dogwhistle_dataset
收藏Hugging Face2025-04-16 更新2025-04-17 收录
下载链接:
https://huggingface.co/datasets/AstroAure/dogwhistle_dataset
下载链接
链接失效反馈官方服务:
资源简介:
这是一个合并了SALT-NLP关于狗哨声的几个数据集的数据集,包括已识别的狗哨声和Reddit上潜在的狗哨声以及美国国会中的潜在狗哨声。数据集增加了标签特征,用于区分SALT-NLP团队识别的狗哨声和未识别为狗哨声的内容。标签分为三种:0代表非狗哨声,1代表已识别的狗哨声。数据集是为了EPFL的深度学习课程EE-559而创建的。
This is a dataset that merges multiple datasets about dog whistles from SALT-NLP, including identified dog whistles, potential dog whistles on Reddit and potential dog whistles in the U.S. Congress. This dataset adds a label feature to distinguish between dog whistles identified by the SALT-NLP team and content not classified as dog whistles. The labels are divided into three categories: 0 represents non-dog whistles, and 1 represents identified dog whistles. This dataset was created for the Deep Learning Course EE-559 at EPFL.
创建时间:
2025-04-08
搜集汇总
数据集介绍
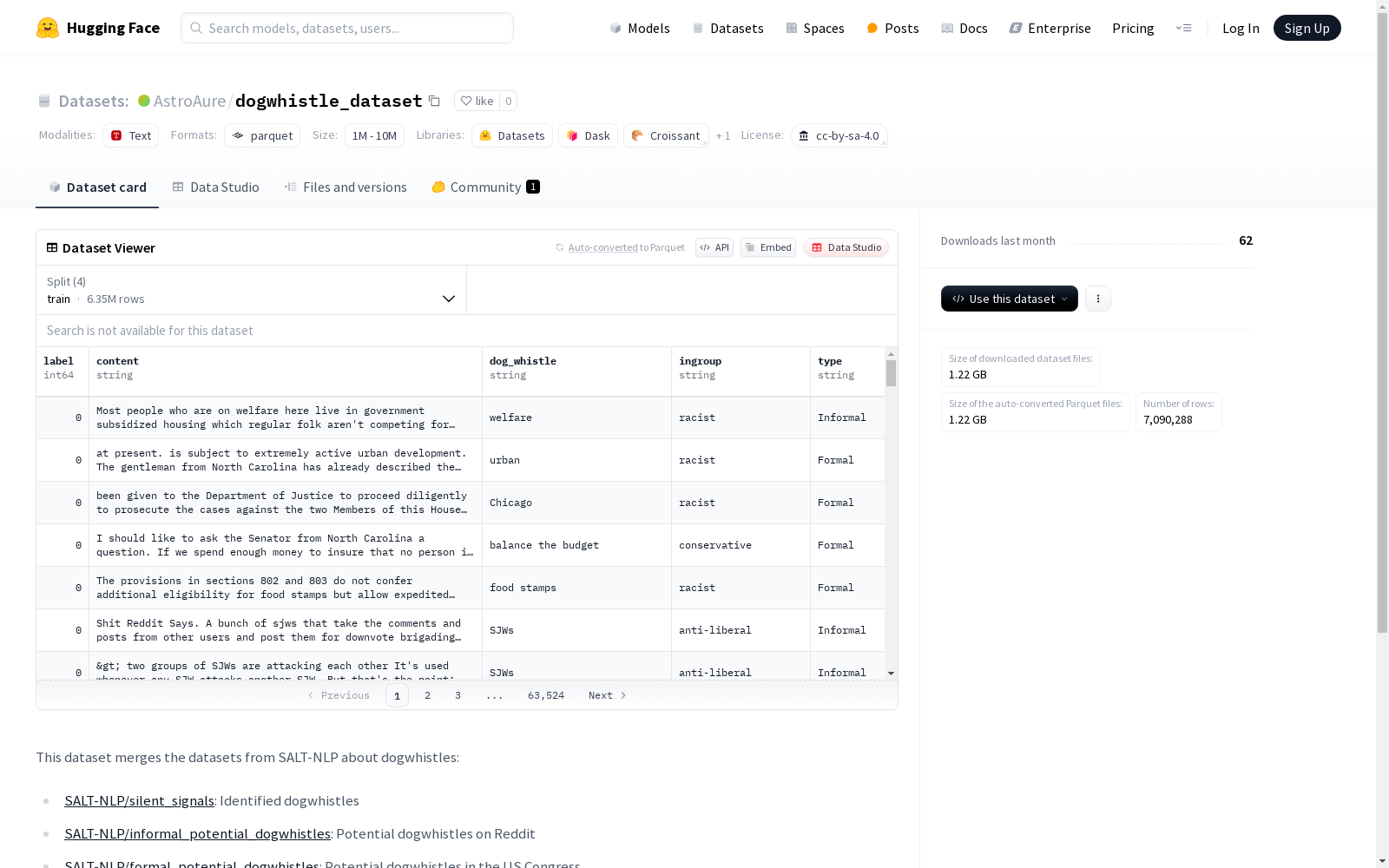
构建方式
在自然语言处理领域,识别隐晦表达具有重要意义。dogwhistle_dataset通过整合SALT-NLP团队三个核心数据集构建而成,包括已确认的隐晦表达数据集silent_signals,以及来自Reddit平台和美国国会的潜在隐晦表达数据集。该数据集创新性地引入了标签特征,采用三级分类体系区分非隐晦表达、已确认隐晦表达等不同类别,为深度分析隐晦语言提供了结构化基础。数据集构建过程注重来源多样性,涵盖社交媒体和正式政治场合两种典型语境。
特点
该数据集最显著的特点是实现了隐晦表达识别的多场景覆盖,包含超过700万条标注样本。数据结构设计科学,每条记录包含内容文本、隐晦表达标记、群体归属和类型等丰富特征。特别值得注意的是,数据集提供了原始不平衡分布和平衡处理两个版本,既能反映真实场景的数据分布,又适合模型训练需求。标注体系严谨,区分了已确认和潜在隐晦表达,为研究提供了可靠的基础。
