rafaelpadilla/coco2017
收藏Hugging Face2023-08-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/rafaelpadilla/coco2017
下载链接
链接失效反馈官方服务:
资源简介:
COCO(Common Objects in Context)是一个大规模的目标检测、分割和图像描述数据集。它包含超过20万张标注图像,涵盖80多个类别标签。数据集涵盖了复杂日常场景中的常见物体,并将它们置于自然环境中。该数据集仅包含COCO数据集的“目标检测”部分,但提供了完整COCO数据集的一些特征和规格,包括目标分割、上下文识别、超像素分割、330K图像(>200K标注)、150万个目标实例、80个目标类别、91个物品类别、每张图像5个描述以及25万个带关键点的人。
COCO(Common Objects in Context)是一个大规模的目标检测、分割和图像描述数据集。它包含超过20万张标注图像,涵盖80多个类别标签。数据集涵盖了复杂日常场景中的常见物体,并将它们置于自然环境中。该数据集仅包含COCO数据集的“目标检测”部分,但提供了完整COCO数据集的一些特征和规格,包括目标分割、上下文识别、超像素分割、330K图像(>200K标注)、150万个目标实例、80个目标类别、91个物品类别、每张图像5个描述以及25万个带关键点的人。
提供机构:
rafaelpadilla
原始信息汇总
数据集概述
名称: COCO2017
描述: COCO2017是一个专注于对象检测的大型数据集,包含超过200,000张标注图像,涵盖80个类别标签。该数据集主要用于复杂日常场景中的对象检测任务。
数据集详细信息
- 数据集大小: 100K<n<1M
- 语言: 英语
- 任务类别: 对象检测
- 数据集组成部分:
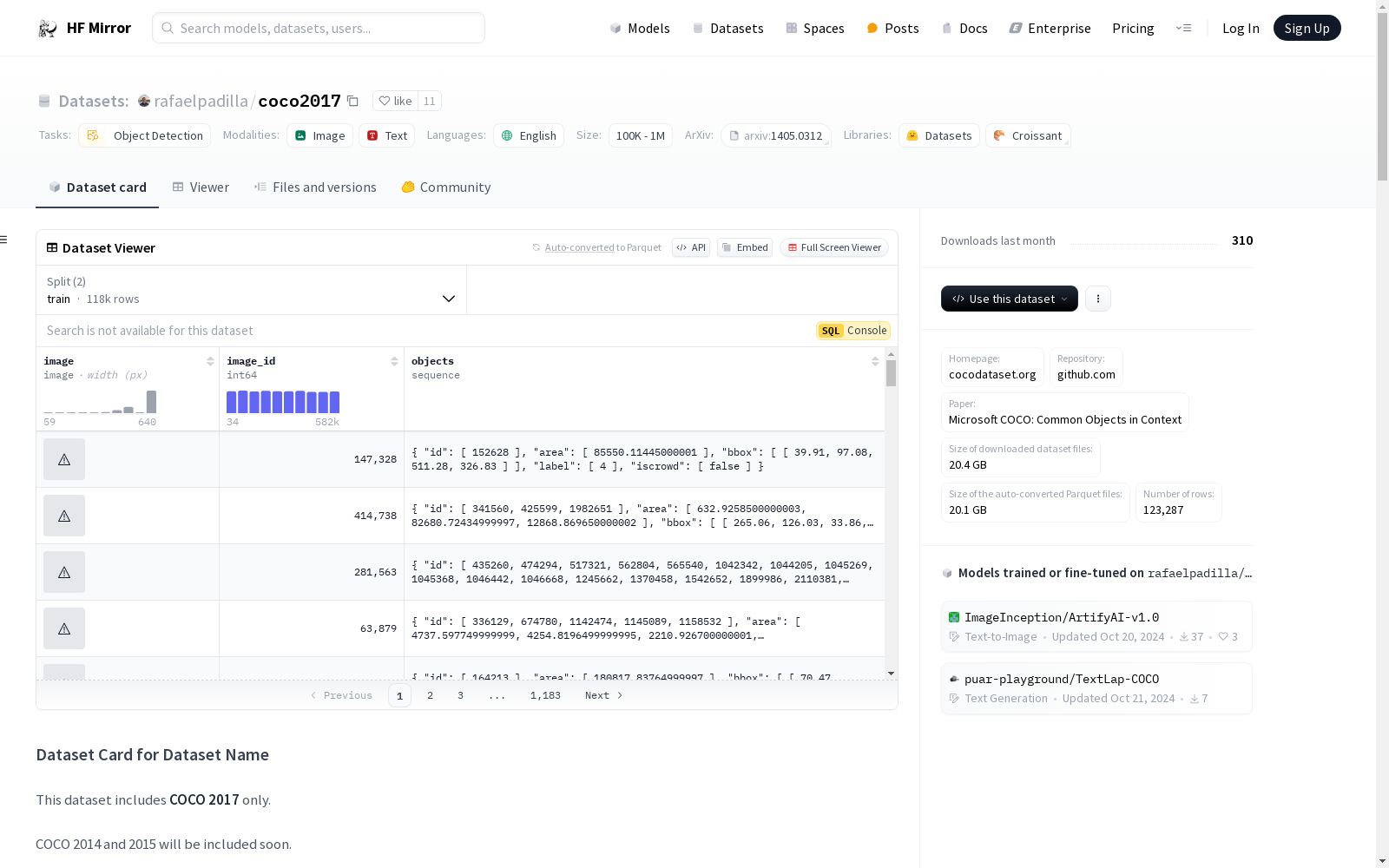
- 训练集: 包含118,287张图像,共计860,001个边界框。
- 验证集: 包含5,000张图像,共计36,781个边界框。
- 类别: 包含80个类别,如人、自行车、汽车等。
- 边界框格式: 格式为
x, y, width, height,使用绝对坐标。
数据集使用
- 加载数据集: 可通过
from datasets import load_dataset加载,支持全数据集、训练集和验证集的加载。 - 数据集类: 提供
COCODataset类,需通过安装coco2017包使用。
许可证信息
- 许可证: 数据集注释属于COCO Consortium,根据Creative Commons Attribution 4.0 License授权。
贡献者
- Tsung-Yi Lin, Google Brain
- Genevieve Patterson, MSR, Trash TV
- Matteo R. Ronchi, Caltech
- Yin Cui, Google
- Michael Maire, TTI-Chicago
- Serge Belongie, Cornell Tech
- Lubomir Bourdev, WaveOne, Inc.
