Magpie-Qwen2-Pro-200K-English
收藏Hugging Face2024-07-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Magpie-Align/Magpie-Qwen2-Pro-200K-English
下载链接
链接失效反馈官方服务:
资源简介:
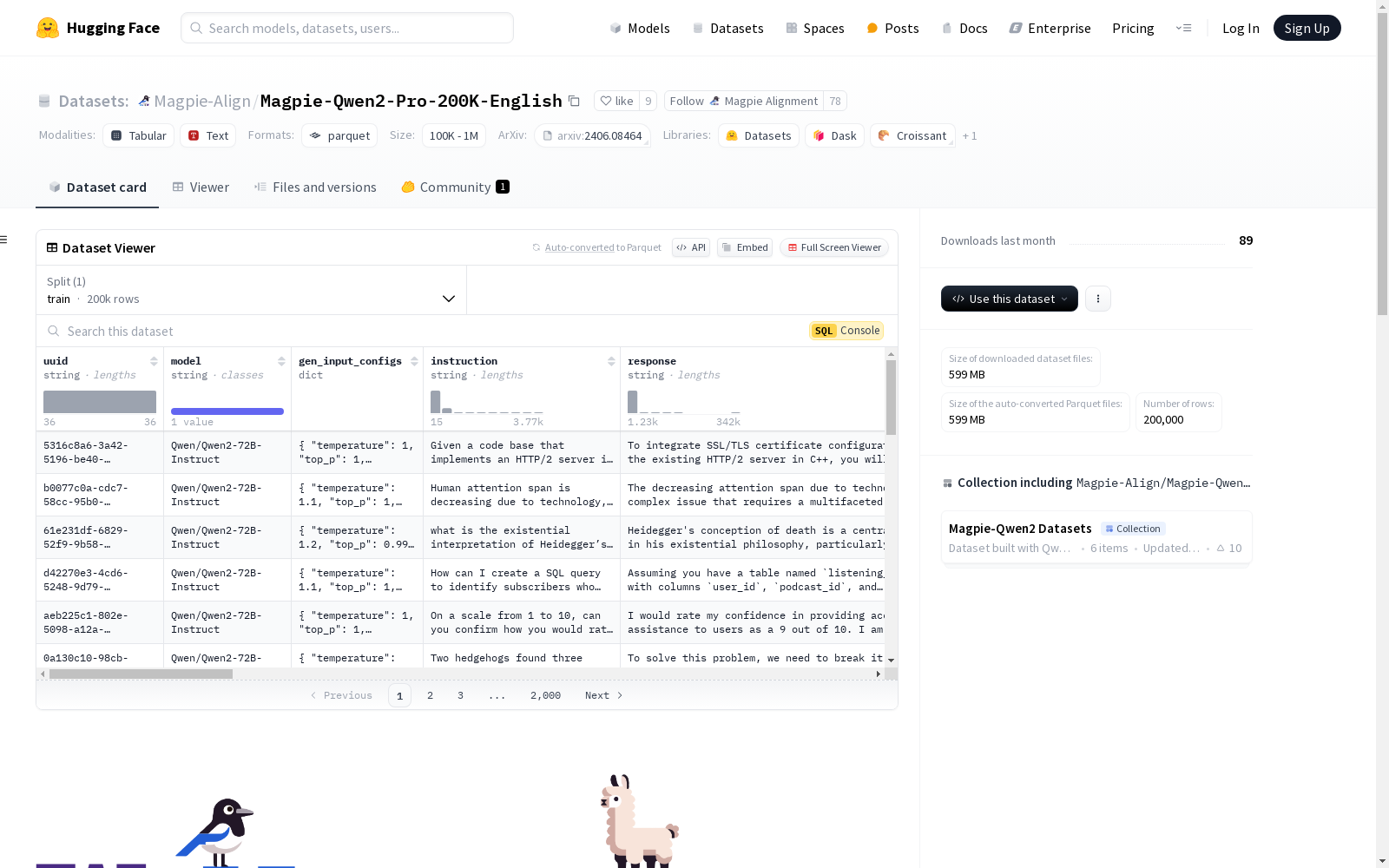
该数据集包含多个特征,如uuid、model、gen_input_configs等,每个特征都有其特定的数据类型。gen_input_configs是一个结构化特征,包含多个子特征。数据集分为训练集,包含200000个样本。数据集的大小和下载大小也有明确记录。
This dataset includes multiple features, such as uuid, model, gen_input_configs and others, each with its specific data type. gen_input_configs is a structured feature that encompasses multiple sub-features. The dataset is split into a training set containing 200,000 samples. The size of the dataset and its download size are also explicitly recorded.