使用方法
使用该数据集时,研究人员可基于标签特征构建二分类或三分类模型,识别文本中的隐晦表达。平衡版本适合直接用于模型训练,而不平衡版本更适用于评估模型在真实场景的表现。数据中的ingroup和type字段可用于细粒度分析特定群体或场景中的隐晦表达模式。建议先进行探索性数据分析,了解不同类别样本的分布特征,再根据具体研究目标选择合适的子集进行建模。
背景与挑战
背景概述
dogwhistle_dataset数据集由EPFL的EE-559深度学习课程团队整合SALT-NLP研究机构的多项子数据集构建而成,聚焦于政治和社会语境中具有隐含意义的特殊语言现象——狗哨政治(dogwhistle)的识别与分析。该数据集融合了SALT-NLP/silent_signals标注的明确狗哨语料,以及来自Reddit平台和美国国会文本的潜在狗哨内容,通过二分类标签体系区分已验证与非狗哨文本。其构建标志着计算社会科学与自然语言处理交叉领域对隐蔽性政治话语的量化研究迈入新阶段,为分析意识形态编码语言的社会传播机制提供了重要数据基础。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,狗哨语言的隐喻性和语境依赖性导致语义边界模糊,传统文本分类模型难以捕捉其与常规政治话语的微妙差异;在构建过程中,非结构化社交媒体文本与美国国会正式文书的语域差异,以及潜在狗哨样本的标注可靠性问题,对数据清洗与标注一致性提出极高要求。平衡数据集时,低频狗哨实例与海量负样本的悬殊比例进一步加剧了机器学习模型的过拟合风险。
常用场景
经典使用场景
在自然语言处理和社会计算领域,dogwhistle_dataset数据集为研究者提供了分析政治和社会话语中隐含信息的宝贵资源。该数据集整合了来自Reddit和美国国会的潜在和已确认的狗哨政治言论,使得研究者能够在统一框架下探索这些微妙且具有争议的语言现象。通过标注明确的标签,该数据集特别适合用于训练和评估识别狗哨言论的分类模型。
衍生相关工作
基于该数据集,研究者已开展多项重要工作。其中包括开发基于深度学习的狗哨言论检测模型,以及分析不同政治背景下狗哨言论的演变规律。这些工作不仅推动了自然语言处理技术在社会科学中的应用,也为理解政治传播中的微妙机制提供了新的方法论视角。
数据集最近研究
最新研究方向
随着社交媒体和政治传播的复杂性日益增加,识别和分析隐晦语言(dogwhistle)成为自然语言处理和社会计算领域的热点问题。dogwhistle_dataset作为整合多个来源的综合性数据集,为研究者提供了丰富的标注数据,支持从文本分类到社会群体行为分析的多种研究方向。当前,该数据集被广泛应用于探索政治话语中的隐含偏见、社交媒体中的群体动态以及自动化内容审核系统的开发。特别是在美国国会和Reddit平台的数据支持下,研究者能够深入分析正式与非正式语境下隐晦语言的传播机制及其社会影响。这一领域的研究不仅有助于理解信息传播的微妙模式,也为构建更加公平和透明的在线交流环境提供了数据基础。
以上内容由遇见数据集搜集并总结生成


