AmaSQuAD
收藏arXiv2025-02-04 更新2025-02-11 收录
下载链接:
https://huggingface.co/datasets/nebhailema/AmaSquad
下载链接
链接失效反馈官方服务:
资源简介:
AmaSQuAD数据集是由卡内基梅隆大学的研究团队创建的,它是将广泛使用的SQuAD 2.0数据集翻译成阿姆哈拉语的一个版本。该数据集旨在解决阿姆哈拉语自然语言处理资源匮乏的问题,通过翻译和后处理技术生成,用于提取式问题回答模型的训练。AmaSQuAD的创建为阿姆哈拉语的问题回答研究提供了宝贵的数据资源,有助于推动该领域的发展。
The AmaSQuAD dataset was developed by a research team at Carnegie Mellon University. It is an Amharic-language version of the widely adopted SQuAD 2.0 dataset. Designed to mitigate the shortage of natural language processing resources for the Amharic language, this dataset was constructed using translation and post-processing technologies, and is tailored for training extractive question answering models. The creation of AmaSQuAD offers a valuable data resource for Amharic question answering research, and contributes to promoting advancements in this research domain.
提供机构:
卡内基梅隆大学
创建时间:
2025-02-04
搜集汇总
数据集介绍
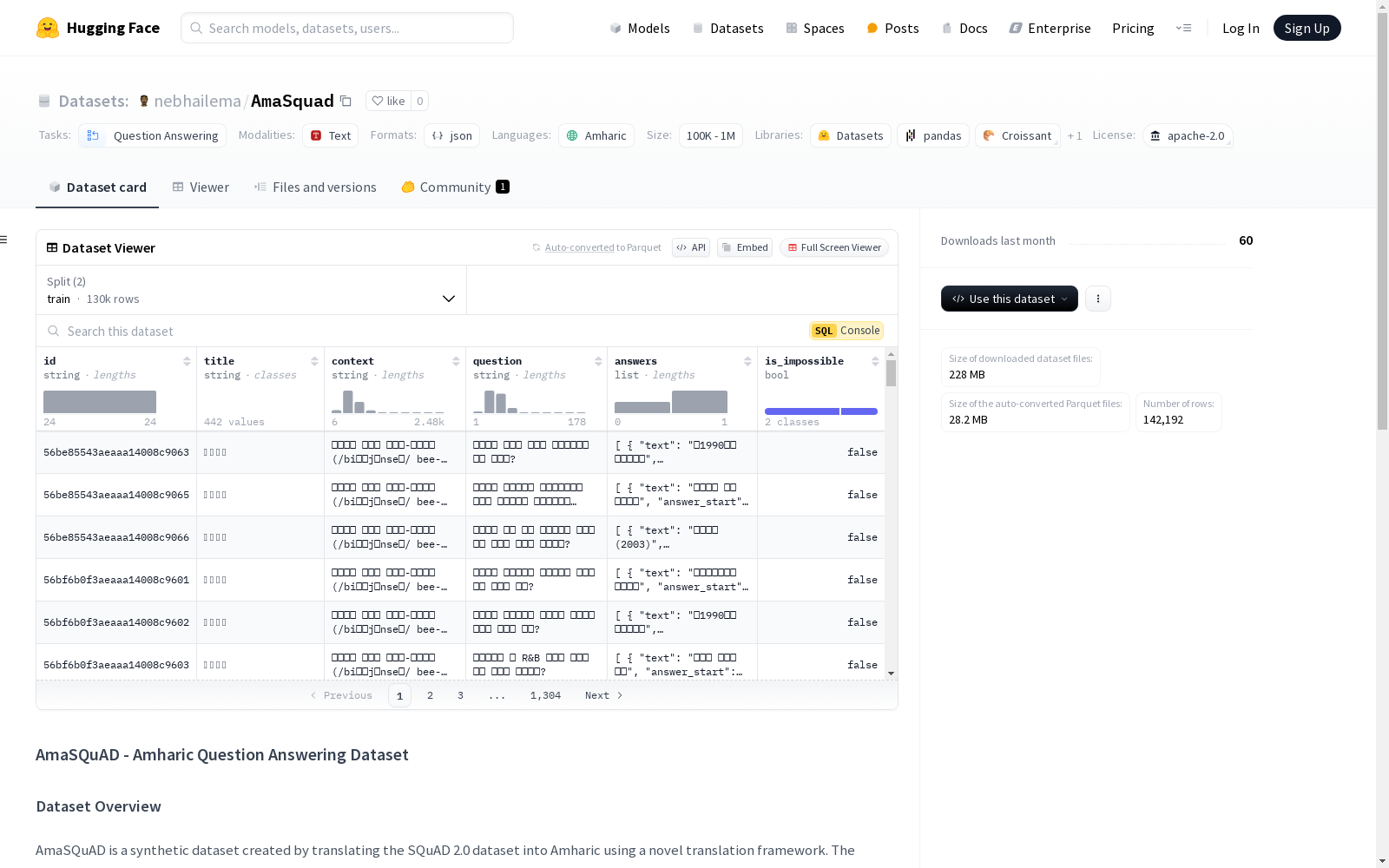
构建方式
AmaSQuAD 数据集的构建基于将 SQuAD 2.0 数据集翻译成阿姆哈拉语。首先,使用 Google Translate 通过 Deep Translator Python 库将 SQuAD 2.0 的标题、上下文和问题翻译成阿姆哈拉语。然后,使用基于 BERT 的模型进行微调,利用阿姆哈拉语数据生成文本嵌入。通过计算翻译上下文中文本跨度与翻译答案之间的余弦相似度,以及最长公共子序列(LCS)来选择答案跨度。此外,还考虑了答案跨度在翻译上下文中的位置,以减少翻译答案与上下文之间的不匹配。最后,对 XLM-R 模型进行微调,以提高阿姆哈拉语问答任务的性能。
特点
AmaSQuAD 数据集的特点是它提供了一个针对阿姆哈拉语问答任务的基准数据集。该数据集包括来自 SQuAD 2.0 的翻译问题和答案,以及使用机器翻译技术生成的翻译上下文。数据集还包含大量无法回答的问题,这有助于评估问答模型的鲁棒性。AmaSQuAD 数据集的另一个特点是它使用了高级技术来减少翻译问题和答案之间的不匹配。此外,AmaSQuAD 数据集的构建方式使其成为一个宝贵的资源,可以用于训练阿姆哈拉语问答模型。