创建时间:
2024-07-02
原始信息汇总
数据集概述
数据集信息
-
特征列表:
uuid: 字符串model: 字符串gen_input_configs: 结构体temperature: 浮点数top_p: 浮点数input_generator: 字符串seed: 空值extract_input: 字符串
instruction: 字符串response: 字符串conversations: 列表from: 字符串value: 字符串
task_category: 字符串other_task_category: 序列字符串task_category_generator: 字符串difficulty: 字符串intent: 字符串knowledge: 字符串difficulty_generator: 字符串input_quality: 字符串quality_explanation: 字符串quality_generator: 字符串llama_guard_2: 字符串reward_model: 字符串instruct_reward: 浮点数min_neighbor_distance: 浮点数repeat_count: 整数min_similar_uuid: 字符串instruction_length: 整数response_length: 整数language: 字符串
-
数据分割:
train: 200,000个样本,大小为1,007,184,254.428362字节
-
数据集大小:
- 下载大小: 599,475,522字节
- 数据集大小: 1,007,184,254.428362字节
-
配置:
default配置:train分割:data/train-*路径
可用标签
- 输入长度: 指令中的字符总数
- 输出长度: 响应中的字符总数
- 任务类别: 指令的具体类别
- 输入质量: 指令的清晰度、具体性和连贯性,评级为非常差、差、一般、好和优秀
- 输入难度: 处理指令所需知识的水平,评级为非常容易、容易、中等、难或非常难
- 最小邻居距离: 数据集中最近邻居的嵌入距离,可用于过滤重复或相似实例
- 安全性: 由meta-llama/Meta-Llama-Guard-2-8B标记的安全标签
- 奖励: 奖励模型给出的特定指令-响应对的输出
- 语言: 指令的语言
过滤设置
- 输入质量: ≥ 好
- 指令奖励: ≥ -10
- 语言: 英语
- 移除重复和不完整的指令(例如,以":"结尾)
- 选择响应最长的200,000个数据
数据集导航
- Qwen2 72B Instruct:
- Magpie-Qwen2-Pro-1M: 100万原始对话
- Magpie-Qwen2-Pro-300K-Filtered: 应用过滤器选择30万高质量对话
- Magpie-Qwen2-Pro-200K-Chinese: 应用过滤器选择20万高质量中文对话
- Magpie-Qwen2-Pro-200K-English: 应用过滤器选择20万高质量英语对话
搜集汇总
数据集介绍
构建方式
Magpie-Qwen2-Pro-200K-English数据集的构建基于自合成方法,利用对齐的大型语言模型(如Llama-3-Instruct)生成用户查询。通过输入仅包含左侧模板的提示,模型能够自动生成用户消息,从而产生大量指令及其响应。随后,通过综合分析和筛选,从生成的400万条指令中精选出30万条高质量实例,最终形成该数据集。
特点
该数据集包含丰富的特征字段,如指令长度、响应长度、任务类别、输入质量、输入难度、最小邻居距离等。输入质量分为‘非常差’到‘优秀’五个等级,输入难度则从‘非常容易’到‘非常困难’五个级别。此外,数据集还包含安全标签和奖励模型输出,确保数据的多样性和高质量。所有数据均为英文,且经过严格的重复和不完整指令过滤。
使用方法
Magpie-Qwen2-Pro-200K-English数据集适用于监督微调(SFT)任务,尤其适合用于提升大型语言模型的指令对齐能力。用户可通过Hugging Face平台直接下载数据集,并结合Qwen2-72B-Instruct模型进行微调。数据集中的高质量指令和响应对可用于训练模型,以提升其在特定任务上的表现。此外,数据集的最小邻居距离字段可用于过滤重复或相似实例,进一步提升训练效果。
背景与挑战
背景概述
Magpie-Qwen2-Pro-200K-English数据集是由Qwen/Qwen2-72B-Instruct模型生成的,旨在为大语言模型(LLMs)的对齐任务提供高质量的指令数据。该数据集的创建基于Magpie项目,该项目提出了一种自合成方法,通过从已对齐的LLM中提取指令数据,解决了现有开源数据创建方法在扩展性和多样性上的局限性。数据集的核心研究问题在于如何高效生成大规模、高质量的指令数据,以支持LLM的对齐任务。该数据集的研究成果已在arXiv上发布,并展示了在某些任务上,使用Magpie数据进行微调的模型性能与官方Llama-3-8B-Instruct模型相当,甚至超越了其他公开数据集。
当前挑战
Magpie-Qwen2-Pro-200K-English数据集在构建过程中面临的主要挑战包括:1) 数据质量的保证,尽管通过自合成方法生成了大量指令数据,但如何从中筛选出高质量、多样化的实例仍是一个难题;2) 数据重复与相似性问题,尽管通过最小邻居距离等指标进行过滤,但仍需进一步优化以去除冗余数据;3) 指令的多样性与复杂性平衡,如何在保证指令清晰、具体的同时,涵盖广泛的任务类别和难度级别,是数据集构建中的关键挑战。此外,数据集的安全性和伦理问题也需要在生成过程中进行严格把控,以确保生成的指令数据符合社会伦理标准。
常用场景
经典使用场景
在自然语言处理领域,Magpie-Qwen2-Pro-200K-English数据集被广泛用于训练和评估大型语言模型(LLMs)。通过该数据集,研究人员能够生成高质量的指令数据,进而优化模型的指令对齐能力。其经典使用场景包括模型微调、指令生成任务以及模型对齐性能的评估。
实际应用
在实际应用中,Magpie-Qwen2-Pro-200K-English数据集被用于开发智能助手、聊天机器人以及自动化客服系统。通过使用该数据集,企业能够训练出更加智能、响应更加准确的AI系统,从而提升用户体验和服务效率。此外,该数据集还被用于教育领域,帮助开发智能教学工具。
衍生相关工作
基于Magpie-Qwen2-Pro-200K-English数据集,研究者们开发了多种经典工作。例如,利用该数据集进行监督微调(SFT)的模型在AlpacaEval、ArenaHard和WildBench等对齐基准测试中表现优异。此外,该数据集还被用于探索指令生成与模型对齐的新方法,推动了自然语言处理领域的前沿研究。
以上内容由遇见数据集搜集并总结生成


