STEM-en-ms
收藏Hugging Face2025-01-03 更新2025-01-04 收录
下载链接:
https://huggingface.co/datasets/Supa-AI/STEM-en-ms
下载链接
链接失效反馈官方服务:
资源简介:
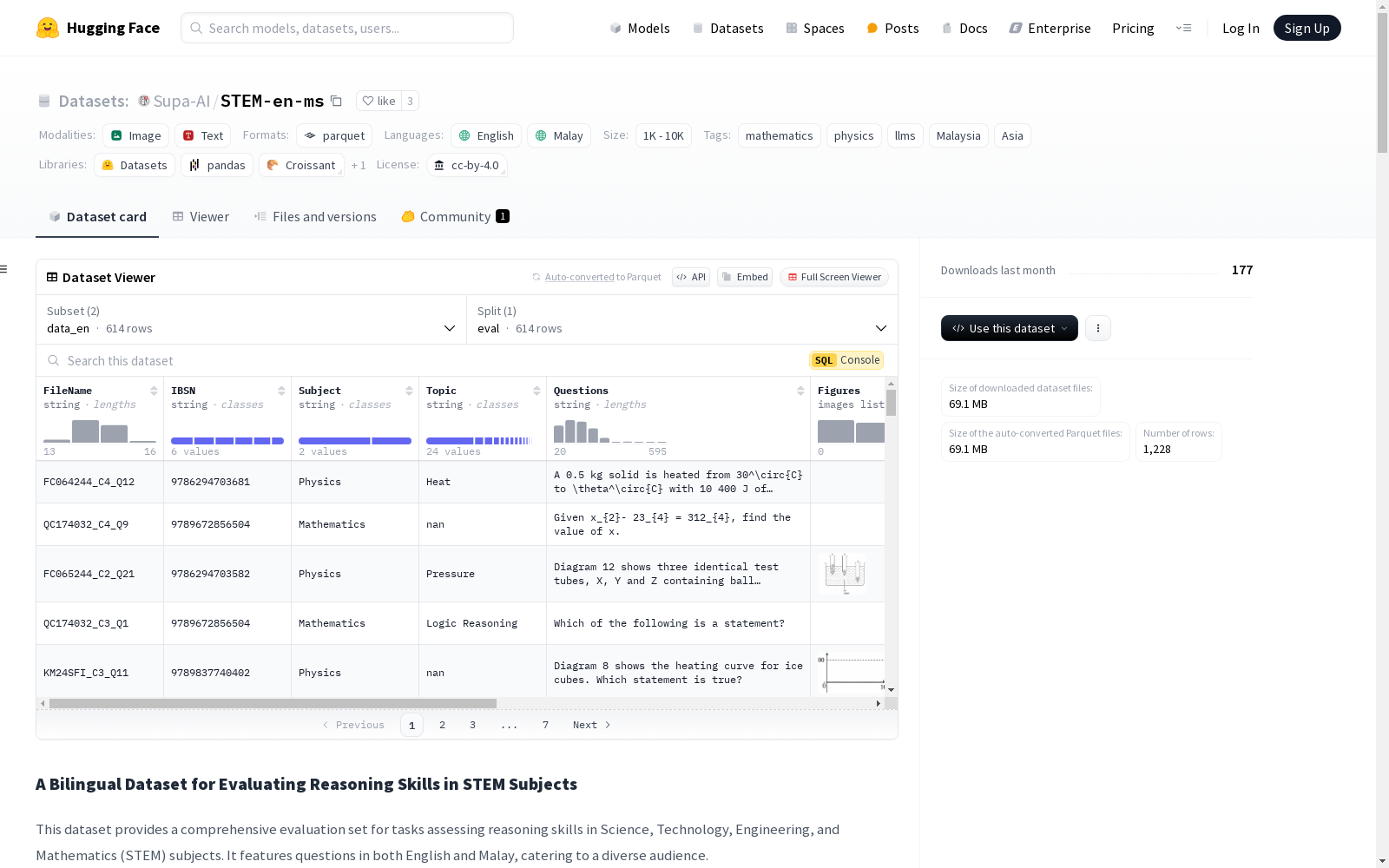
该数据集提供了一个全面的评估集,用于评估科学、技术、工程和数学(STEM)学科中的推理能力。数据集包含英语和马来语两种语言的问题,适合多语言学习者使用。数据集的特点是双语、视觉丰富、注重推理和真实世界情境。数据集分为两个配置:`data_en`(英语)和`data_ms`(马来语),两者具有相同的结构和特征。数据集包含文件名、ISBN、学科、主题、问题、图像、标签、选项和答案等字段。数据集的来源包括SPM历年考试、模拟考试和教育练习册。数据获取方法包括光学字符识别(OCR)和手动质量控制(QC)。数据集当前版本为1.0.0,发布于2024年12月27日,采用CC BY 4.0许可。
This dataset provides a comprehensive evaluation set for assessing reasoning abilities across the fields of Science, Technology, Engineering, and Mathematics (STEM). It contains questions in both English and Malay, making it suitable for multilingual learners. The dataset features bilingual content, visual richness, a focus on reasoning, and real-world scenarios. It is divided into two configurations: `data_en` (English) and `data_ms` (Malay), which share identical structures and characteristics. The dataset includes fields such as filename, ISBN, subject, topic, question, image, tag, options, and answer. The sources of the dataset include past SPM examinations, mock exams, and educational workbooks. Data acquisition methods include Optical Character Recognition (OCR) and manual Quality Control (QC). The current version of the dataset is 1.0.0, released on December 27, 2024, under the CC BY 4.0 license.
