Subjects200K
收藏github2024-11-24 更新2024-11-25 收录
下载链接:
https://github.com/Yuanshi9815/Subjects200K
下载链接
链接失效反馈资源简介:
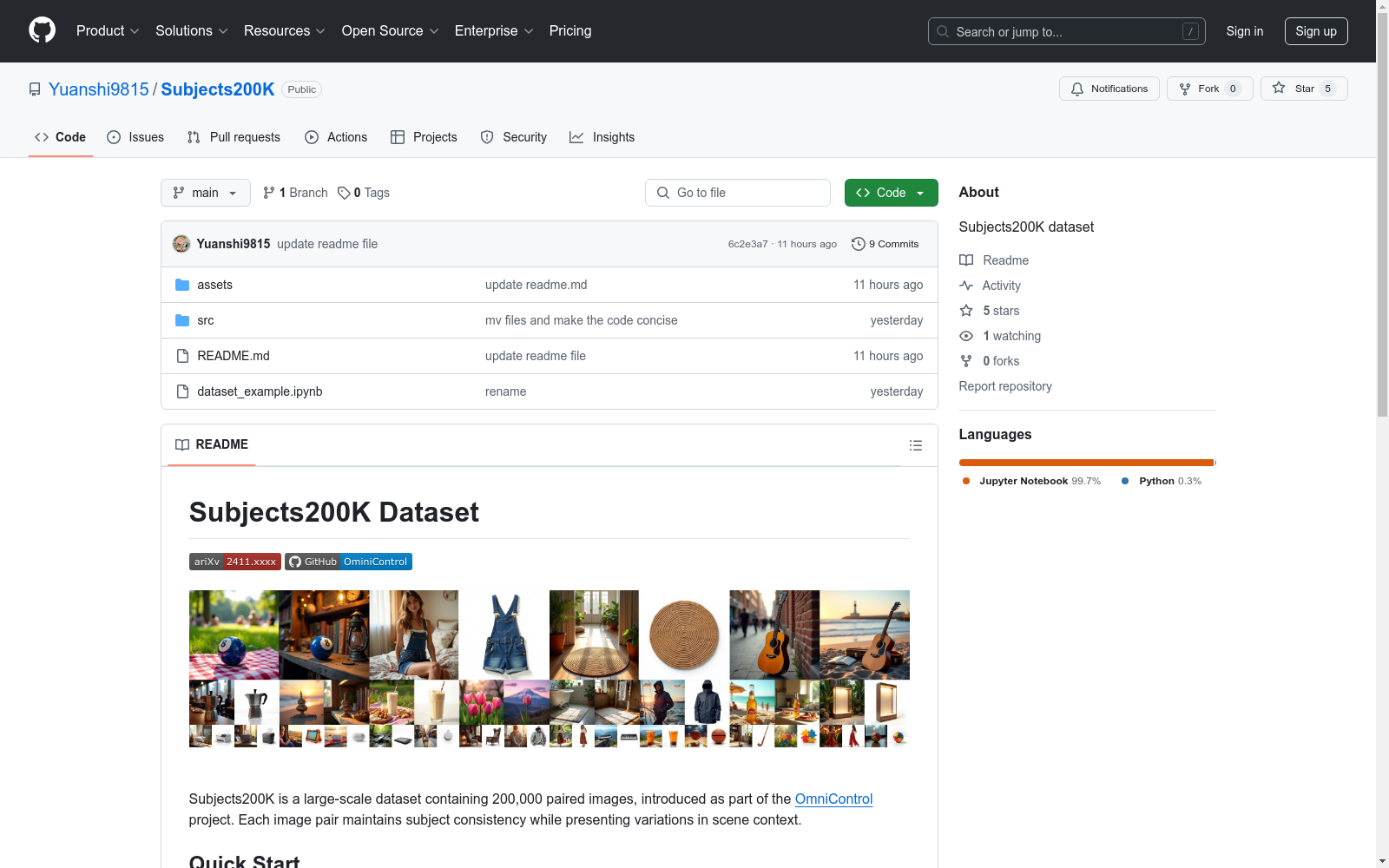
Subjects200K是一个大规模数据集,包含200,000对配对图像,作为OmniControl项目的一部分引入。每对图像在保持主体一致性的同时,展示了场景上下文的变化。
Subjects200K is a large-scale dataset comprising 200,000 matched image pairs, introduced as part of the OmniControl project. Each image pair maintains consistent core subjects while showcasing changes in the scene context.
