CLoT-Oogiri-GO
收藏魔搭社区2026-05-08 更新2024-05-15 收录
下载链接:
https://modelscope.cn/datasets/shan233/CLoT-Oogiri-GO
下载链接
链接失效反馈官方服务:
资源简介:
<p align="center">
<img src="logo.png" width="550" height="150">
</p>
# Oogiri-GO Dataset Card
[Project Page](https://zhongshsh.github.io/CLoT) | [Paper](https://arxiv.org/abs/2312.02439) | [Code](https://github.com/sail-sg/CLoT) | [Model](https://huggingface.co/zhongshsh/CLoT-cn)
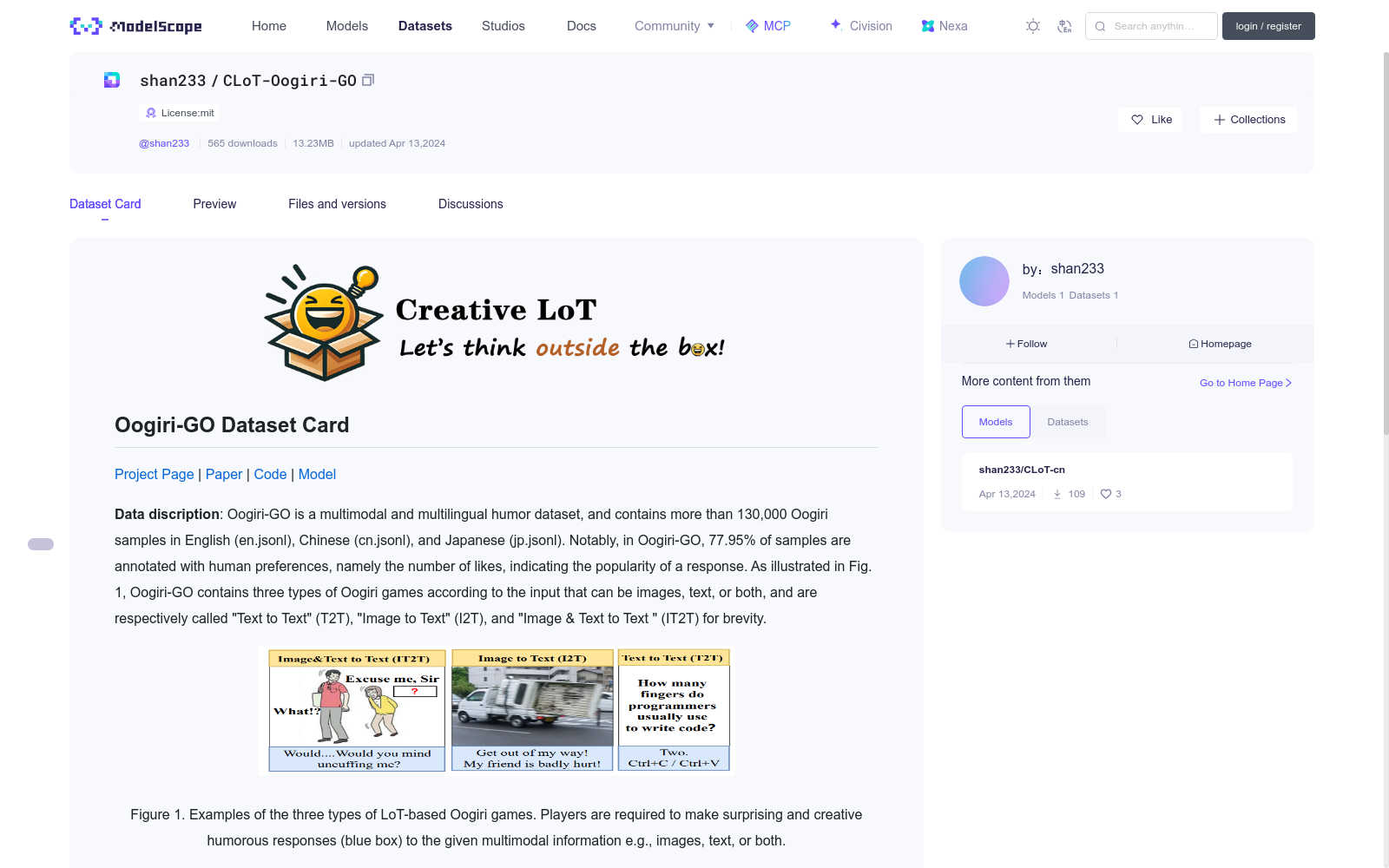
**Data discription**: Oogiri-GO is a multimodal and multilingual humor dataset, and contains more than 130,000 Oogiri samples in English (en.jsonl), Chinese (cn.jsonl), and Japanese (jp.jsonl). Notably, in Oogiri-GO, 77.95\% of samples are annotated with human preferences, namely the number of likes, indicating the popularity of a response. As illustrated in Fig. 1, Oogiri-GO contains three types of Oogiri games according to the input that can be images, text, or both, and are respectively called "Text to Text" (T2T), "Image to Text" (I2T), and "Image & Text to Text " (IT2T) for brevity.
<p align="center">
<img src="oogiri.png" width="550" height="150"> <br>
Figure 1. Examples of the three types of LoT-based Oogiri games. Players are required to make surprising and creative humorous responses (blue box) to the given multimodal information e.g., images, text, or both.