- Ross Girshick, FAIR
- James Hays, Georgia Tech
- Pietro Perona, Caltech
- Deva Ramanan, CMU
- Larry Zitnick, FAIR
- Piotr Dollár, FAIR
搜集汇总
数据集介绍
构建方式
COCO2017数据集是基于专家标注的大规模图像数据集,专注于目标检测任务。该数据集通过精心挑选的日常场景图像,涵盖了超过200,000张标注图像,包含80个常见物体类别。每张图像均经过详细标注,提供了物体的边界框信息,确保数据的高质量和多样性。数据集的构建过程严格遵循科学标准,旨在为计算机视觉领域的研究提供坚实的基础。
使用方法
COCO2017数据集可通过Hugging Face的`datasets`库轻松加载。用户可以通过调用`load_dataset`函数加载完整数据集或特定子集(如训练集或验证集)。加载后的数据集以`DatasetDict`形式呈现,包含图像、图像ID和物体标注信息。此外,用户还可以通过安装`coco2017`包并使用`COCODataset`类,进一步扩展数据集的功能,以满足更复杂的计算机视觉任务需求。
背景与挑战
背景概述
COCO2017数据集由微软研究院于2014年首次发布,旨在推动计算机视觉领域的研究进展,特别是在目标检测、分割和图像描述等任务中。该数据集由Tsung-Yi Lin等研究人员主导开发,涵盖了超过20万张标注图像,包含80个常见物体类别。COCO数据集以其丰富的上下文信息和复杂的场景设计著称,成为计算机视觉领域最具影响力的基准数据集之一。其广泛的应用场景包括自动驾驶、智能监控和图像理解等,极大地推动了深度学习模型在视觉任务中的性能提升。
当前挑战
COCO2017数据集在解决目标检测问题时面临的主要挑战包括复杂场景下的物体识别、遮挡物体的检测以及小目标检测的准确性。由于数据集中的图像多为日常场景,物体之间的遮挡和重叠现象频繁,增加了模型训练的难度。此外,构建过程中,研究人员需处理大量图像数据的标注工作,确保标注的准确性和一致性,尤其是在物体边界模糊或部分遮挡的情况下。数据集的多样性和复杂性也带来了计算资源的巨大需求,尤其是在训练大规模深度学习模型时,如何高效处理海量数据成为一大挑战。
常用场景
经典使用场景
COCO2017数据集在计算机视觉领域中被广泛用于对象检测任务。其包含超过20万张标注图像,涵盖了80个常见物体类别,适用于训练和验证深度学习模型。该数据集通过提供复杂的日常场景图像,帮助研究人员在自然环境中识别和定位物体,推动了对象检测技术的发展。
解决学术问题
COCO2017数据集解决了计算机视觉领域中对象检测的多个关键问题。通过提供丰富的标注数据,研究人员能够训练更精确的模型,提升物体识别和定位的准确性。此外,该数据集还支持图像分割、关键点检测等任务,为多任务学习提供了坚实的基础,推动了视觉理解技术的进步。
实际应用
COCO2017数据集在实际应用中具有广泛的价值。例如,在自动驾驶领域,该数据集可用于训练车辆识别行人、交通标志和其他车辆的能力。在智能监控系统中,它可以帮助识别异常行为或特定物体。此外,该数据集还被用于增强现实和机器人技术中,提升设备对环境的感知和理解能力。
数据集最近研究
最新研究方向
在计算机视觉领域,COCO2017数据集作为大规模对象检测、分割和图像描述任务的重要基准,持续推动着深度学习模型的发展。近年来,基于COCO2017的研究热点主要集中在多任务学习、弱监督学习以及自监督学习等方向。多任务学习通过联合优化对象检测、分割和关键点检测等任务,显著提升了模型的泛化能力。弱监督学习则利用部分标注数据,降低了对大规模精确标注的依赖,为实际应用提供了更高效的解决方案。此外,自监督学习通过设计预训练任务,充分利用未标注数据,进一步提升了模型在复杂场景下的表现。这些研究方向不仅推动了计算机视觉技术的进步,也为自动驾驶、智能监控等实际应用场景提供了强有力的支持。
以上内容由遇见数据集搜集并总结生成


