HoloBench
收藏arXiv2024-10-16 更新2024-10-18 收录
下载链接:
https://hf.co/datasets/megagonlabs/holobench
下载链接
链接失效反馈官方服务:
资源简介:
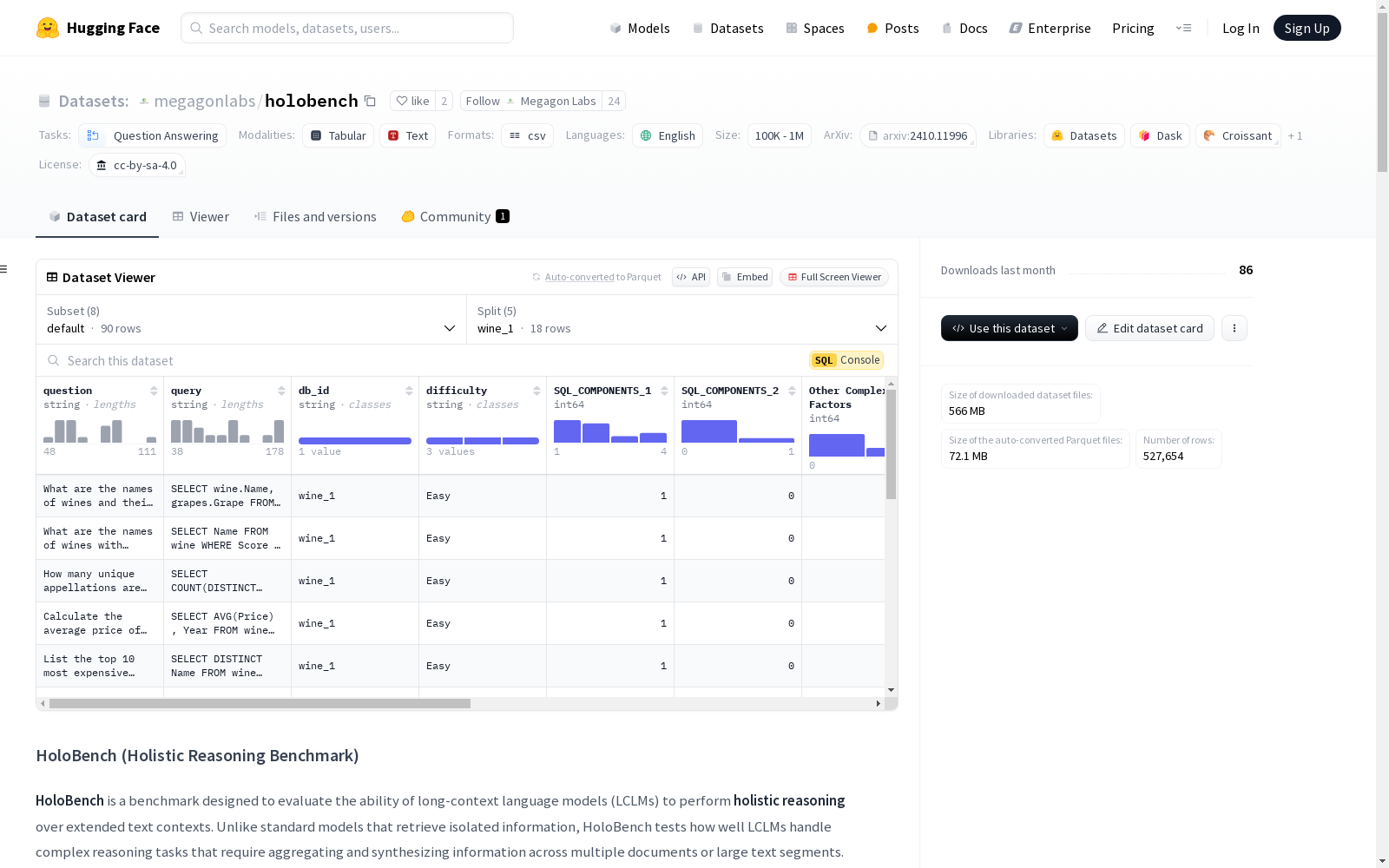
HoloBench是由Megagon Labs创建的一个用于评估长上下文语言模型(LCLMs)在处理大规模文本数据时进行整体推理能力的新型基准框架。该数据集包含90个问题,涵盖了从简单到复杂的多种查询类型,旨在测试模型在不同信息密度、分布和查询复杂度下的表现。HoloBench通过将数据库推理操作引入文本上下文,实现了对LCLMs在长文本中进行信息聚合、比较和推理能力的系统评估。该数据集的应用领域主要集中在需要多文档综合、比较分析和跨大量数据集进行上下文整合的任务,旨在解决传统检索增强生成模型在复杂跨文档任务中的局限性。
HoloBench is a novel benchmark framework created by Megagon Labs for evaluating the holistic reasoning capabilities of long-context language models (LCLMs) when processing large-scale text data. This dataset includes 90 questions covering diverse query types ranging from simple to complex, aiming to test model performance under varying information density, distribution and query complexity. HoloBench introduces database reasoning operations into textual contexts, enabling systematic evaluation of LCLMs' abilities to conduct information aggregation, comparison and reasoning within long texts. Its application fields mainly focus on tasks requiring multi-document synthesis, comparative analysis and context integration across large-scale datasets, with the goal of addressing the limitations of traditional retrieval-augmented generation models in complex cross-document tasks.
