BrokenVideos
收藏arXiv2025-06-25 更新2025-06-27 收录
下载链接:
https://broken-video-detectiondatetsets.github.io/Broken-Video-Detection-Datasets.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
BrokenVideos是一个针对AI生成视频中细粒度伪影定位的基准数据集,包含约3254个AI生成的视频,每个视频都带有精心标注的像素级掩码,以指示视觉损坏的区域。数据集的视频来自多种不同的生成方法,具有多样性。通过在BrokenVideos上训练现有的视频伪影检测模型和多模态大型语言模型(MLLMs),显著提高了它们在生成内容中定位损坏区域的能力。该数据集为伪影定位研究和视频生成及其质量保证的进一步创新提供了关键基础。
BrokenVideos is a benchmark dataset for fine-grained artifact localization in AI-generated videos. It contains approximately 3,254 AI-generated videos, each paired with meticulously annotated pixel-level masks that indicate the regions of visual artifacts. The videos in this dataset are sourced from a diverse range of generation methods. Training existing video artifact detection models and Multimodal Large Language Models (MLLMs) on BrokenVideos has significantly improved their capacity to localize damaged regions in generated content. This dataset provides a critical foundation for artifact localization research as well as further innovations in video generation and its quality assurance.
提供机构:
复旦大学, 中国
创建时间:
2025-06-25
搜集汇总
数据集介绍
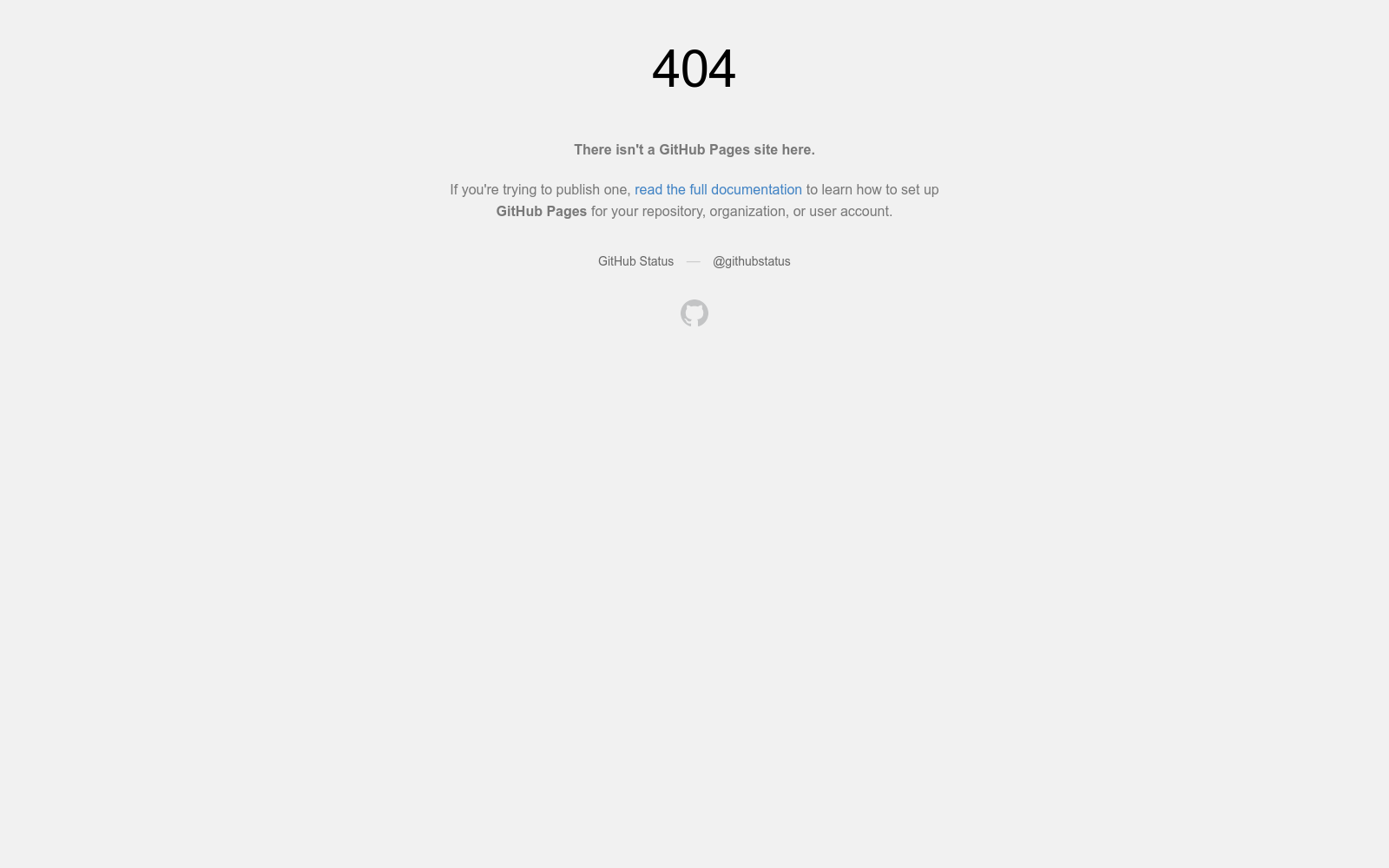
构建方式
在人工智能生成视频领域,视觉伪影的存在严重影响了内容的真实性和用户体验。BrokenVideos数据集的构建采用了混合策略,结合了内部生成视频和现有基准数据集的内容,确保了数据的多样性和标注质量。通过精心设计的半自动标注工具SAM2-GUI,研究团队对视频中的伪影进行了像素级标注,涵盖了技术、语义、认知、一致性和指令性五大类伪影,每类伪影均经过严格的人工审核,确保了标注的高精度和一致性。
