Macaron
收藏Hugging Face2026-02-11 更新2026-02-12 收录
下载链接:
https://huggingface.co/datasets/AlaaAhmed2444/Macaron
下载链接
链接失效反馈官方服务:
资源简介:
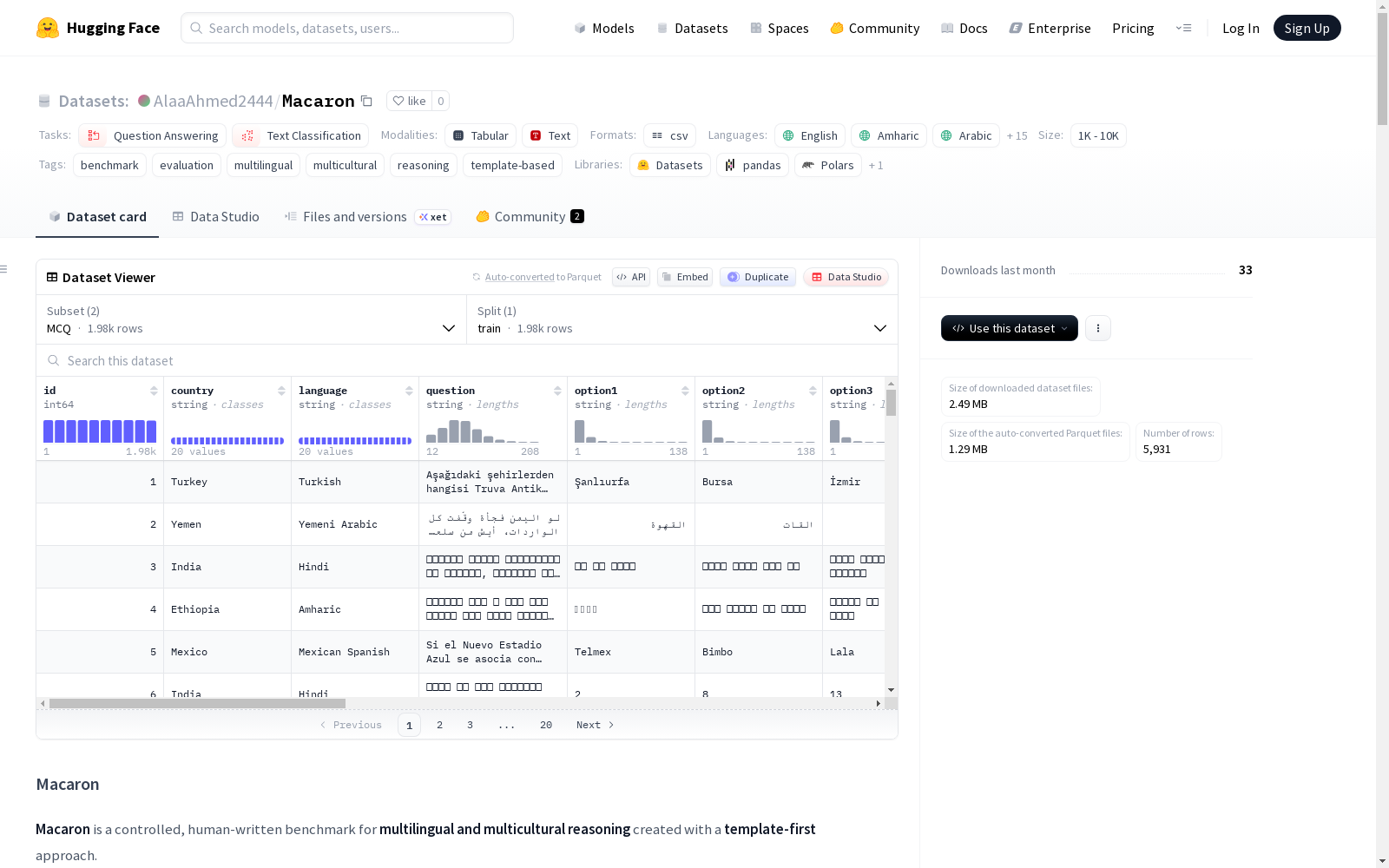
Macaron 是一个用于多语言和多文化推理的受控、人工编写的基准数据集,采用模板优先的方法创建。每个示例在英语和本地语言之间进行场景对齐,从而在文化基础上实现推理的受控比较。数据集包含两种配置:多选题(MCQ)和判断题(True-False),分别有 1,977 和 3,954 行数据。每个多选题生成 1 行 MCQ 数据和 2 行 True-False 数据,每行包含英语和本地语言的文本。数据集覆盖 20 个文化背景,涉及 20 种本地语言,并标注了多种推理类型(如数学推理、常识推理、因果推理等)和文化方面(如农业、食品、教育等)。适用于多语言大模型的零样本和少样本评估、跨语言鲁棒性分析以及按推理类型和文化领域的诊断分析。
Macaron is a controlled, human-authored benchmark dataset for multilingual and multicultural reasoning, constructed using a template-first approach. Each example aligns scenarios between English and local languages, enabling controlled comparison of reasoning grounded in specific cultural contexts. The dataset features two configurations: Multiple-Choice Question (MCQ) and True-False, with 1,977 and 3,954 rows respectively. Each multiple-choice question instance generates 1 MCQ row and 2 True-False rows, with each row containing text in both English and the corresponding local language. The dataset covers 20 cultural backgrounds and encompasses 20 local languages, and is annotated with diverse reasoning types (e.g., mathematical reasoning, commonsense reasoning, causal reasoning, etc.) and cultural dimensions (e.g., agriculture, food, education, etc.). It is suitable for zero-shot and few-shot evaluation of multilingual large language models, cross-lingual robustness analysis, as well as diagnostic analysis categorized by reasoning type and cultural domain.
