OpenAlex
收藏OpenAlex 数据集概述
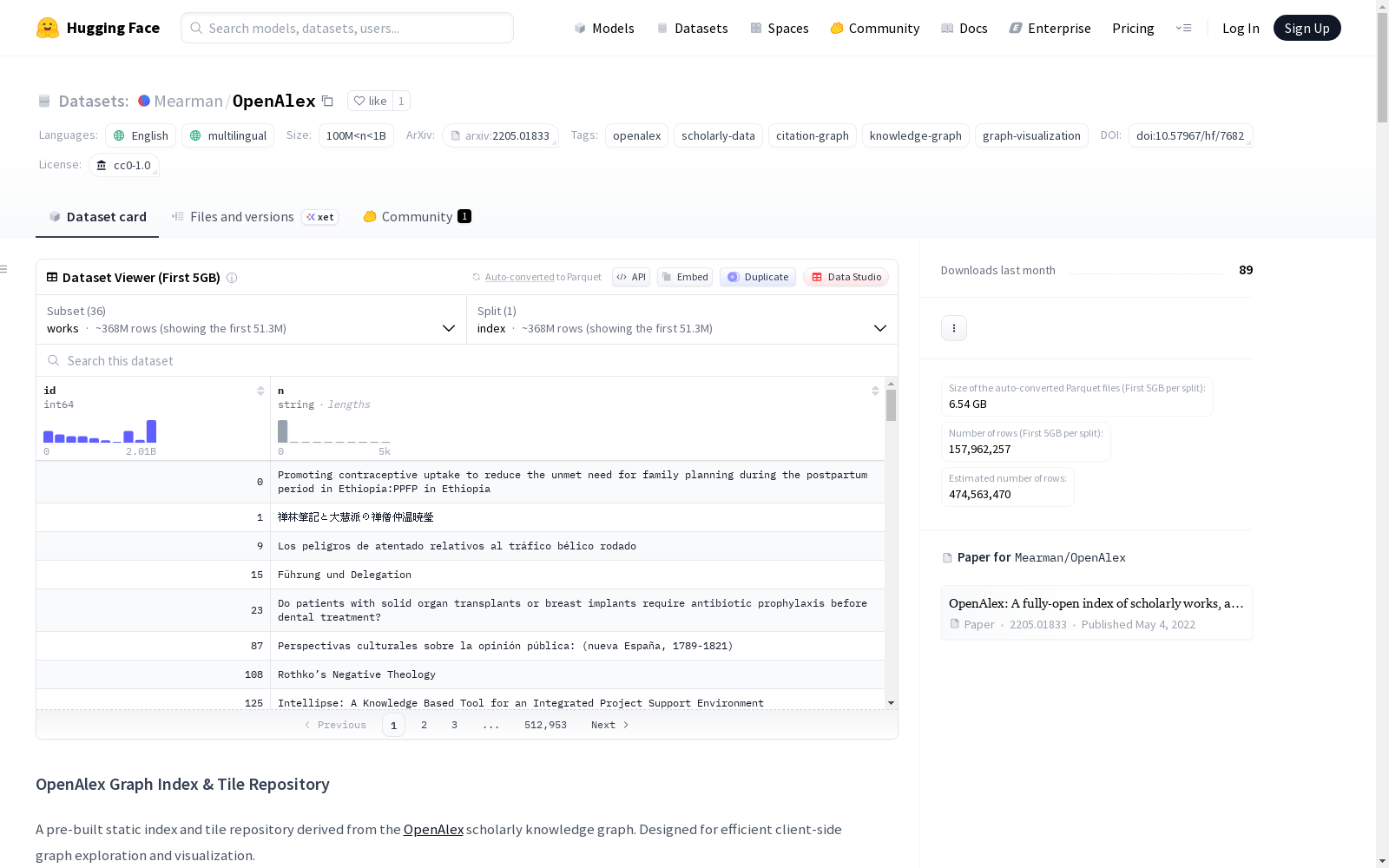
数据集基本信息
- 数据集名称: OpenAlex Dataset
- 数据集地址: https://huggingface.co/datasets/Mearman/OpenAlex
- 数据来源: 完整镜像 OpenAlex 学术知识图谱,并包含预构建的图索引和用于客户端可视化的切片存储库。
- 上游数据:
snapshot/目录是 OpenAlex S3 快照 的镜像,上游快照大约每月更新一次。 - 数据许可: 底层 OpenAlex 数据为 CC0 (公共领域) 许可。此处理后的衍生作品以相同许可发布。
- 引用信息:
Priem, J., Piwowar, H., & Orr, R. (2022). OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. ArXiv. https://arxiv.org/abs/2205.01833
数据子集与配置
快照记录 (完整的 OpenAlex 数据)
| 配置 | 拆分 | 记录数 | 描述 |
|---|---|---|---|
complete |
records |
~5.83亿 | 所有实体类型合并 |
works (默认) |
records |
~4.49亿 | 学术成果——论文、文章、书籍、数据集 |
authors |
records |
~1.08亿 | 包含隶属关系和指标的作者档案 |
institutions |
records |
~10.3万 | 大学、研究所、医院 |
sources |
records |
~25.5万 | 期刊、存储库、会议 |
topics |
records |
~4.5千 | 研究主题 (自动分类) |
subfields |
records |
252 | 学术子领域 |
fields |
records |
26 | 学术领域 |
domains |
records |
4 | 顶级领域 |
concepts |
records |
~6.5万 | 主题概念 (旧版,已被 topics 取代) |
funders |
records |
~3.2万 | 资助机构 |
publishers |
records |
~1.1万 | 出版公司 |
- 记录格式: 每条记录都是完整的 OpenAlex JSON,匹配 REST API 模式。字段因实体类型而异。
- 源文件: 来自 OpenAlex S3 快照 (2026年1月) 的 gzip 压缩 JSON Lines 文件,按日期分区存储在
snapshot/<实体>/YYYY-MM-DD/下。
图索引 (紧凑 ID)
| 配置 | 拆分 | 记录数 | 模式 | 描述 |
|---|---|---|---|---|
index |
works |
~4.49亿 | {id, n} |
紧凑整数 ID + 标题 |
authors |
~1.08亿 | {id, n} |
紧凑整数 ID + 名称 | |
institutions |
~10.3万 | {id, n} |
紧凑整数 ID + 名称 | |
sources |
~25.5万 | {id, n} |
紧凑整数 ID + 名称 | |
topics |
~4.5千 | {id, n} |
紧凑整数 ID + 名称 | |
subfields |
252 | {id, n} |
紧凑整数 ID + 名称 | |
fields |
26 | {id, n} |
紧凑整数 ID + 名称 | |
domains |
4 | {id, n} |
紧凑整数 ID + 名称 | |
concepts |
~6.5万 | {id, n} |
紧凑整数 ID + 名称 | |
funders |
~3.2万 | {id, n} |
紧凑整数 ID + 名称 | |
publishers |
~1.1万 | {id, n} |
紧凑整数 ID + 名称 |
- 描述: 由流水线生成的紧凑 ID (从0开始的整数),映射自 OpenAlex ID。供图可视化和切片系统内部使用。
实用配置
| 配置 | 拆分 | 模式 | 描述 |
|---|---|---|---|
