祁连山国家公园土地利用类型(Classification)(1990-2020)
收藏国家青藏高原科学数据中心2023-11-13 更新2024-03-01 收录
下载链接:
https://data.tpdc.ac.cn/zh-hans/data/2a3d6fa9-421f-42e6-9f20-918a203d16c6
下载链接
链接失效反馈官方服务:
资源简介:
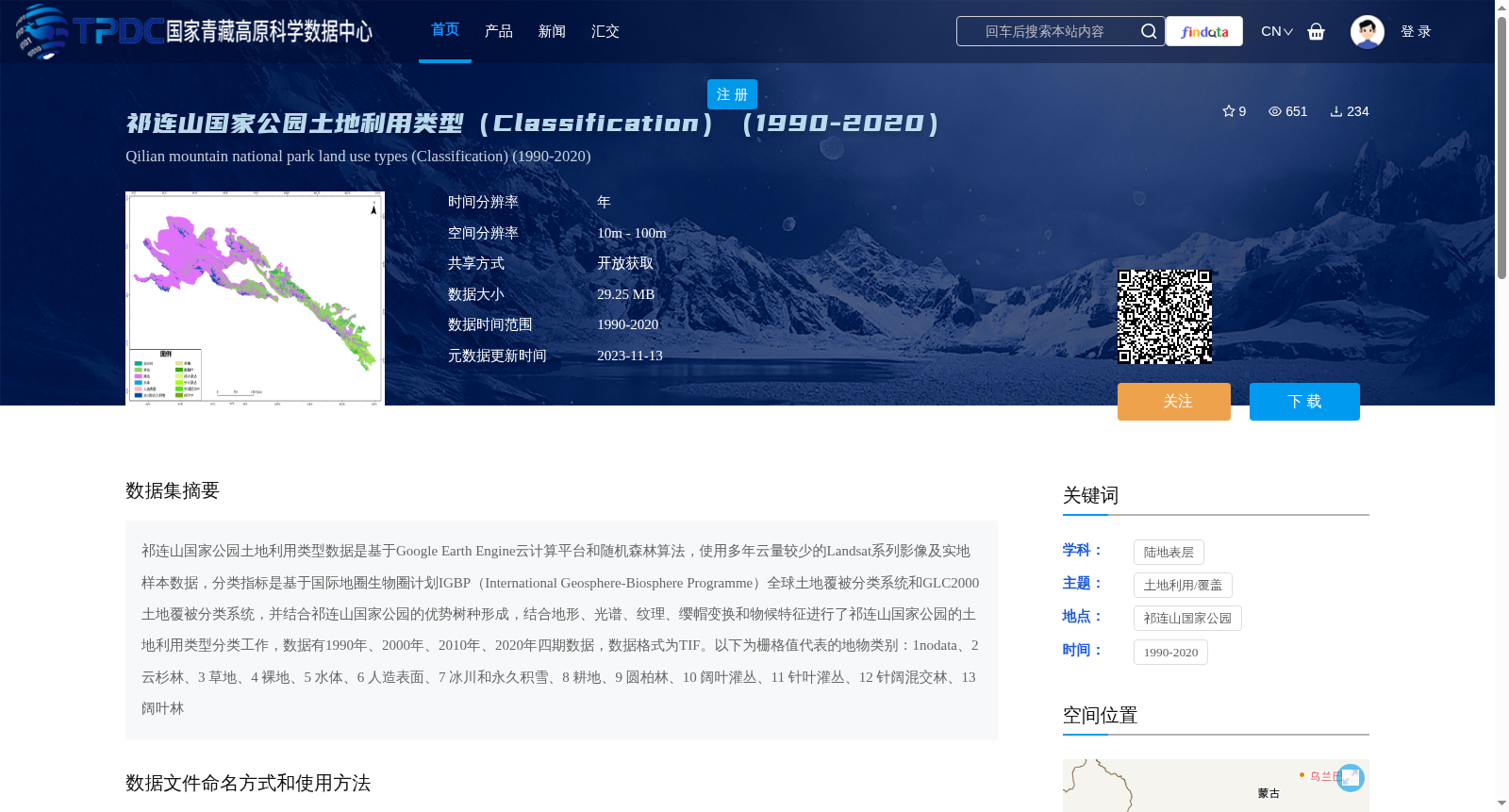
祁连山国家公园土地利用类型数据是基于Google Earth Engine云计算平台和随机森林算法,使用多年云量较少的Landsat系列影像及实地样本数据,分类指标是基于国际地圈生物圈计划IGBP(International Geosphere-Biosphere Programme)全球土地覆被分类系统和GLC2000土地覆被分类系统,并结合祁连山国家公园的优势树种形成,结合地形、光谱、纹理、缨帽变换和物候特征进行了祁连山国家公园的土地利用类型分类工作,数据有1990年、2000年、2010年、2020年四期数据,数据格式为TIF。以下为栅格值代表的地物类别:1nodata、2 云杉林、3 草地、4 裸地、5 水体、6 人造表面、7 冰川和永久积雪、8 耕地、9 圆柏林、10 阔叶灌丛、11 针叶灌丛、12 针阔混交林、13 阔叶林
The land use and land cover (LULC) dataset of Qilian Mountains National Park was developed using the Google Earth Engine (GEE) cloud computing platform and the Random Forest algorithm. It utilizes multi-year Landsat series imagery with relatively low cloud cover and field survey sample data. The classification framework was established based on the International Geosphere-Biosphere Programme (IGBP) global land cover classification system and the GLC2000 land cover classification system, combined with the dominant tree species within Qilian Mountains National Park. The classification of land use types in the park was conducted by integrating topographic, spectral, texture, Tasseled Cap transformation, and phenological features. The dataset includes four temporal phases: 1990, 2000, 2010, and 2020, and is stored in TIF format. The raster values and their corresponding land cover categories are as follows: 1 represents nodata, 2 represents spruce forest, 3 represents grassland, 4 represents bare land, 5 represents water body, 6 represents artificial surface, 7 represents glacier and permanent snow, 8 represents cultivated land, 9 represents juniper forest, 10 represents broad-leaved shrub, 11 represents coniferous shrub, 12 represents mixed coniferous and broad-leaved forest, and 13 represents broad-leaved forest.
提供机构:
年雁云
创建时间:
2023-05-22
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集提供了1990-2020年祁连山国家公园的土地利用类型分类数据,基于Landsat影像和随机森林算法生成,包含13种地物类别,空间分辨率为10m-100m,适用于生态研究和土地利用分析。
以上内容由遇见数据集搜集并总结生成