特点
BrokenVideos数据集以其精细的标注和广泛的覆盖范围脱颖而出。数据集包含3,254个高分辨率AI生成视频,每个视频均配备了像素级伪影标注,总计约336,000个标注区域。视频内容涵盖了人类角色、动植物、机器人实体、城市景观等多种场景,且伪影类型多样,包括视觉崩溃、运动异常、语义混淆等。数据集的独特之处在于其不仅标注了伪影的存在,还详细记录了伪影的空间分布和类别,为研究者提供了丰富的分析维度。
使用方法
BrokenVideos数据集为视频伪影定位研究提供了坚实的基准。研究者可利用该数据集训练和评估各种视频分割模型,如SAMWISE、GLUS和VideoLISA,通过微调这些模型,显著提升其在伪影定位任务中的表现。数据集的使用方法包括加载视频序列和对应的标注掩码,输入到模型中进行训练或测试。此外,数据集还支持多模态大型语言模型的训练,通过结合文本提示和视觉信息,进一步优化伪影检测的准确性和鲁棒性。
背景与挑战
背景概述
BrokenVideos数据集由Fudan University、Shenzhen University、The Chinese University of Hong Kong等机构的研究团队于2025年联合发布,旨在解决AI生成视频中细粒度伪影定位的基准缺失问题。随着扩散模型推动文本到视频生成技术快速发展,合成视频常出现运动时序不一致、物体形变失真等视觉伪影,严重影响真实性与用户体验。该数据集包含3,254段多源生成视频,通过SAM2交互工具标注像素级伪影掩膜,填补了现有数据集仅支持视频/帧级检测而缺乏空间标注的空白,为质量评估算法研发和生成模型诊断提供了关键基础设施。
当前挑战
该数据集面临的领域挑战集中于AI生成视频伪影的复杂特性:多类别伪影(如技术性、语义性、认知性伪影)常空间共存且形态非结构化,传统基于自然场景的分割模型难以识别;构建过程中的核心挑战包括人工标注高成本(需帧级多实例标注)、伪影定义标准化(建立五维分类体系),以及跨模型生成内容多样性保障(覆盖53%人物场景至5%交通工具场景)。此外,现有视频质量评估方法因缺乏空间敏感性,难以直接迁移至细粒度定位任务。
常用场景
经典使用场景
在AI生成视频的质量评估领域,BrokenVideos数据集被广泛用于细粒度视觉伪影定位研究。该数据集通过提供像素级标注的伪影区域,为开发基于深度学习的视频分割模型提供了关键训练基准。其涵盖的3,254段视频包含运动不一致、物体形变等典型生成缺陷,特别适合验证模型在复杂时空维度上的异常检测能力。
解决学术问题
该数据集解决了AI生成视频领域缺乏细粒度伪影标注基准的核心问题,填补了传统二分类检测方法无法定位空间缺陷的空白。通过精确标注技术性、语义性等五类伪影,研究者可定量分析不同生成模型的失败模式,为改进视频生成算法提供可解释的诊断依据。其多标签标注策略还支持研究复合型伪影的共生机制。
衍生相关工作
该数据集催生了VideoLISA等新型视频分割架构的演进,其标注方法启发了SAM2-GUI半自动标注工具的研发。相关研究进一步扩展至跨模态检测领域,如腾讯AI Lab基于此开发的AVQA框架实现了文本-视觉联合伪影分析。后续工作正探索将该基准迁移至3D视频生成质量评估。
以上内容由遇见数据集搜集并总结生成