创建时间:
2024-11-17
原始信息汇总
Subjects200K 数据集
概述
Subjects200K 是一个大规模数据集,包含 200,000 对配对图像,作为 OmniControl 项目的一部分引入。每对图像在保持主体一致性的同时,呈现场景上下文的变化。
快速开始
使用
python from src.dataset import Subjects200K
初始化数据集
dataset = Subjects200K()
访问样本
sample = dataset[0]
示例代码
dataset_example.ipynb
样本格式
每个数据点包含:
instance: 主体的简要描述image1: 左侧图像 (512x512)image2: 右侧图像 (512x512)description1: 左侧图像的文本描述description2: 右侧图像的文本描述image_pair: 组合图像 (1024x512)
贡献
欢迎贡献!请随时提交 Pull Request 或开启 Issue。
引用
@article{ tan2024omini, title={OminiControl: Minimal and Universal Control for Diffusion Transformer}, author={Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang}, journal={arXiv preprint arXiv:2411.xxxx}, year={2024} }
AI搜集汇总
数据集介绍
构建方式
Subjects200K数据集通过精心设计,包含了200,000对配对图像,这些图像在保持主体一致性的同时,展示了场景上下文的变化。每对图像均经过严格筛选,确保其在视觉和语义上的连贯性,从而为深度学习模型提供了丰富的训练素材。
特点
该数据集的显著特点在于其大规模和多样性。每对图像不仅在视觉上具有高分辨率(512x512像素),而且在文本描述上也提供了详尽的信息,有助于模型理解图像内容。此外,数据集中的图像对还通过组合图像(1024x512像素)的形式呈现,进一步增强了数据的多维度特性。
使用方法
使用Subjects200K数据集时,用户可以通过简单的Python代码进行初始化和访问。例如,通过导入数据集类并初始化实例,用户可以轻松获取样本数据。数据集的每个数据点包含主体描述、左右图像及其对应的文本描述,以及组合图像,为模型训练和评估提供了全面的数据支持。
背景与挑战
背景概述
Subjects200K数据集是由OmniControl项目引入的大规模图像数据集,包含200,000对配对图像。该数据集由Zhenxiong Tan、Songhua Liu、Xingyi Yang、Qiaochu Xue和Xinchao Wang等研究人员于2024年创建,旨在支持扩散变换器的通用控制研究。每对图像在保持主体一致性的同时,展示了场景上下文的变化,这对于理解图像间的关系和进行图像分类、识别等任务具有重要意义。Subjects200K的引入,不仅丰富了图像数据集的多样性,也为相关领域的研究提供了新的视角和工具。
当前挑战
Subjects200K数据集在构建过程中面临的主要挑战包括:首先,确保每对图像在主体一致性的同时,场景上下文的变化足够显著,这需要精确的图像处理和配对算法。其次,数据集的规模庞大,如何高效地存储和访问这些数据,以及如何确保数据的质量和一致性,都是需要解决的技术难题。此外,该数据集的应用领域广泛,从图像分类到场景理解,每个领域都有其特定的需求和挑战,如何在不同应用场景中有效利用这一数据集,也是研究人员需要深入探讨的问题。
常用场景
经典使用场景
在计算机视觉领域,Subjects200K数据集的经典使用场景主要集中在图像对齐与场景理解任务中。该数据集通过提供200,000对具有相同主体但场景上下文不同的图像,为研究人员提供了一个丰富的资源,用于训练和评估图像匹配、场景迁移以及视觉语义理解等模型。例如,研究人员可以利用这些图像对来开发能够识别和跟踪不同场景中同一主体的算法,从而提升视觉系统的鲁棒性和准确性。
解决学术问题
Subjects200K数据集解决了计算机视觉领域中关于场景变化下主体一致性识别的学术问题。通过提供大量具有相同主体但场景不同的图像对,该数据集为研究者提供了一个理想的平台,用于探索和验证在复杂场景变化下保持主体识别一致性的算法。这不仅推动了图像匹配和场景理解技术的发展,还为视觉系统的实际应用提供了理论支持和技术保障。
衍生相关工作
Subjects200K数据集的发布催生了多项相关经典工作,特别是在图像对齐和场景理解领域。例如,基于该数据集的研究工作已经提出了多种图像匹配和场景迁移算法,显著提升了模型在复杂场景变化下的表现。此外,该数据集还被广泛应用于视觉语义理解任务中,推动了相关算法的创新和发展。这些衍生工作不仅丰富了计算机视觉领域的研究内容,也为实际应用提供了强有力的技术支持。
以上内容由AI搜集并总结生成


