文本、视觉问答、问答、文本到图像
- 支持语言: 英语、中文
- 数据规模: 1K<n<10K
数据集简介
AEGIS(Assessing Editing, Generation, Interpretation-Understanding for Super-intelligence)是一个用于评估统一多模态模型(UMMs)世界知识应用能力的综合性多任务基准。该基准旨在解决现有基准在评估上的局限性,通过涵盖视觉理解、生成、编辑和交错生成等多种任务,对模型进行全面的诊断性评估。
核心特点
- 多任务评估: 同时评估视觉理解、生成、编辑和交错生成能力。
- 广泛的知识覆盖: 包含1,050个具有挑战性的手动标注问题,涵盖21个主题(包括STEM、人文学科、日常生活等)和6种推理类型。
- 确定性评估协议: 提出了基于检查表的确定性评估(DCE)协议,使用原子化的“是/否”判断替代模糊的基于提示的评分,以提高评估的可靠性。
- 深入诊断: 揭示了当前先进统一多模态模型存在的严重世界知识缺陷,以及推理复杂性对性能的影响。
数据构成
- 领域覆盖: 涵盖STEM、人文学科和日常生活三大领域,包含21个多样化主题。
- 问题分布: 每个主题包含15个用于视觉理解、生成和编辑的提示,以及5个用于衡量复杂生成能力的视觉交错生成问题。
- 推理类型: 大多数提示中融入了六种不同的推理类型,要求模型具备内在的推理能力来完成请求。
相关资源
- GitHub仓库: https://github.com/DongSky/AEGIS
- 博客文章: https://m1saka.moe/aegis/
- 论文地址: https://arxiv.org/abs/2601.00561
引用信息
如果本工作对您的研究有所帮助,请考虑引用: bibtex @misc{aegis, title={AEGIS: Exploring the Limit of World Knowledge Capabilities for Unified Mulitmodal Models}, author={Jintao Lin, Bowen Dong, Weikang Shi, Chenyang Lei, Suiyun Zhang, Rui Liu, Xihui Liu}, year={2026}, eprint={2601.00561}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2601.00561}, }
搜集汇总
数据集介绍
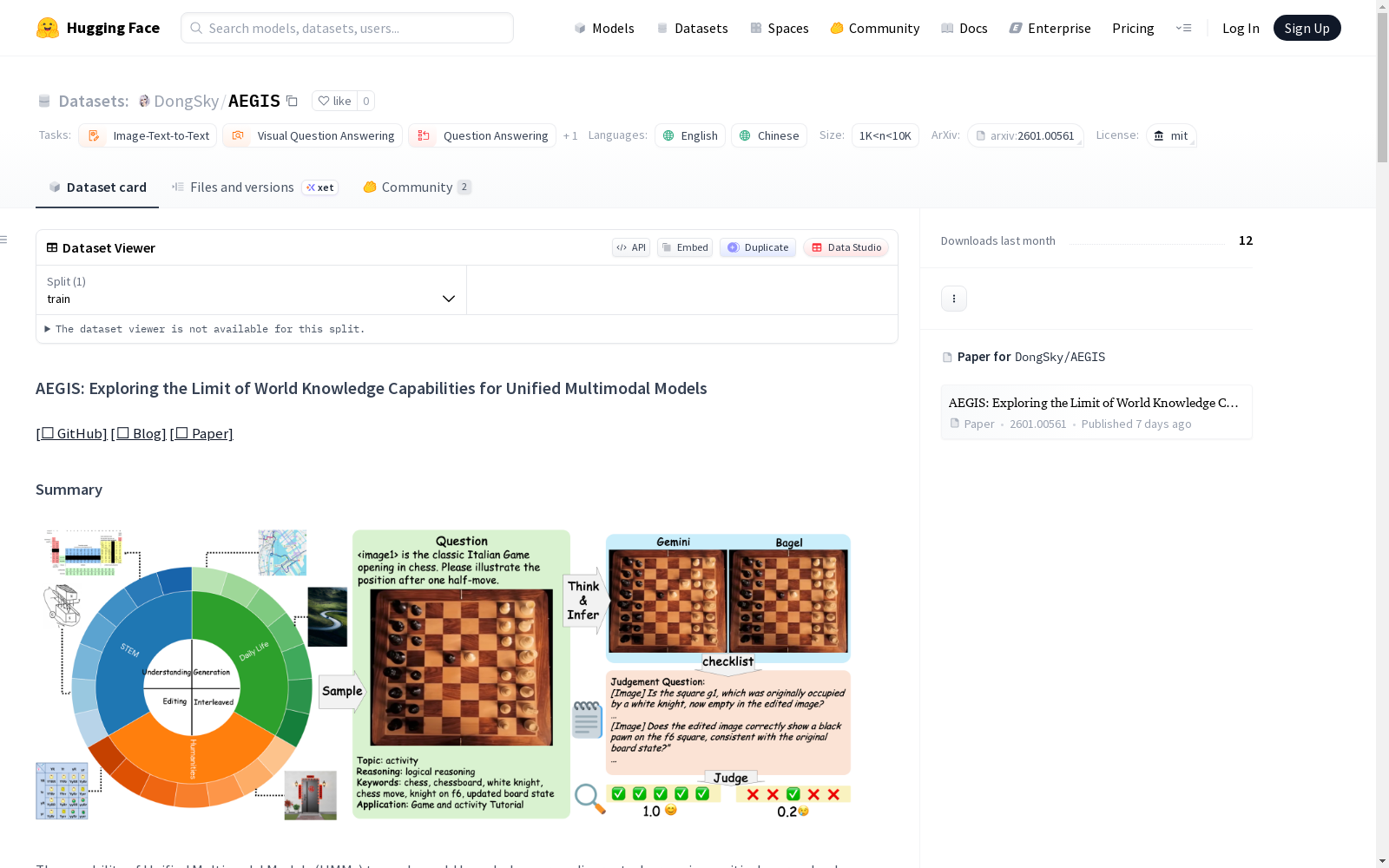
构建方式
在统一多模态模型领域,评估模型应用世界知识的能力一直是一项关键挑战。AEGIS数据集的构建采用了系统化的人工标注方法,涵盖了视觉理解、生成、编辑及交错生成四大任务类型。该数据集精心设计了1050个具有挑战性的问题,这些问题跨越了STEM、人文科学及日常生活等21个主题,并融入了六种不同的推理类型,旨在全面考察模型在复杂场景下的知识应用与推理能力。
特点
AEGIS数据集以其广泛的知识覆盖和严谨的评估框架而著称。它不仅整合了多任务评估,还引入了基于确定性检查表的评估协议,将传统模糊的提示评分转化为原子化的“是/否”判断,从而显著提升了评估的可靠性与可解释性。数据集中的问题设计强调对世界知识的深度运用,尤其关注模型在复杂推理过程中的表现,为诊断模型的知识缺陷提供了精细的视角。
