CKnowEdit
收藏CKnowEdit: A Chinese Knowledge Editing Dataset for Large Language Models
Dataset Structure
CKnowEdit is categorized into 4 classes:
- Chinese literary knowledge
- Chinese linguistic knowledge
- Chinese geographical knowledge
- Chinese Ruozhiba
The file structure is as follows:
CknowEdit ├── Chinese Literary Knowledge │ ├── Ancient Poetry │ ├── Proverbs │ └── Idioms ├── Chinese Linguistic Knowledge │ ├── Phonetic Notation │ └── Classical Chinese ├── Chinese Geographical Knowledge └── Ruozhiba
Data types and their distribution:
| type | quantity |
|---|---|
| Ancient Poetry | 134 |
| Proverbs | 230 |
| Idioms | 101 |
| Phonetic Notation | 153 |
| Classical Chinese | 234 |
| Chinese Geographical Knowledge | 105 |
| Ruozhiba | 803 |
Dataset Description
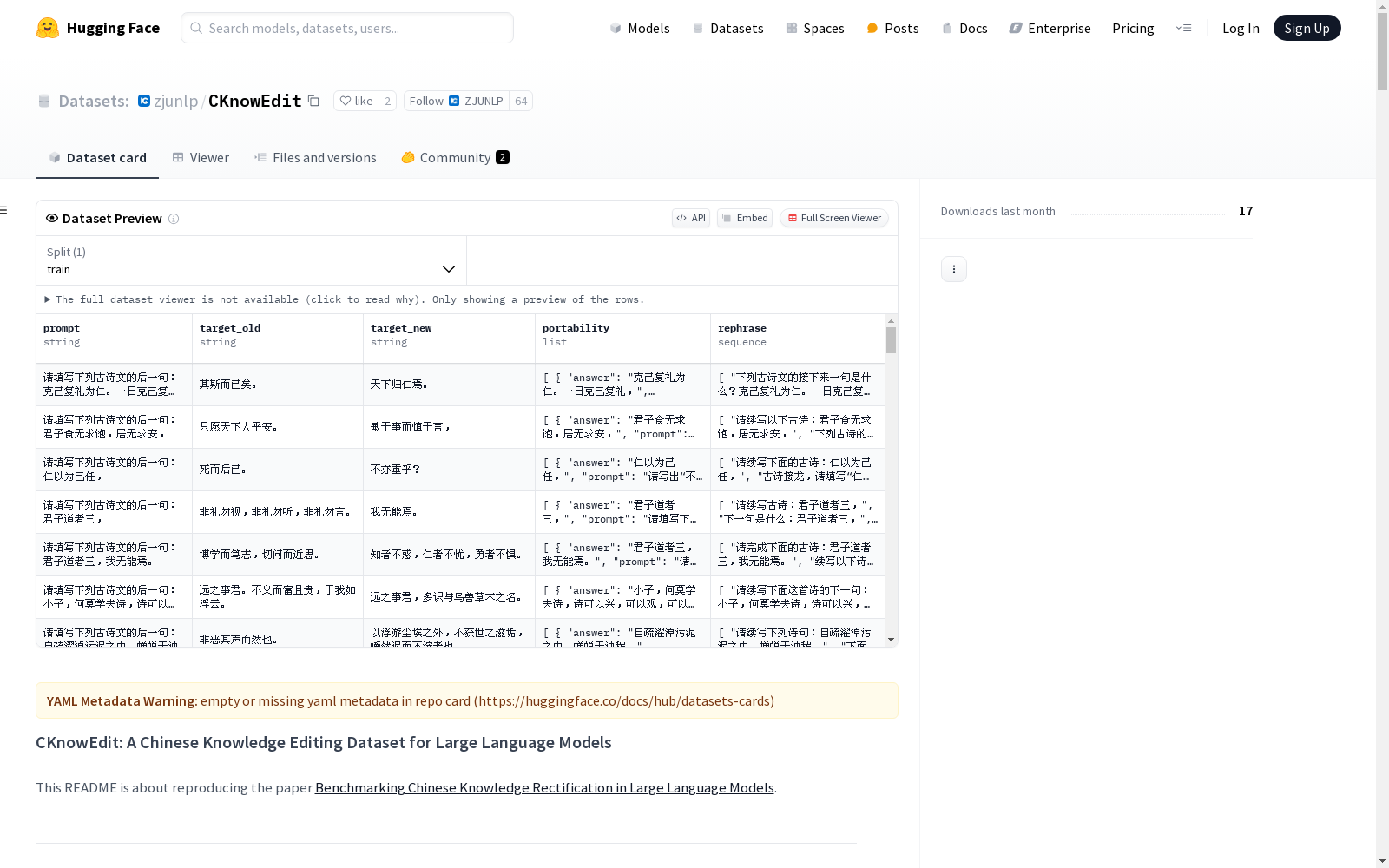
CKnowEdit is a high-quality Chinese-language dataset for knowledge editing, sourced from Chinese knowledge bases. The data fields are:
python "prompt": str "target_old": str "target_new": str "portability_prompt": list or None "portability_answer": list or None "locality_prompt": list or None "locality_answer": list or None "rephrase": list
Examples
Chinese Literary Knowledge
json { "prompt": "请填写下列古诗文的后一句:克己复礼为仁。一日克己复礼,", "target_old": "其斯而已矣。", "target_new": "天下归仁焉。", "portability": [ { "prompt": "请填写下列古诗文的前一句:天下归仁焉。", "answer": "克己复礼为仁。一日克己复礼," } ], "rephrase": [ "下列古诗文的接下来一句是什么?克己复礼为仁。一日克己复礼,", "古诗文中,“克己复礼为仁。一日克己复礼,”的下一句是什么?", "完成这段古诗:克己复礼为仁。一日克己复礼,______。" ] }
Chinese Linguistic Knowledge