</p>
Each line in the `jsonl` files represents a sample, formatted as follows:
```
{"type": "I2T", "question": null, "image": "5651380", "text": "It wasn't on purpose, I'm sorry!", "star": 5}
```
where `type` indicates the type of Oogiri game for the sample (T2T, I2T, IT2T); `question` represents the text question for the sample, with `None` for types other than T2T; `image` indicates the image question for the sample, with None for T2T samples; `text` is the text response for the sample; and `star` denotes the human preference.
In Japanese data (`jp.jsonl`) specifically, the questions for `T2T` type may appear as 'None' because the question text is in image form.
**Data distribution**: Table summarizes the distribution of these game types. For training purposes, 95% of the samples are randomly selected to construct the training dataset, while the remaining 5% form the test dataset for validation and analysis.
| Category | English | Chinese | Japanese |
|:--------:|:-------:|:-------:|:---------:|
| I2T | 17336 | 32130 | 40278 |
| T2T | 6433 | 15797 | 11842 |
| IT2T | -- | 912 | 9420 |
**Project page for more information**: https://zhongshsh.github.io/CLoT
**License**: Creative Commons Attribution 4.0 International. We also adhere to the terms of use from any of the data sources, such as [Bokete](https://bokete.jp/about/rule) and [Zhihu](https://www.zhihu.com/term/zhihu-terms). If you have any concerns regarding this dataset, especially if you believe it infringes upon your legal rights, please feel free to contact us. We will promptly review any issues raised and respond accordingly.
**Citation**
```
@misc{zhong2023clot,
title={Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation},
author={Zhong, Shanshan and Huang, Zhongzhan and Gao, Shanghua and Wen, Weushao and Lin, Liang and Zitnik, Marinka and Zhou, Pan},
journal={arXiv preprint arXiv:2312.02439},
year={2023}
}
```
<p align="center">
<img src="logo.png" width="550" height="150">
</p>
# Oogiri-GO 数据集卡片
[项目页面](https://zhongshsh.github.io/CLoT) | [论文](https://arxiv.org/abs/2312.02439) | [代码](https://github.com/sail-sg/CLoT) | [模型](https://huggingface.co/zhongshsh/CLoT-cn)
**数据描述**:Oogiri-GO是一款多模态多语言幽默数据集,涵盖英语(en.jsonl)、汉语(cn.jsonl)及日语(jp.jsonl)三类语言下的超13万条Oogiri样本。值得注意的是,Oogiri-GO中有77.95%的样本标注了人类偏好评分,即点赞数,用于体现回复的受欢迎程度。如图1所示,Oogiri-GO根据输入模态分为三类Oogiri游戏,输入可仅为图像、仅为文本,或二者兼具,为简洁起见分别命名为“文本到文本(Text to Text, T2T)”、“图像到文本(Image to Text, I2T)”以及“图像与文本到文本(Image & Text to Text, IT2T)”。
<p align="center">
<img src="oogiri.png" width="550" height="150"> <br>
图1. 三类基于跳跃思维(Leap-of-Thought, LoT)的Oogiri游戏示例。玩家需针对给定的多模态信息(如图像、文本或二者兼具),生成令人惊喜且富有创意的幽默回复(蓝色框标注部分)。
</p>
每个jsonl文件中的每一行代表一个样本,格式如下:
{"type": "I2T", "question": null, "image": "5651380", "text": "It wasn't on purpose, I'm sorry!", "star": 5}
其中`type`表示该样本所属的Oogiri游戏类型(T2T、I2T、IT2T);`question`为样本对应的文本问题,非T2T类型的样本该字段值为`None`;`image`表示样本对应的图像问题,T2T类型的样本该字段值为`None`;`text`为该样本的文本回复;`star`则代表人类偏好评分。
针对日语数据集(jp.jsonl),部分T2T类型的样本的`question`字段可能为`None`,这是因为该类样本的问题文本以图像形式呈现。
**数据分布**:下表汇总了各类游戏的样本分布情况。为开展模型训练,我们随机选取95%的样本构建训练集,剩余5%的样本作为测试集用于模型验证与分析。
| 类别 | 英语 | 汉语 | 日语 |
|:--------:|:-------:|:-------:|:---------:|
| I2T | 17336 | 32130 | 40278 |
| T2T | 6433 | 15797 | 11842 |
| IT2T | -- | 912 | 9420 |
**更多信息请访问项目页面**:https://zhongshsh.github.io/CLoT
**许可证**:采用知识共享署名4.0国际许可协议(Creative Commons Attribution 4.0 International)。同时我们严格遵循各原始数据源的使用条款,例如[Bokete](https://bokete.jp/about/rule)与[知乎(Zhihu)](https://www.zhihu.com/term/zhihu-terms)。若您对本数据集存在任何疑问,尤其是认为其侵犯了您的合法权益,请随时与我们联系。我们将及时审核并回复相关诉求。
**引用**
bibtex
@misc{zhong2023clot,
title={Let's Think Outside the Box: Exploring 跳跃思维(Leap-of-Thought) in 大语言模型(Large Language Model) with Creative Humor Generation},
author={Zhong, Shanshan and Huang, Zhongzhan and Gao, Shanghua and Wen, Weushao and Lin, Liang and Zitnik, Marinka and Zhou, Pan},
journal={arXiv preprint arXiv:2312.02439},
year={2023}
}
提供机构:
maas
创建时间:
2024-04-13
搜集汇总
数据集介绍
背景与挑战
背景概述
Oogiri-GO是一个多模态、多语言的幽默数据集,包含超过130,000个样本,涵盖英语、中文和日语,并标注了人类偏好。数据集包含三种类型的Oogiri游戏(T2T、I2T、IT2T),主要用于训练和测试幽默生成模型。
以上内容由遇见数据集搜集并总结生成