search |
records |
{w, ids} |
倒排词索引——将小写标记映射到紧凑实体 ID |
names |
records |
{id, name} |
按紧凑 ID 键控的显示名称,为切片服务分片 |
快速开始示例
python from datasets import load_dataset
加载完整的 OpenAlex 成果记录
works = load_dataset("Mearman/OpenAlex", "works", split="records")
流式传输完整数据集 (所有实体类型,约 434 GB 压缩)
ds = load_dataset("Mearman/OpenAlex", "complete", split="records", streaming=True)
加载单个小型实体类型
topics = load_dataset("Mearman/OpenAlex", "topics", split="records")
加载作者的紧凑图索引
authors_index = load_dataset("Mearman/OpenAlex", "index", split="authors")
搜索索引
search = load_dataset("Mearman/OpenAlex", "search", split="records")
存储库结构概览
snapshot/ # 原始 OpenAlex 快照 (gzip 压缩 JSONL,按日期分区) ├── works/ # ~4.49亿学术成果 (~750 GB 压缩) ├── authors/ # ~1.08亿作者档案 (~64 GB 压缩) ├── institutions/ # 10.3万机构 ├── sources/ # 25.5万期刊/存储库 ├── concepts/ # 6.5万主题概念 ├── topics/ # 4.5千主题 ├── funders/ # 3.2万资助者 ├── publishers/ # 1.1万出版商 ├── domains/ # 4个顶级领域 ├── fields/ # 26个领域 └── subfields/ # 252个子领域
index/ ├── entities/ # 小型实体类型 (JSONL.gz: {id, n}) ├── mappings/ # 二进制 ID 映射 (OpenAlex ID → 紧凑 ID) ├── authors/ # 作者索引 (104 个分片,JSONL.gz) ├── works/ # 成果索引 (1,098 个分片,JSONL.gz) ├── edges/ # 引用 + 合作边 (邻接列表) ├── adj/ # 压缩邻接分片 └── search/ # 实体搜索的倒排词索引
layout/ ├── coords-2d.bin # 2D 力导向布局坐标 ├── coords-3d.bin # 3D 力导向布局坐标 ├── layout-2d.json # 布局元数据 ├── layout-3d.json └── density-2d.png # 4K 密度可视化
tiles/ ├── manifest.json ├── lod/{dim}d/ # 包含嵌入坐标的细节层次 ├── nodes/ # 按紧凑 ID 范围的实体元数据 ├── coords/{dim}d/ # 按紧凑 ID 范围的位置数据 ├── spatial/{dim}d/ # 空间索引 (Z-order 曲线切片) ├── edges/ # 按源紧凑 ID 范围的边切片 ├── lookup/ # 紧凑 ID ↔ OpenAlex ID 映射 ├── names/ # 显示名称分片 ├── search/ # 从 index/search 符号链接 └── adj/ # 从 index/adj 符号链接
数据处理流水线
- 下载 — 通过 rclone 同步 S3 快照
- 提取 — 使用 isal 加速的 gzip 解压
- 索引 — 并行实体索引、ID 映射、边提取、搜索索引
- 布局 — 多级粗化 + Barnes-Hut 力导向模拟 (2D 和 3D)
- 切片 — 维度无关的空间切片,用于渐进式客户端加载
当前状态
🚧 进行中 — 原始快照和索引已上传。布局和切片将在流水线作业完成后添加。