创建时间:
2024-12-27
搜集汇总
数据集介绍
构建方式
STEM-en-ms数据集的构建基于多种教育资源,包括马来西亚教育文凭考试(SPM)历年真题、模拟考试以及教育练习册。通过光学字符识别(OCR)技术提取文本,并辅以人工质量控制(QC)确保数据的准确性。数据集分为英语(data_en)和马来语(data_ms)两个配置,涵盖物理和数学两个学科,旨在评估学生在STEM领域的推理能力。
使用方法
用户可通过Hugging Face平台访问STEM-en-ms数据集,使用`datasets`库加载数据。对于英语数据,使用`load_dataset('Supa-AI/STEM-en-ms', name='data_en')`;对于马来语数据,使用`load_dataset('Supa-AI/STEM-en-ms', name='data_ms')`。数据集适用于评估语言模型在STEM领域的推理能力,用户可根据需求进行模型训练和评估,支持5-shot和首词准确率等评估指标。
背景与挑战
背景概述
STEM-en-ms数据集是一个专注于评估科学、技术、工程和数学(STEM)领域推理技能的双语数据集,涵盖英语和马来语两种语言。该数据集由Supa-AI团队于2024年12月27日发布,旨在为多语言学习者提供一个全面的评估工具。数据集的核心研究问题在于如何通过视觉丰富的题目设计,提升学生在STEM学科中的逻辑推理和问题解决能力。其题目来源于马来西亚教育文凭考试(SPM)的历年真题和模拟考试,具有较强的现实意义和教育价值。该数据集的发布为STEM教育领域的研究提供了重要的数据支持,尤其在多语言环境下的教育评估中具有广泛的应用潜力。
当前挑战
STEM-en-ms数据集在构建和应用过程中面临多重挑战。首先,数据集的题目主要集中在物理和数学两个学科,其他STEM学科如化学、生物等尚未覆盖,限制了其应用的广度。其次,数据集中部分题目的答案可能存在准确性不足的问题,这源于数据来源的多样性和OCR技术的局限性。此外,数据集的构建过程中,如何有效整合视觉信息(如图片)与文本信息,以支持复杂的推理任务,也是一个技术难点。最后,数据集的多语言特性虽然提升了其适用性,但也对模型的跨语言理解和推理能力提出了更高的要求,这对现有语言模型的性能提出了挑战。
常用场景
经典使用场景
STEM-en-ms数据集在评估科学、技术、工程和数学(STEM)领域的推理能力方面具有重要应用。该数据集通过提供双语(英语和马来语)的题目,特别适合用于多语言环境下的教育评估。其丰富的视觉内容(如图表)不仅增强了题目的理解性,还为视觉推理提供了支持,使得该数据集在评估学生的逻辑推理和问题解决能力方面尤为有效。
解决学术问题
STEM-en-ms数据集解决了STEM教育中推理能力评估的难题。通过提供基于真实场景的题目,如马来西亚SPM考试题目,该数据集能够有效评估学生在复杂情境下的逻辑推理能力,而非简单的知识记忆。此外,其双语特性为跨语言教育研究提供了宝贵资源,推动了多语言环境下的教育公平性研究。
实际应用
该数据集在实际应用中广泛用于教育评估和语言模型测试。教育机构可以利用该数据集设计双语教学材料,提升学生的跨语言学习能力。同时,该数据集也被用于测试和优化大型语言模型(LLMs)在STEM领域的推理能力,特别是在多语言和视觉推理任务中的表现,为模型的改进提供了重要依据。
数据集最近研究
最新研究方向
近年来,STEM-en-ms数据集在科学、技术、工程和数学(STEM)领域的多语言推理能力评估中引起了广泛关注。该数据集的双语特性(英语和马来语)为多语言学习者提供了独特的资源,尤其是在亚洲地区的教育环境中。研究者们正积极探索如何利用该数据集中的视觉丰富问题和真实世界场景,进一步提升语言模型在复杂推理任务中的表现。特别是在大语言模型(LLMs)的评估中,该数据集被用于测试模型在视觉和文本结合情境下的推理能力,推动了多模态学习的发展。此外,该数据集还促进了跨文化教育资源的开发,为全球STEM教育提供了新的研究视角。
以上内容由遇见数据集搜集并总结生成