使用方法
AmaSQuAD 数据集可用于训练和评估阿姆哈拉语问答模型。数据集可以用于微调 XLM-R 等模型,以提高其在阿姆哈拉语问答任务上的性能。此外,AmaSQuAD 数据集还可以用于研究翻译问题和答案之间的不匹配问题。数据集的使用方法包括加载数据集,进行数据预处理,以及训练和评估问答模型。
背景与挑战
背景概述
自然语言处理(NLP)领域的研究中,问答系统(QA)是一个核心任务,旨在准确回答自然语言提出的问题。然而,对于低资源语言,如阿姆哈拉语,缺乏足够的NLP资源和工具,这限制了问答系统的发展。为了解决这个问题,Carnegie Mellon大学的Nebiyou Daniel Hailemariam、Blessed Guda和Tsegazeab Tefferi等研究人员创建了一个名为AmaSQuAD的数据集。该数据集是基于SQuAD 2.0的阿姆哈拉语版本,旨在为阿姆哈拉语问答系统提供高质量的训练数据。AmaSQuAD数据集的创建,对于推动阿姆哈拉语问答系统的发展具有重要意义。
当前挑战
AmaSQuAD数据集在创建过程中面临着一些挑战。首先,翻译后的问题和答案可能存在不匹配的问题,这会影响问答系统的准确性。其次,翻译后的文本可能包含多个答案实例,这增加了确定正确答案的难度。为了解决这些问题,研究人员使用了一种基于余弦相似度和最长公共子序列(LCS)的翻译框架。此外,他们还使用了XLM-R模型对AmaSQuAD数据集进行微调,以提高阿姆哈拉语问答系统的性能。
常用场景
经典使用场景
AmaSQuAD数据集最经典的使用场景是作为低资源语言抽取式问答(Extractive Question Answering, QA)的基准数据集。该数据集通过将广泛使用的英文SQuAD 2.0数据集翻译成阿姆哈拉语(Amharic),为低资源语言的QA任务提供了宝贵的训练数据。AmaSQuAD数据集不仅涵盖了阿姆哈拉语的特点,还引入了不可回答问题的概念,要求模型能够准确识别并处理没有明确答案的问题。
实际应用
AmaSQuAD数据集的实际应用场景包括开发阿姆哈拉语问答系统、信息检索、文本摘要和机器翻译等领域。通过对AmaSQuAD数据集进行训练,可以构建能够理解并回答阿姆哈拉语问题的问答系统,为阿姆哈拉语用户提供了更便捷的信息获取方式。此外,AmaSQuAD数据集还可以用于开发阿姆哈拉语信息检索系统,提高信息检索的准确性和效率。同时,AmaSQuAD数据集还可以用于文本摘要和机器翻译任务的训练,提高阿姆哈拉语文本处理的质量和准确性。
衍生相关工作
AmaSQuAD数据集衍生了多项相关研究工作。例如,基于AmaSQuAD数据集,研究人员对阿姆哈拉语问答模型进行了微调,取得了显著的性能提升。此外,AmaSQuAD数据集还被用于开发其他低资源语言的问答数据集,如阿拉伯语和波斯语。这些相关工作进一步推动了低资源语言NLP技术的发展,并为构建多语言问答系统提供了重要的数据资源。
以上内容由遇见数据集搜集并总结生成