使用方法
使用AEGIS数据集时,研究者可通过其提供的多任务基准对统一多模态模型进行系统评估。数据集支持对视觉理解、生成、编辑及交错生成能力的综合测试,用户可依据确定性检查表评估协议,对模型输出进行结构化分析。具体实施细节可参考其GitHub仓库,该仓库提供了完整的评估流程与工具,便于开展深入的性能诊断与比较研究。
背景与挑战
背景概述
在人工智能迈向通用智能的进程中,统一多模态模型(UMMs)整合视觉与语言理解、生成与编辑等能力,成为前沿探索的核心。然而,评估这些模型在广泛世界知识上的综合应用能力,长期缺乏系统且可靠的基准。为应对这一挑战,研究团队于2026年提出了AEGIS数据集,其名称源自评估编辑、生成、解释-理解以探索超级智能的英文首字母缩写。该数据集由Jintao Lin、Bowen Dong等研究人员共同构建,旨在通过涵盖科学、技术、工程、数学、人文及日常生活等21个主题的1050个高质量人工标注问题,系统诊断UMMs在复杂推理与多任务场景下的知识边界与性能局限,为模型能力的深度评估提供了重要工具。
当前挑战
AEGIS数据集致力于解决统一多模态模型在跨任务应用世界知识时所面临的评估难题,其核心挑战在于如何超越传统单任务基准的局限,构建一个能够同时评估视觉理解、生成、编辑及交错生成等多维能力的综合性测试平台。在构建过程中,研究团队需克服手动标注大规模、高质量多模态问题的复杂性,确保问题涵盖广泛的学科主题与多样的推理类型,如因果、比较与演绎推理等。此外,设计可靠且无歧义的评估协议亦是一大挑战,为此引入的确定性检查表评估方法,旨在以原子化的“是/否”判断替代模糊的提示评分,从而提升评估结果的客观性与可复现性,为模型缺陷的精准诊断奠定基础。
常用场景
经典使用场景
在统一多模态模型的研究领域,AEGIS数据集常被用于评估模型在跨任务世界知识应用中的综合能力。该数据集通过涵盖视觉理解、生成、编辑及交错生成等多任务场景,为研究者提供了一个系统性的测试平台,用以检验模型在复杂知识推理中的表现。其精心设计的1050个问题覆盖了STEM、人文学科及日常生活等21个主题,并融入六种推理类型,使得模型在应对多样化挑战时能够展现出真实的知识迁移与整合潜力。
实际应用
在实际应用层面,AEGIS数据集为开发更智能的多模态系统提供了关键支持。例如,在智能教育领域,该数据集可用于构建能够解答跨学科复杂问题的辅助工具;在内容创作中,它有助于评估模型根据知识生成或编辑视觉内容的能力。此外,其确定的评估方法为工业界提供了可靠的模型测试标准,助力于开发在医疗、娱乐等场景中具备稳健知识推理能力的应用,从而提升人工智能系统的实用性与可靠性。
衍生相关工作
围绕AEGIS数据集,已衍生出多项经典研究工作,主要集中在提升统一多模态模型的世界知识推理能力上。例如,一些研究借鉴其确定性评估协议,开发了新的模型诊断框架;另一些工作则利用数据集中的多任务设计,探索了插件式推理模块对缓解知识缺陷的有效性。这些研究不仅深化了对多模态模型局限性的理解,还促进了如知识增强训练、跨模态推理优化等技术方向的发展,为后续构建更强大的通用人工智能系统奠定了理论基础。
以上内容由遇见数据集搜集并总结生成


