ko-arena-hard-auto-v0.1
收藏Hugging Face2024-12-11 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/qwopqwop/ko-arena-hard-auto-v0.1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是基于[arena-hard-auto-v0.1](https://huggingface.co/datasets/lmarena-ai/arena-hard-auto-v0.1)的韩语翻译版本,使用`GPT-4o`和`o1`进行翻译并经过人工校对。数据集包含了一些翻译后的提示模板和示例,展示了如何评估两个AI助手提供的回答质量。此外,数据集还与另一个名为[m-ArenaHard](https://huggingface.co/datasets/CohereForAI/m-ArenaHard)的数据集进行了对比,突出了该数据集在翻译质量和格式保持方面的优势。
This dataset is a Korean translation based on [arena-hard-auto-v0.1](https://huggingface.co/datasets/lmarena-ai/arena-hard-auto-v0.1), translated using `GPT-4o` and `o1` and manually proofread. The dataset includes translated prompt templates and examples, demonstrating how to evaluate the response quality of two AI assistants. Additionally, this dataset is compared with another dataset named [m-ArenaHard](https://huggingface.co/datasets/CohereForAI/m-ArenaHard), highlighting its advantages in terms of translation quality and format retention.
创建时间:
2024-12-10
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别: 文本生成
- 语言: 韩语
- 数据集规模: n<1K
数据集描述
该数据集是对 arena-hard-auto-v0.1 的韩语翻译版本,使用 GPT-4o 和 o1 进行翻译,并经过人工校对。可能存在误译、意译或不自然的翻译。如果发现此类问题,欢迎提出 issue 或提交修改后的 PR。
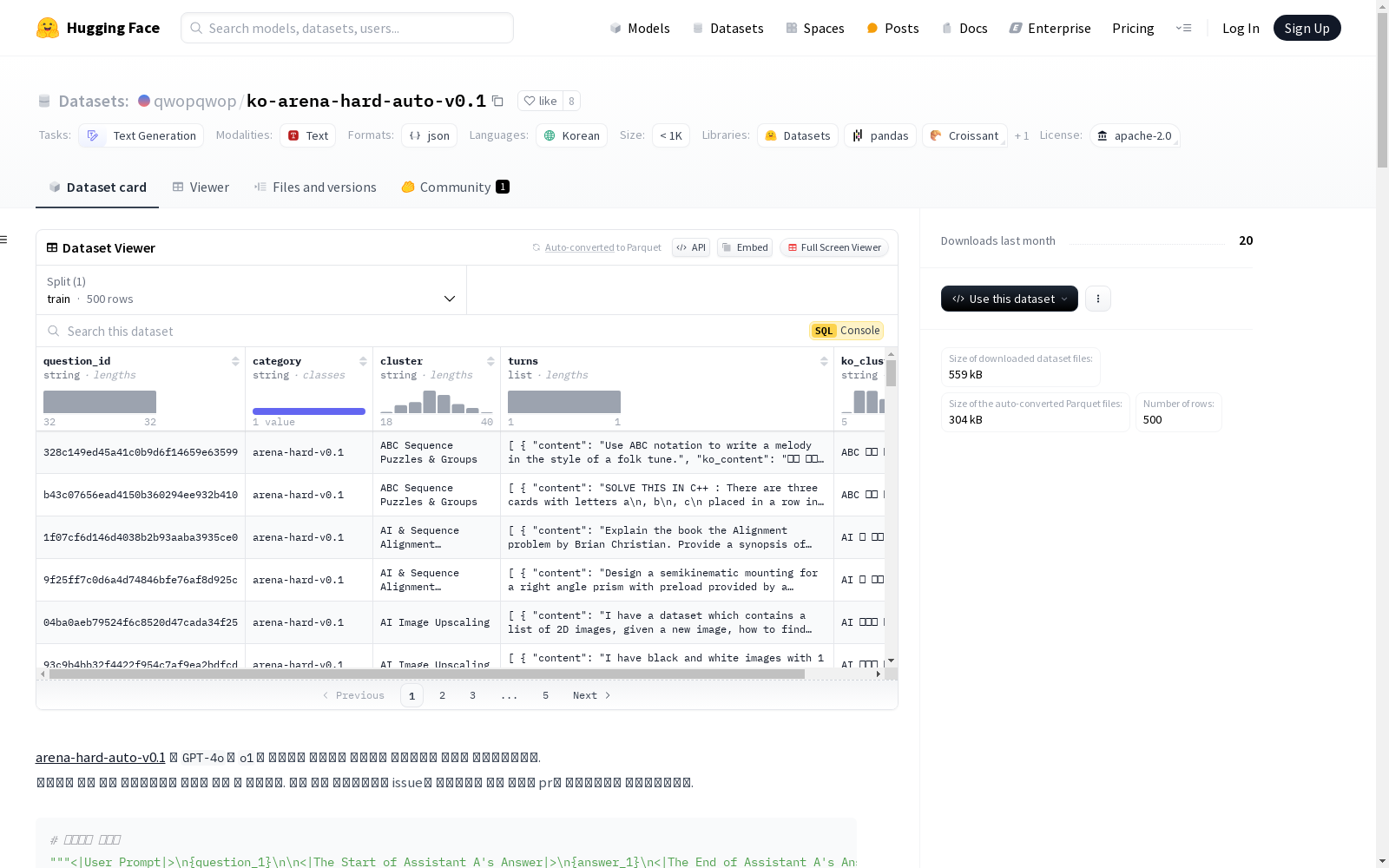
数据集示例
以下是数据集中的一些示例,展示了原始文本、m-ArenaHard 翻译版本和 ko-arena-hard-auto-v0.1 翻译版本的对比:
示例 13
- 原文: Proof that Q(sqrt(-11)) is a principal ideal domain
- m-ArenaHard: Q(sqrt(-11))이 주 아이디얼 도메인임을 증명
- ko-arena-hard-auto-v0.1: Q(sqrt(-11))가 주 아이디얼 정역임을 증명하시오.
