Smallbooru
收藏数据集概述
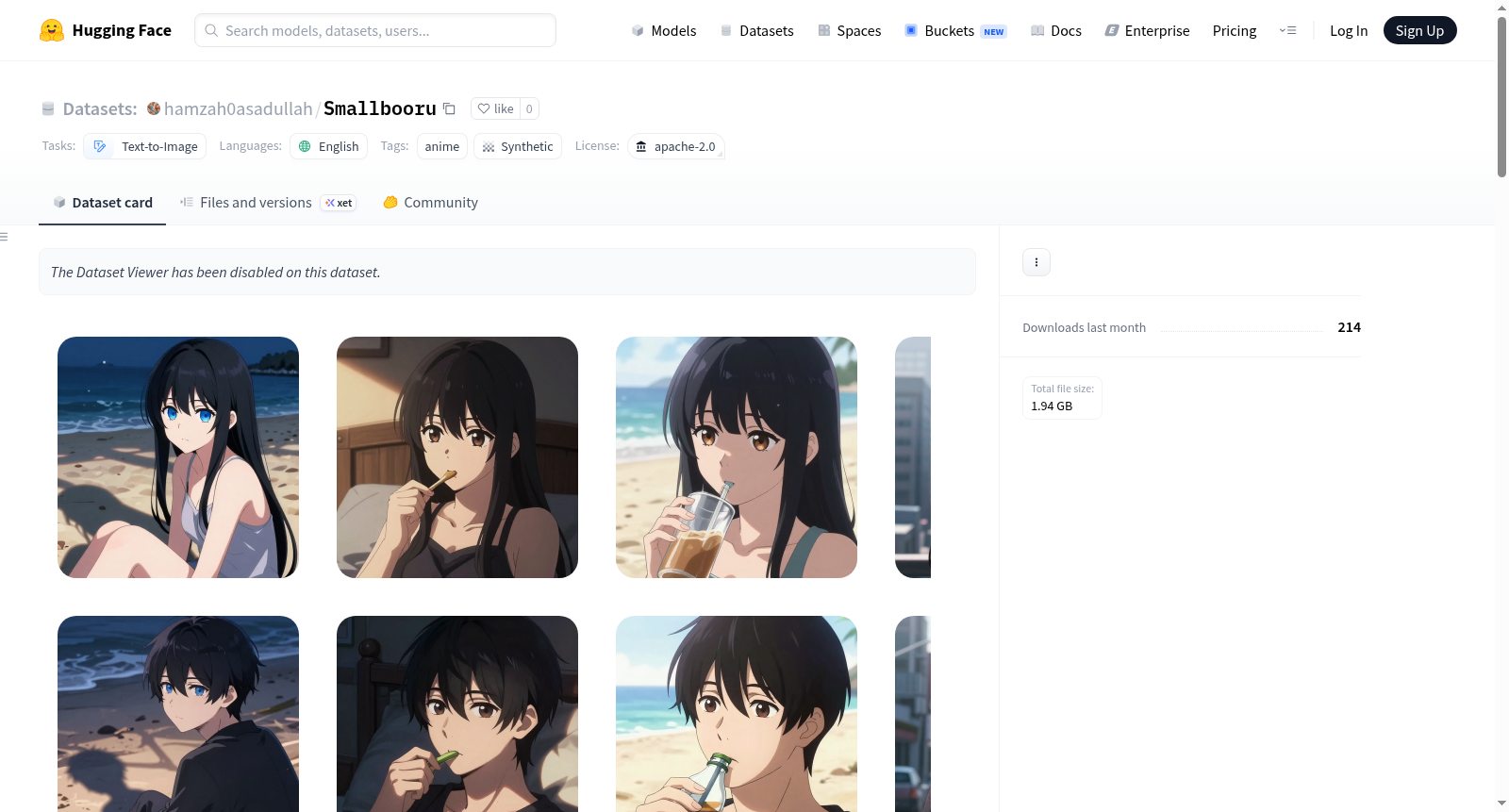
Smallbooru 是一个由文本到图像(text-to-image)数据对组成的数据集,所有图像均通过 Tongyi-MAI/Z-Image-Turbo 模型生成。
核心特征
- 命名来源:数据集名称基于 Danbooru 格式 的文本描述,且图像风格为 动漫风格(anime-stylized)。
- 数据规模:预计最终包含 6,144 个独立样本,适合用于对文本到图像模型(如 Stable Diffusion)进行 LoRA 微调。
- 语言:英文(English)。
数据集生成方式
-
标签选取与分类:
- 从 Danbooru 标签中选取了 7 类标签,包括性别、时间段、场景、活动、眼睛颜色、头发颜色和头发类型,具体如下表所示:
标签 类别 1girl, 1boy 性别 evening, morning, night, day 大致时间 beach, city, school, bedroom, shopping mall, park 场景 standing, sitting, drinking, eating 活动 dark-brown eyes, brown eyes, blue eyes, green eyes 眼睛颜色 black hair, brown hair, blonde hair, red hair 头发颜色 straight hair, curly hair 头发类型 -
组合生成:使用 Python 标准库
itertools.product计算所有标签组合,共生成多种提示词(prompt)。每个提示词由所有类别中选取的标签以逗号连接而成,例如:"1girl, morning, school, sitting, green eyes, red hair, curly hair"。 -
图像生成:
- 在生成时,每个提示词前附加一段固定的动漫风格描述(如:
"Screenshot of a high-quality anime-stylized render...")。 - 图像尺寸固定为 512x512 像素,并以 PNG 格式(无损压缩)存储。
- 在生成时,每个提示词前附加一段固定的动漫风格描述(如:
-
数据记录:
- 生成的图像路径与简化后的提示词(仅包含 Danbooru 标签)以字典形式存储在
merger.json文件中,结构如下: json [ { "prompt": "string", "completion": "string" }, { "prompt": "1girl, morning, school, sitting, green eyes, red hair, curly hair", "completion": "./images/1087.png" } ]
- 生成的图像路径与简化后的提示词(仅包含 Danbooru 标签)以字典形式存储在
使用方式
-
数据访问:从
https://huggingface.co/datasets/hamzah0asadullah/Smallbooru/raw/main/merger.json获取merger.json文件,然后根据需要下载对应的图像文件。 -
示例代码:可使用 Python 的
requests包加载数据集,示例如下: python from json import loads from requests import getbase_url = "https://huggingface.co/datasets/hamzah0asadullah/Smallbooru" merger_path = f"{base_url}/raw/main/merger.json" dataset = loads(get(merger_path).text)
print("第一个样本:") print("提示词:", dataset[0]["prompt"]) print("图像 URL:", f"{base_url}/resolve/main/images/{dataset[0][completion].split(/)[-1]}")
适用场景
- LoRA 微调:适用于在小型模型(如 SD1.5)上进行 LoRA 微调,由于样本数量有限,不适合全参数微调。
- 风格学习:数据集图像质量较高,且提示词中未包含元标签描述质量,可使微调模型倾向于生成高质量结果。
- 素材使用:可用于其他模型卡、文章或网页中作为示例图像或占位符。
其他信息
- 许可证:Apache-2.0
- 任务类型:text-to-image(文本到图像)
- 标签:anime(动漫)、synthetic(合成)