Assemblee17
收藏Hugging Face2025-10-25 更新2025-10-26 收录
下载链接:
https://huggingface.co/datasets/Legibot106/Assemblee17
下载链接
链接失效反馈官方服务:
资源简介:
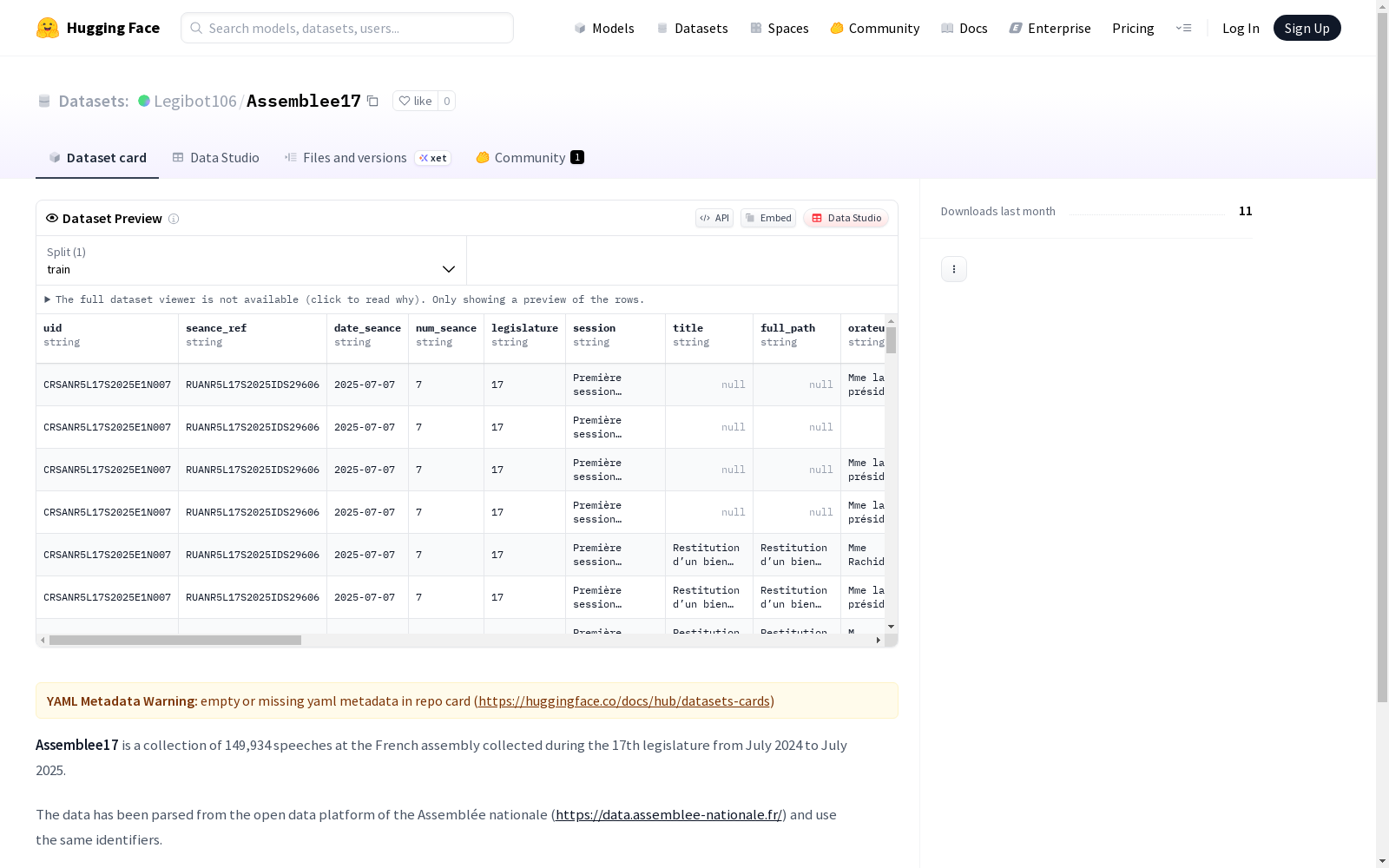
Assemblee17是一个包含从2024年7月至2025年7月第17届立法期间法国议会的149,934次演讲的数据集。数据来源于国民议会的开放数据平台,并且提供了演讲者数据与Wikidata的对齐,允许进一步注入演讲者的传记信息。
Assemblee17 is a dataset consisting of 149,934 speeches delivered in the French National Assembly during its 17th legislative session, spanning from July 2024 to July 2025. The dataset is sourced from the open data platform of the French National Assembly, and includes alignment between speaker records and Wikidata, enabling further integration of speakers' biographical information.