json { "prompt": "请给下面的字注音:莘庄", "target_old": "莘庄的拼音是:“shēn zhuāng”", "target_new": "莘庄的注音是:xīn zhuāng", "portability": [ { "prompt": "请给下面的字注音:细莘", "answer": "细莘的注音是:xì xīn" } ], "locality": [ { "prompt": "请给下面的字注音:莘莘学子", "answer": "莘莘学子的注音是:shēn shēn xué zǐ" } ], "rephrase": [ "请问莘庄的正确拼音是什么?", "莘庄正确的注音怎么写?", "请注音:莘庄。", "莘庄的拼音应该怎么表示?" ] }
Chinese Geographical Knowledge
json { "prompt": "请说出中国领土的最南端", "target_old": "中国的最南端位于海南省三沙市永兴岛,地处北纬15°03′、东经112°47′。", "target_new": "曾母暗沙", "portability": [ { "prompt": "中国最南端的地理位置会影响哪些海洋?", "answer": "南海" }, { "prompt": "位于中国最南端的地点在哪个省的管辖之下?", "answer": "海南省" }, { "prompt": "中国最南端的地点属于哪个市?", "answer": "三沙市" } ], "rephrase": [ "中国最南端是哪里?", "中国领土南端的最远点在哪?" ] }
Ruozhiba
json { "prompt": "蓝牙耳机坏了,去医院挂牙科还是耳科?", "target_old": "如果你的蓝牙耳机有问题,你应该去耳科或者听力诊所。", "target_new": "如果您的蓝牙耳机出现问题,这实际上涉及的是电子设备维修,而不是医疗问题。因此,您应该去电子产品维修店或联系耳机厂商的客服,而不是去医院挂耳科或牙科。医院的科室是用来处理人体健康问题的,与电子产品维修无关。", "portability": [ { "prompt": "我的无线耳机不工作了,我应该去哪里修理?", "answer": "无线耳机的问题应该去电子产品维修店或联系耳机的生产厂家客服进行咨询和修理。" }, { "prompt": "手表无法充电,我需要去医院看病吗?", "answer": "手表无法充电这是电子产品的问题,需要去电子维修点或联系生产厂商,并非医疗问题。" }, { "prompt": "我的手机屏幕碎了,应该去牙科还是手机维修店?", "answer": "手机屏幕碎了应该去手机维修店进行修理,这与牙科无关。" } ], "locality": [ { "prompt": "如果我耳朵痛,我应该去哪里?", "answer": "如果耳朵疼痛,您应该去医院的耳科进行检查和治疗。" }, { "prompt": "牙齿疼痛需要去哪个科室?", "answer": "牙齿疼痛应该去医院的牙科进行检查和治疗。" } ], "rephrase": [ "蓝牙耳机损坏不工作了,我是应该去牙科还是耳科处理?", "我的耳机坏了,这种情况我是应该预约牙科还是耳科?" ] }
Evaluation
Evaluation metrics include:
Edit_accportabilitylocalityfluency
Evaluation methods:
- Word-level overlap metric: Using rouge-l to compare rewrite_ans and target_new, portability_ans and portabilitypor_hopground_truth, locality_ans and localityloc_hopground_truth.