提供机构:
Megagon Labs
创建时间:
2024-10-16
搜集汇总
数据集介绍
构建方式
HoloBench的构建基于文本到SQL基准的调整,旨在评估长上下文语言模型(LCLMs)在处理大规模文本数据时的整体推理能力。该框架通过数据库推理操作创建复杂的推理任务,要求模型在广泛上下文中聚合和综合信息。HoloBench的关键创新在于其能够控制三个影响LCLM性能的关键因素:上下文长度、信息密度和信息位置,以及查询的类型和难度。这些因素使得HoloBench能够全面评估LCLMs的整体推理能力。
使用方法
HoloBench的使用方法包括首先加载数据集,然后根据需要调整上下文长度、信息密度和查询复杂性等参数。用户可以通过执行SQL查询来生成自然语言问题,并使用LCLMs生成答案。随后,通过比较模型生成的答案与金标准答案,可以评估模型的整体推理能力。HoloBench还提供了详细的实验设置和评估指标,帮助用户全面了解模型在不同条件下的表现。
背景与挑战
背景概述
HoloBench,由Megagon Labs的Seiji Maekawa、Hayate Iso和Nikita Bhutani等人于2024年引入,旨在评估长上下文语言模型(LCLMs)在处理大规模文本数据时的整体推理能力。随着文本信息的快速增长,传统的检索增强生成(RAG)模型在处理需要跨多个文档的信息聚合和推理的复杂任务时表现不佳。HoloBench通过将数据库推理操作引入文本上下文,系统地评估LCLMs在长文档中的整体推理能力,填补了现有基准在这一领域的空白。
当前挑战
HoloBench面临的挑战包括:1) 解决复杂任务中的整体推理问题,如跨文档的信息聚合和推理;2) 构建过程中需要控制上下文长度、信息密度、信息分布和查询复杂度等多个关键因素。实验结果表明,信息量对模型性能的影响大于上下文长度,且查询复杂度对性能的影响尤为显著,特别是在需要聚合多条信息的任务中。此外,信息在文本中的位置也对模型性能有显著影响,不同模型对信息位置的偏好不同。
常用场景
经典使用场景
HoloBench 数据集的经典使用场景在于评估长上下文语言模型(LCLMs)在处理大规模文本数据时的整体推理能力。通过模拟数据库操作,HoloBench 能够系统地测试模型在跨多个文档的信息聚合、比较和推理任务中的表现。例如,模型可能被要求回答诸如“哪家公司雇佣了最多的人?”这样的问题,这需要模型从多个文档中提取信息并进行综合分析。
解决学术问题
HoloBench 数据集解决了在评估长上下文语言模型(LCLMs)整体推理能力方面的常见学术研究问题。传统上,检索增强生成(RAG)模型在处理局部上下文时表现出色,但在需要跨文档综合推理的任务中表现不佳。HoloBench 通过引入数据库推理操作,填补了这一空白,为研究人员提供了一个系统化的框架来全面评估 LCLMs 在复杂多文档任务中的能力,推动了语言模型在处理大规模文本数据方面的研究进展。
实际应用
HoloBench 数据集在实际应用中具有广泛的前景,特别是在需要处理和分析大规模文本数据的领域。例如,在法律、金融和医疗等行业中,分析师可能需要从大量文档中提取和综合信息以做出决策。HoloBench 提供了一个基准,帮助开发更强大的语言模型,这些模型能够高效地处理复杂的查询和多文档推理任务,从而提高这些行业的数据处理效率和决策质量。
数据集最近研究
最新研究方向
HoloBench 数据集的最新研究方向集中在评估长上下文语言模型(LCLMs)在处理大规模文本数据时的整体推理能力。研究通过引入数据库推理操作到文本环境中,系统地评估 LCLMs 在跨多个文档的信息聚合和推理任务中的表现。实验结果表明,上下文中的信息量比上下文长度对模型性能的影响更大,且查询复杂性对性能的影响超过信息量。此外,研究还发现,尽管分组相关信息通常能提高性能,但不同模型的最佳信息定位策略各异。这些发现不仅揭示了 LCLMs 在长上下文理解中的进展和挑战,也为未来开发更强大的语言模型提供了指导。
相关研究论文
- 1Holistic Reasoning with Long-Context LMs: A Benchmark for Database Operations on Massive Textual DataMegagon Labs · 2024年
以上内容由遇见数据集搜集并总结生成