示例 18
- 原文: How can I generate a seaborn barplot that includes the values of the bar heights and confidence intervals?
- m-ArenaHard: 막대 높이와 신뢰 구간 값을 포함하는 시본 막대 그래프를 어떻게 생성할 수 있나요?
- ko-arena-hard-auto-v0.1: 막대 높이와 신뢰 구간의 값을 포함하는 seaborn 막대 그래프를 생성하려면 어떻게 해야되?
示例 25
- 原文: If I have a TypeScript class: class Foo { ReactProperties: { a: string; } } How do I extract the type of the ReactProperties member object from the type Class?
- m-ArenaHard: TypeScript 클래스가 있는 경우: class Foo { ReactProperties: { a: string; } } Class 유형에서 ReactProperties 멤버 객체의 유형을 추출하려면 어떻게 해야 하나요?
- ko-arena-hard-auto-v0.1: TypeScript 클래스가 있는 경우: class Foo { ReactProperties: { a: string; } } Class 타입에서 ReactProperties 멤버 객체의 타입을 어떻게 추출하니?
示例 27
- 原文: Introduce Ethan, including his experience-level with software development methodologies like waterfall and agile development. Describe the major differences between traditional waterfall and agile software developments. In his opinion, what are the most notable advantages and disadvantages of each methodology?
- m-ArenaHard: Ethan을 소개하고, 폭포수 및 애자일 개발과 같은 소프트웨어 개발 방법론에 대한 그의 경험 수준을 포함합니다. 전통적인 폭포수 및 애자일 소프트웨어 개발의 주요 차이점을 설명합니다. 그의 의견으로는 각 방법론의 가장 주목할 만한 장단점은 무엇입니까?
- ko-arena-hard-auto-v0.1: waterfall 및 agile 개발과 같은 소프트웨어 개발 방법론에 대한 경험 수준을 포함하여 Ethan을 소개하세요. 전통적인 waterfall과 agile 소프트웨어 개발의 주요 차이점을 설명하세요. 그의 의견으로는 각 방법론의 가장 눈에 띄는 장점과 단점은 무엇입니까?
示例 32
- 原文: Provide 15 attack vectors in Manufacturing sector and methods to mitigate the identified risks
- m-ArenaHard: 제조 부문의 15가지 공격 벡터와 식별된 위험을 완화하는 방법을 제공합니다.
- ko-arena-hard-auto-v0.1: 제조업 섹터의 공격 벡터 15개와 확인된 위험을 완화하기 위한 방법을 제공하십시오
示例 40
- 原文: You are a data scientist, output a Python script in OOP for a contextual multi armed bandit sampling from 3 models
- m-ArenaHard: 당신은 데이터 과학자이고 3개 모델에서 상황에 맞는 다중 무장 도적 샘플링을 위한 OOP로 Python 스크립트를 출력합니다.
- ko-arena-hard-auto-v0.1: 당신은 데이터 과학자이며, 3개의 모델에서 샘플링하는 contextual multi armed bandit을 위한 파이썬 스크립트를 OOP 방식으로 출력해주세요.
示例 46
- 原文: Give me a recipe for making 5L of strawberry and blackberry melomel. Use metric measurements.
- m-ArenaHard: 딸기와 블랙베리 멜로멜 5L를 만드는 레시피를 알려주세요. 미터법 측정을 사용하세요.
- ko-arena-hard-auto-v0.1: 5L의 딸기와 블랙베리 멜로멜을 만드는 레시피를 줘. 미터법을 사용해.
示例 150
- 原文: Can you give me a swimming workout with a main set of 15x100 at 1:30 and in total around 4500m ? For an swimmer at an advanced level
- m-ArenaHard: 1:30에 15x100의 메인 세트와 총 4500m 정도의 수영 운동을 해줄 수 있나요? 고급 레벨의 수영 선수를 위한
- ko-arena-hard-auto-v0.1: 수영 상급자를 위해 1분 30초 간격으로 100m를 15회 하는 메인 세트를 포함하는 총 약 4500m의 수영 프로그램을 제공해 주실 수 있나요?