创建时间:
2026-01-29
搜集汇总
数据集介绍
构建方式
在跨语言推理评估领域,Macaron数据集采用了一种创新的模板优先构建方法。该数据集通过精心设计的100个可复用模板,将推理类型与文化元数据紧密结合,确保了内容的系统性和可控性。每个模板均包含多种推理类别与文化维度标签,由专家团队基于20个不同文化背景进行人工撰写,实现了英语与本地语言在情境上的严格对齐。这种构建方式不仅保证了数据的多样性与代表性,还为跨语言模型的对比分析提供了可靠基础。
特点
Macaron数据集的核心特征在于其广泛的多语言与文化覆盖范围,涵盖了从汉语到约鲁巴语等20种语言及其对应的文化语境。数据集通过场景对齐设计,使每个实例在英语与本地语言间保持一致性,从而支持精准的跨语言推理比较。此外,数据集细致标注了七种推理类型与二十二个文化维度,如数学推理、常识推理及饮食文化等,为模型性能的细粒度诊断提供了丰富维度。这种结构化设计使得Macaron成为评估多语言大语言模型在多元文化背景下推理能力的理想工具。
使用方法
该数据集主要应用于多语言大语言模型的零样本与少样本评估,以及跨语言鲁棒性分析。用户可通过Hugging Face的datasets库轻松加载MCQ、True-False及Templates三种配置,分别对应双语选择题、验证陈述及原始模板数据。在应用时,建议将数据集用于模型性能的横向对比与诊断,避免将其作为训练数据或用于泛化文化结论。通过场景对齐的输入,研究者能够深入探究模型在不同语言与文化维度上的推理差异,从而推动更具包容性的人工智能系统发展。
背景与挑战
背景概述
随着人工智能向多语言与跨文化理解领域深入拓展,构建能够系统评估模型在多样化文化语境下推理能力的基准测试成为关键需求。Macaron数据集应运而生,由Alaa Elsetohy等研究人员于近期创建,旨在通过模板优先的方法,提供一种受控、人工编写的多语言与多文化推理评估工具。该数据集覆盖英语及19种本土语言,囊括20个文化语境,其核心研究问题聚焦于探究大型语言模型在不同文化背景与推理类型下的表现差异,从而推动跨文化自然语言处理技术的发展,并为模型鲁棒性与公平性评估提供重要参考。
当前挑战
Macaron数据集致力于解决多语言与多文化推理评估中的核心挑战,即如何在严格控制变量条件下,衡量模型对文化特定知识的理解与逻辑推理能力。构建过程中的主要挑战体现在两方面:一是确保跨语言场景对齐的严谨性,需在英语与各本土语言间保持语义与情境的一致性,避免因翻译偏差引入噪声;二是文化维度标注的复杂性与代表性难题,需在涵盖22个日常生活领域的同时,平衡文化覆盖的广度与深度,并规避对特定文化群体的简化或刻板表征。
常用场景
经典使用场景
在跨语言人工智能评估领域,Macaron数据集以其精心设计的模板化方法,为多语言与多文化推理任务提供了标准化的测试平台。该数据集通过场景对齐的双语实例,支持模型在零样本或少样本设置下进行多选问答与二元分类验证,尤其适用于评估大型语言模型在不同文化语境中的推理泛化能力。研究者可依据其标注的推理类型与文化维度,系统分析模型在数学、常识、因果等复杂推理任务上的表现差异。
衍生相关工作
基于Macaron数据集的设计理念与结构,学术界已衍生出系列聚焦文化敏感性与推理可解释性的研究工作。部分研究扩展了其模板体系至低资源语言对,构建了更细粒度的方言变体评估集;另有工作结合其文化维度标签,开发了针对特定领域(如民俗叙事或商业惯例)的专项诊断工具。这些衍生研究不仅深化了对多文化推理机制的理论探索,也为构建更具包容性的人工智能评估生态提供了方法论借鉴。
数据集最近研究
最新研究方向
在跨语言人工智能领域,Macaron数据集以其独特的模板优先构建方法和场景对齐设计,为多语言与多文化推理评估提供了精细化的基准。当前研究前沿聚焦于利用该数据集探索大型语言模型在多元文化语境下的零样本与少样本推理能力,特别是在数学、常识、因果及空间等复杂推理类型上的跨语言鲁棒性。热点议题涉及模型对22个日常生活文化维度的理解深度,如饮食习俗、社会关系与节庆传统等,旨在诊断模型在全球化部署中的文化适应性与偏差。这一研究方向不仅推动了多语言人工智能评估向更公平、更可控的方向发展,也为构建具有文化敏感性的下一代智能系统奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


