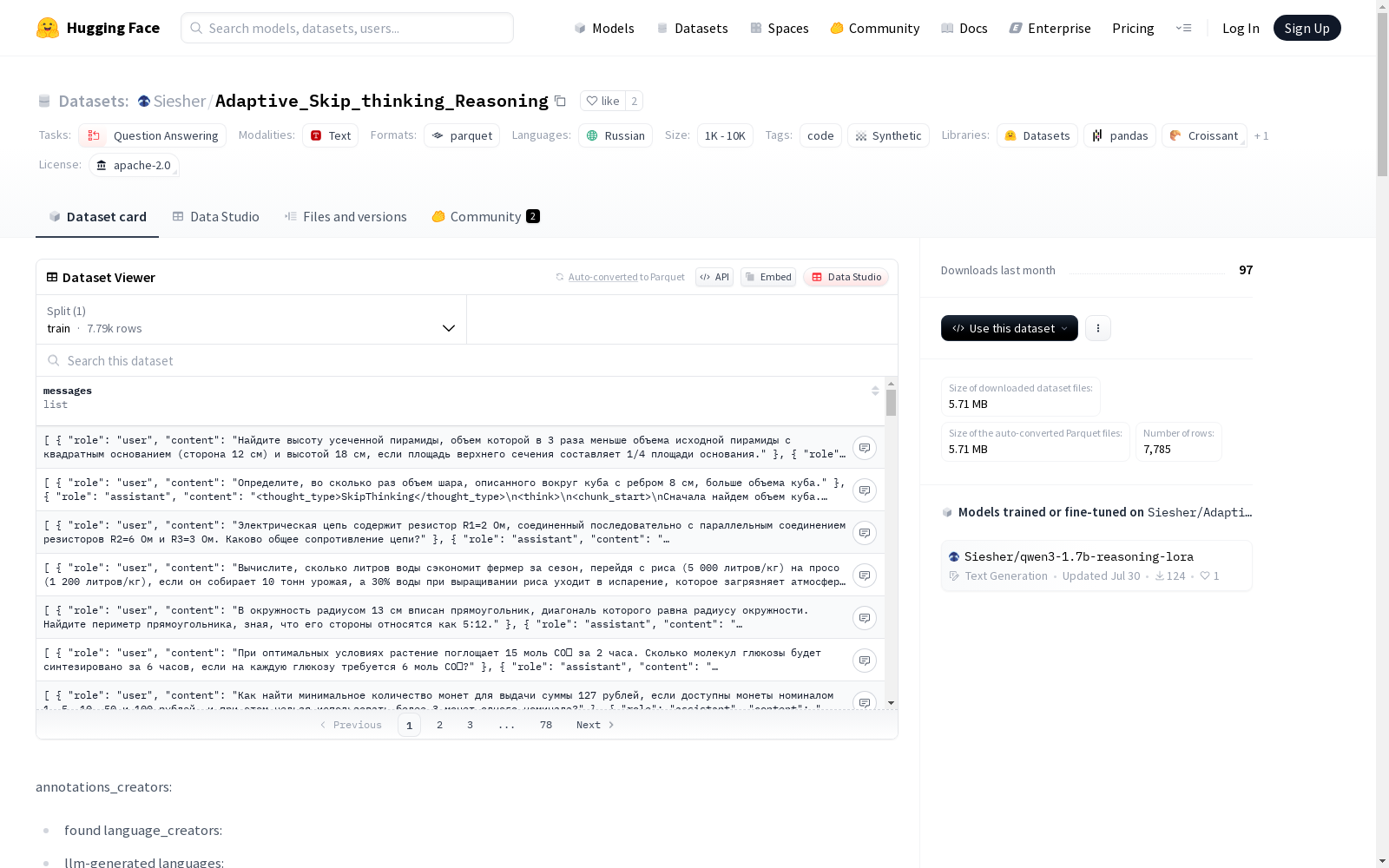
Adaptive_Skip_thinking_Reasoning
收藏数据集概述:Cerebras Adaptive Reasoning (Russian)
基本信息
- 许可证: Apache-2.0
- 任务类别: 文本生成、推理(包括链式思维、程序化思维、跳跃思维)
- 语言: 俄语 (ru)
- 标签: 代码、合成数据
- 数据集名称: Ada_Think
- 规模: 1K < n < 10K 样本
数据集描述
cerebras-adaptive-reasoning-ru 是一个合成数据集,旨在通过从大型语言模型(LLM)到小型语言模型(SLM)的知识蒸馏,训练自适应思维和高效选择推理策略的能力。数据集由 Cerebras 模型(如 qwen-3-235b-a22b)生成,展示了多种解决多步任务的策略。
主要特点
-
多样化推理策略:
- Chain-of-Thought (CoT): 详细的逐步推理。
- Program-of-Thought (PoT): 包含 Python 代码块的推理。
- Skip-Thinking: 将推理分解为原子块,带有
<continue_thinking>或<end_of_thought>标记。
-
覆盖领域: 逻辑思维、数学计算、空间分析等俄语任务。
数据集目标
- 知识蒸馏: 将教师模型的推理能力传递给更小的模型。
- 可控推理训练: 学习何时及如何应用不同推理策略。
- 可解释性提升: 通过
<think>标签跟踪和分析决策过程。
数据结构
- 格式: JSON Lines (.jsonl)
- 每条记录结构: json { "messages": [ { "role": "user", "content": "问题文本" }, { "role": "assistant", "content": "<thought_type>{类型}</thought_type> <think> {推理文本} </think> {最终答案}" } ] }
字段说明
messages: 对话消息列表。role: "user" 或 "assistant"。content: 消息内容(问题或包含推理的答案)。
示例
Chain-of-Thought (CoT)
json { "messages": [ { "role": "user", "content": "如果花园里有10棵苹果树,每棵产20公斤苹果,总共能收获多少苹果?" }, { "role": "assistant", "content": "<thought_type>CoT</thought_type> <think> 推理步骤... </think> 200公斤" } ] }
Program-of-Thought (PoT)
json { "messages": [ { "role": "user", "content": "5乘以8再加3等于多少?" }, { "role": "assistant", "content": "<thought_type>PoT</thought_type> <think> Python代码块... </think> 43" } ] }
Skip-Thinking
json { "messages": [ { "role": "user", "content": "法国的首都是哪里?" }, { "role": "assistant", "content": "<thought_type>SkipThinking</thought_type> <think> <chunk_start>...<end_of_thought> </think> 巴黎" } ] }
数据生成
- 生成工具: Python 脚本(使用 Cerebras API)。
- 教师模型: qwen-3-235b-a22b。
- 生成设置:
- 独特问题数量: 400。
- 每个问题的策略数量: 6。
- 推理长度: CoT/PoT 100-200词,SkipThinking 30-50词。
- 问题主题: 逻辑谜题、数学、空间思维等。
使用示例
python from datasets import load_dataset dataset = load_dataset("your_org/cerebras-adaptive-reasoning-ru")
引用
bibtex @misc{cerebras_adaptive_reasoning_ru_2025, author = {{Cerebras Systems} and {Siesher}}, title = {{Cerebras Adaptive Reasoning (Russian) Dataset}}, year = {2025}, publisher = {{Hugging Face}}, url = {https://huggingface.co/datasets/Siesher/cerebras-adaptive-reasoning-ru} }
相关资源
- 数据生成脚本: https://github.com/Siesher/Generator_for_reasoning