中文普通话朗读音频数据集
收藏魔搭社区2025-12-22 更新2024-08-31 收录
下载链接:
https://modelscope.cn/datasets/Magic_Data/Mandarin_Chinese_Scripted_Speech_Corpus
下载链接
链接失效反馈官方服务:
资源简介:
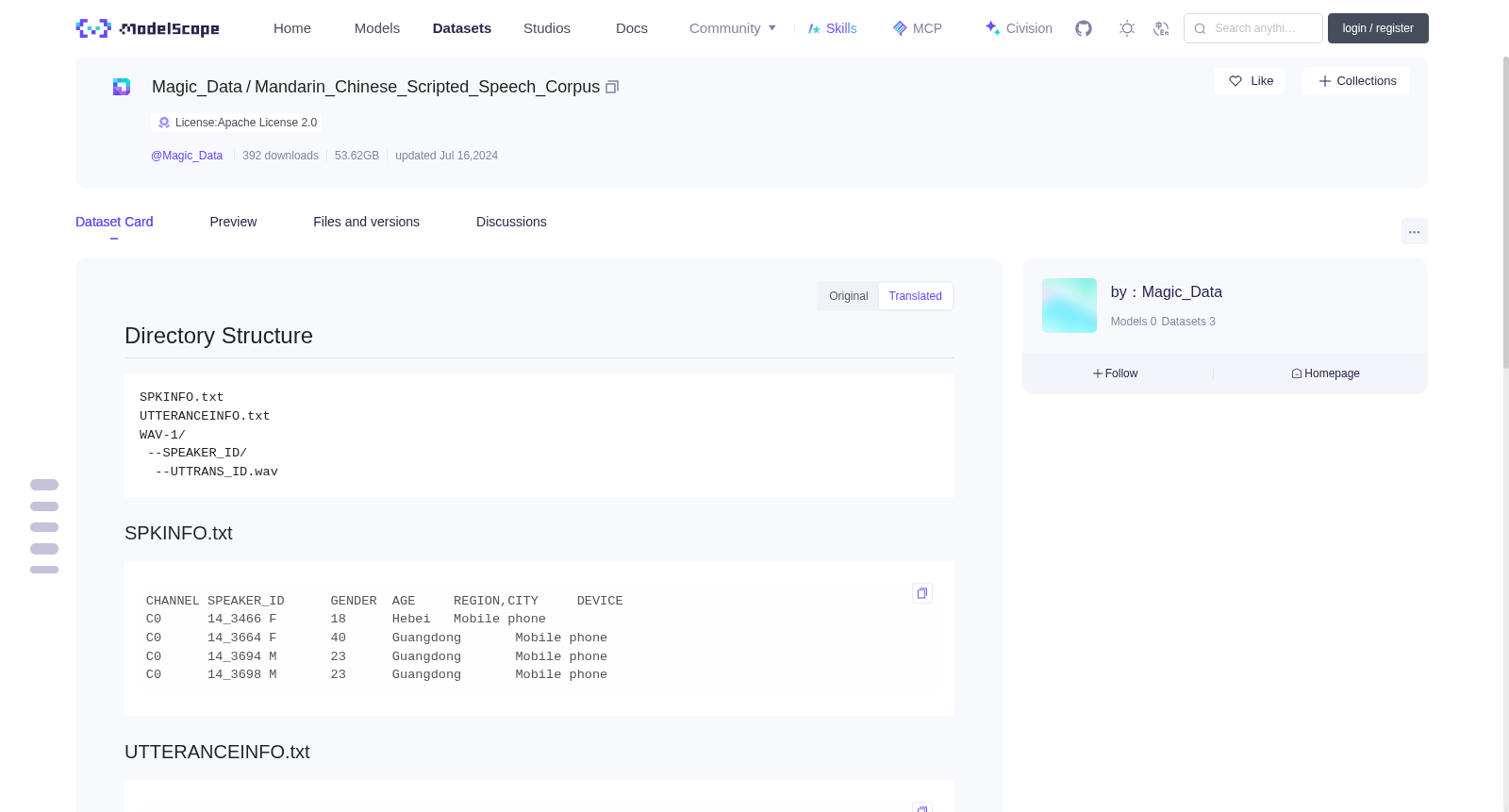
## 目录结构
```
SPKINFO.txt
UTTERANCEINFO.txt
WAV-1/
--SPEAKER_ID/
--UTTRANS_ID.wav
```
### SPKINFO.txt
```txt
CHANNEL SPEAKER_ID GENDER AGE REGION,CITY DEVICE
C0 14_3466 F 18 Hebei Mobile phone
C0 14_3664 F 40 Guangdong Mobile phone
C0 14_3694 M 23 Guangdong Mobile phone
C0 14_3698 M 23 Guangdong Mobile phone
```
### UTTERANCEINFO.txt
```txt
CHANNEL UTTRANS_ID SPEAKER_ID PROMPT TRANSCRIPTION
C0 14_3466_20170826171159.wav 14_3466 请语言播放小说
C0 14_3466_20170826171236.wav 14_3466 这里
C0 14_3466_20170826171323.wav 14_3466 全民唱吧
```
## 使用方法
```python
from modelscope import MsDataset
dataset = MsDataset.load("Magic_Data/Mandarin_Chinese_Scripted_Speech_Corpus", split='train')
# 逐条处理数据
for i, example in enumerate(dataset):
print(example)
if i==10:
break
```
#### 下载方法
:modelscope-code[]{type="sdk"}
:modelscope-code[]{type="git"}
## 目录结构
SPKINFO.txt
UTTERANCEINFO.txt
WAV-1/
--SPEAKER_ID/
--UTTRANS_ID.wav
### 说话人信息文件(SPKINFO.txt)
该文件记录各说话人的基础采集信息,字段依次为:采集通道(CHANNEL)、说话人ID(SPEAKER_ID)、性别(GENDER)、年龄(AGE)、地区与城市(REGION,CITY)、采集设备(DEVICE)。
示例内容如下:
txt
CHANNEL SPEAKER_ID GENDER AGE REGION,CITY DEVICE
C0 14_3466 F 18 河北省 移动手机
C0 14_3664 F 40 广东省 移动手机
C0 14_3694 M 23 广东省 移动手机
C0 14_3698 M 23 广东省 移动手机
### 语音片段信息文件(UTTERANCEINFO.txt)
该文件记录每条语音片段的关联元数据,字段依次为:采集通道(CHANNEL)、语音片段ID(UTTRANS_ID)、说话人ID(SPEAKER_ID)、提示指令(PROMPT)、语音转录文本(TRANSCRIPTION)。
示例内容如下:
txt
CHANNEL UTTRANS_ID SPEAKER_ID PROMPT TRANSCRIPTION
C0 14_3466_20170826171159.wav 14_3466 请语言播放小说
C0 14_3466_20170826171236.wav 14_3466 这里
C0 14_3466_20170826171323.wav 14_3466 全民唱吧
## 使用方法
python
from modelscope import MsDataset
dataset = MsDataset.load("Magic_Data/Mandarin_Chinese_Scripted_Speech_Corpus", split='train')
# 逐样本处理数据
for i, example in enumerate(dataset):
print(example)
if i==10:
break
#### 下载方式
:modelscope-code[]{type="sdk"}
:modelscope-code[]{type="git"}
提供机构:
maas
创建时间:
2024-07-15
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个包含53.62GB中文普通话朗读音频的语料库,按说话人ID和话语ID组织存储,并提供了详细的说话人信息和对应的文本内容。数据集采用Apache 2.0许可协议,适合用于语音相关的研究和开发。
以上内容由遇见数据集搜集并总结生成