示例 364
- 原文: write python code to web scrape https://naivas.online using beautiful soup
- m-ArenaHard: https://naivas.online에서 아름다운 수프를 사용하여 웹 스크래핑에 파이썬 코드를 작성하세요
- ko-arena-hard-auto-v0.1: beautiful soup을 사용해 https://naivas.online 웹을 스크래핑하는 파이썬 코드를 작성해
示例 461
- 原文: help me remove column A based on this code data vertical3; set vertical2; format Treatment $Drug. Effectiveness $Effective. Sex $Sex. ;
- m-ArenaHard: 이 코드 데이터 vertical3을 기반으로 열 A를 제거하도록 도와주세요; vertical2를 설정하세요; 치료 $약물. 효과 $효과. 성별 $성별. 형식을 지정하세요.
- ko-arena-hard-auto-v0.1: 이 코드를 기반으로 열 A를 제거하도록 도와주세요 data vertical3; set vertical2; format Treatment $Drug. Effectiveness $Effective. Sex $Sex. ;
搜集汇总
数据集介绍
构建方式
ko-arena-hard-auto-v0.1 数据集是通过使用 `GPT-4o` 和 `o1` 将原始数据集翻译成韩语,并进行人工校对和修正构建而成的。与使用 `Google Translate API v3` 自动翻译的 m-ArenaHard 数据集不同,ko-arena-hard-auto-v0.1 数据集通过人工干预确保了翻译的准确性和自然性,减少了机器翻译中常见的误译和格式问题。
特点
该数据集的主要特点在于其翻译的精确性和人工校对的细致性。通过使用先进的翻译模型 `GPT-4o` 和 `o1`,结合人工校对,确保了翻译结果的流畅性和准确性。此外,数据集中的每个翻译样本都经过严格的质量控制,以避免常见的机器翻译错误,如过度翻译或格式不一致。
使用方法
ko-arena-hard-auto-v0.1 数据集主要用于韩语环境下的文本生成任务。用户可以通过加载该数据集,利用其中的韩语翻译样本进行模型训练或评估。数据集中的翻译样本格式统一,适合用于构建和测试韩语文本生成模型。用户还可以根据需要对数据集进行进一步的处理或扩展,以适应特定的应用场景。
背景与挑战
背景概述
ko-arena-hard-auto-v0.1 数据集是由研究人员使用 `GPT-4o` 和 `o1` 工具将原始数据集翻译成韩语,并通过人工校对进行质量控制的数据集。该数据集的主要研究目标是提升韩语文本生成的质量,特别是在处理复杂或专业领域的文本时,确保翻译的准确性和自然性。通过与 `Google Translate API v3` 翻译的 m-ArenaHard 数据集进行对比,ko-arena-hard-auto-v0.1 数据集在翻译的准确性和格式保持方面表现更为出色。该数据集的创建旨在为韩语文本生成任务提供高质量的训练数据,尤其是在多语言模型性能评估中具有重要意义。
当前挑战
ko-arena-hard-auto-v0.1 数据集在构建过程中面临的主要挑战包括:1) 确保翻译的准确性和自然性,避免机器翻译常见的误译或不自然的表达;2) 在保持原文格式和语义结构的同时,进行有效的韩语翻译;3) 通过人工校对减少机器翻译的错误,这需要大量的人力和时间投入。此外,该数据集的应用挑战在于如何在高复杂度的文本生成任务中,确保模型能够充分利用这些高质量的韩语数据,提升其在多语言环境下的表现。
常用场景
经典使用场景
ko-arena-hard-auto-v0.1 数据集主要用于评估和改进AI助手在处理复杂问题时的响应质量。通过提供用户问题和两个AI助手的回答,该数据集允许研究人员和开发者比较不同AI模型在生成答案时的准确性、相关性和创造性。这种比较有助于优化AI系统的性能,特别是在多轮对话和复杂任务处理中。
解决学术问题
该数据集解决了在多语言环境下AI模型响应质量评估的学术问题。通过提供高质量的韩语翻译和手动校对,ko-arena-hard-auto-v0.1 数据集确保了翻译的准确性和自然性,从而为研究人员提供了一个可靠的工具来评估和改进AI模型在不同语言环境下的表现。这对于跨语言AI系统的开发和优化具有重要意义。
衍生相关工作
ko-arena-hard-auto-v0.1 数据集的衍生工作主要集中在多语言AI系统的开发和评估上。例如,研究人员可以利用该数据集开发新的翻译模型,以提高多语言环境下的翻译质量。此外,该数据集还可用于训练和测试新的AI助手模型,特别是在需要处理复杂问题和多轮对话的场景中。这些衍生工作进一步推动了多语言AI技术的发展和应用。
以上内容由遇见数据集搜集并总结生成