创建时间:
2025-10-24
原始信息汇总
Assemblee17 数据集概述
数据集基本信息
- 数据集名称:Assemblee17
- 数据规模:包含149,934篇法国国民议会演讲
- 时间范围:第17届立法会议期间(2024年7月至2025年7月)
数据来源与处理
- 原始数据源:法国国民议会开放数据平台(https://data.assemblee-nationale.fr/)
- 数据标识:采用与原始数据平台相同的标识符
- 数据增强:提供演讲者与Wikidata的关联匹配(wikidata_id),支持多种传记变量的注入
数据特征
- 内容类型:议会演讲记录
- 地理范围:法国
- 语言:法语
- 数据更新:覆盖完整立法年度数据
搜集汇总
数据集介绍
构建方式
在法国政治话语研究领域,Assemblee17数据集的构建体现了对公开政务数据的系统性整合。该数据集源自法国国民议会开放数据平台,通过自动化解析技术提取了第十七届立法会议期间的全部149,934条议会发言记录。每项数据均保留原始平台的标准标识符,并创新性地通过维基数据实体链接技术,实现了发言者身份与知识库的精准关联。
特点
该数据集最显著的特征在于其时空维度的完整性,完整覆盖2024至2025年立法周期的议会辩论全貌。通过引入维基数据关联机制,不仅保留了原始发言的文本内容,更拓展出包含发言人背景信息的多维数据网络。这种设计使得政治立场分析能够结合发言者的社会属性,为政治语言学研究者提供了立体化的观察视角。
使用方法
研究者可通过标准数据接口直接调用该数据集,利用内置的跨平台标识符实现与法国议会原始数据的对照验证。基于维基数据关联特性,用户可灵活注入人口统计学变量或政治背景参数,构建定制化的政治话语分析模型。该数据集特别适用于计算社会科学领域,能够支撑从文本情感分析到政治网络演化等多种研究范式。
背景与挑战
背景概述
法国国民议会第十七届立法会议期间(2024年7月至2025年7月)构建的Assemblee17数据集,收录了149,934条议会演讲记录,由国民议会开放数据平台提供原始资料。该数据集通过数据解析技术将演讲者信息与维基数据知识库进行实体关联,为政治语言学与立法行为研究提供了结构化语料支撑。其核心价值在于打通了立法文本与外部知识图谱的壁垒,使研究者能够结合演讲者背景特征开展多维度的政治话语分析。
当前挑战
在政治文本分析领域,如何从海量议会演讲中提取有效语义特征始终是核心难题。Assemblee17需解决演讲内容与非结构化政治语境的关联问题,包括政党立场推导、修辞策略识别等任务。数据构建过程中面临原始数据异构性挑战,需设计专用解析器处理国民议会平台的复杂文档结构;实体链接环节需克服姓名歧义与跨语言实体对齐的技术障碍,确保wikidata_id映射的准确性。
常用场景
经典使用场景
在政治语言学与社会科学研究中,Assemblee17数据集常被用于分析法国国民议会的演讲模式与立法辩论动态。研究者通过自然语言处理技术,系统性地考察议员的发言内容、情感倾向及修辞策略,揭示政治话语中的意识形态差异与共识形成机制。
实际应用
实际应用中,政府机构与民间组织借助该数据集开发政策分析工具,实时监测立法议程的关键议题演变。新闻媒体则利用其构建事实核查系统,追踪政治承诺的履行轨迹,增强公共舆论监督的精准度与时效性。
衍生相关工作
基于此数据集衍生的经典工作包括议会演讲生成模型构建、跨党派联盟预测算法开发,以及多语言政治话语对比研究。这些成果显著拓展了计算政治学的研究边界,为全球立法机构数字化建设提供了范式参考。
以上内容由遇见数据集搜集并总结生成