- Semantic similarity: Using cosine similarity of embeddings from paraphrase-multilingual-MiniLM-L12-v2.
Baseline
Results of 4 knowledge editing methods on Qwen-7b-chat/Baichuan2-7b-chat:
| Knowledge Type | Method | Edit Success | Portability | Locality | Fluency |
|---|---|---|---|---|---|
| Ancient Poetry | FT-M | 42.10 / 55.32 | 32.50 / 31.78 | - | 387.81 / 400.52 |
| AdaLoRA | 80.38 / 78.77 | 32.23 / 33.19 | - | 419.92 / 430.99 | |
| ROME | 54.87 / 36.12 | 33.12 / 28.64 | - | 464.68 / 455.98 | |
| GRACE | 39.40 / 40.38 | 31.83 / 31.84 | - | 408.47 / 336.47 | |
| Proverbs | FT-M | 44.53 / 58.30 | 48.26 / 49.26 | - | 438.17 / 383.77 |
| AdaLoRA | 64.62 / 67.06 | 49.66 / 52.69 | - | 397.37 / 415.88 | |
| ROME | 63.96 / 59.31 | 47.99 / 50.31 | - | 445.30 / 431.78 | |
| GRACE | 44.22 / 46.30 | 48.41 / 49.76 | - | 395.65 / 336.65 | |
| Idioms | FT-M | 49.01 / 60.39 | 51.94 / 53.06 | - | 446.24 / 407.95 |
| AdaLoRA | 66.29 / 74.90 | 55.26 / 56.63 | - | 430.25 / 432.79 | |
| ROME | 64.79 / 60.81 | 52.47 / 56.30 | - | 457.38 / 441.57 | |
| GRACE | 47.58 / 52.26 | 52.50 / 53.06 | - | 408.56 / 381.15 | |
| Phonetic Notation | FT-M | 78.04 / 68.34 | 72.28 / 64.46 | 82.17 / 61.29 | 475.13 / 387.05 |
| AdaLoRA | 88.21 / 80.87 | 76.37 / 67.36 | 74.94 / 62.62 | 404.06 / 469.75 | |
| ROME | 77.15 / 65.58 | 73.14 / 61.88 | 80.52 / 62.19 | 486.19 / 462.08 | |
| GRACE | 76.63 / 67.04 | 72.71 / 66.36 | 81.96 / 65.41 | 479.89 / 458.02 | |
| Classical Chinese | FT-M | 42.79 / 73.22 | 48.25 / 53.58 | 57.78 / 33.83 | 430.29 / 269.34 |
| AdaLoRA | 65.17 / 55.89 | 52.32 / 45.94 | 44.57 / 44.13 | 286.61 / 330.09 | |
| ROME | 39.28 / 28.06 | 50.00 / 35.37 | 50.20 / 35.37 | 431.48 / 422.80 | |
| GRACE | 37.92 / 32.97 | 50.63 / 35.67 | 56.55 / 52.90 | 418.28 / 408.85 | |
| Geographical Knowledge | FT-M | 47.30 / 73.02 | 45.75 / 47.15 | - | 448.90 / 260.36 |
| AdaLoRA | 70.31 / 72.44 | 52.60 / 55.14 | - | 313.19 / 377.91 | |
| ROME | 52.81 / 49.64 | 43.89 / 42.85 | - | 402.51 / 408.85 | |
| GRACE | 46.53 / 53.38 | 43.59 / 42.85 | - | 408.97 / 311.22 | |
| Ruozhiba | FT-M | 45.25 / 43.22 | 57.79 / 57.39 | 63.92 / 64.09 | 333.98 / 414.30 |
| AdaLoRA | 71.07 / 51.54 | 62.25 / 55.65 | 66.57 / 66.13 | 428.94 / 441.41 | |
| ROME | 68.42 / 62.88 | 60.35 / 61.23 | 68.91 / 70.19 | 413.37 / 428.03 | |
| GRACE | 45.16 / 39.83 | 56.47 / 56.86 | 63.41 / 63.97 | 452.39 / 442.60 |