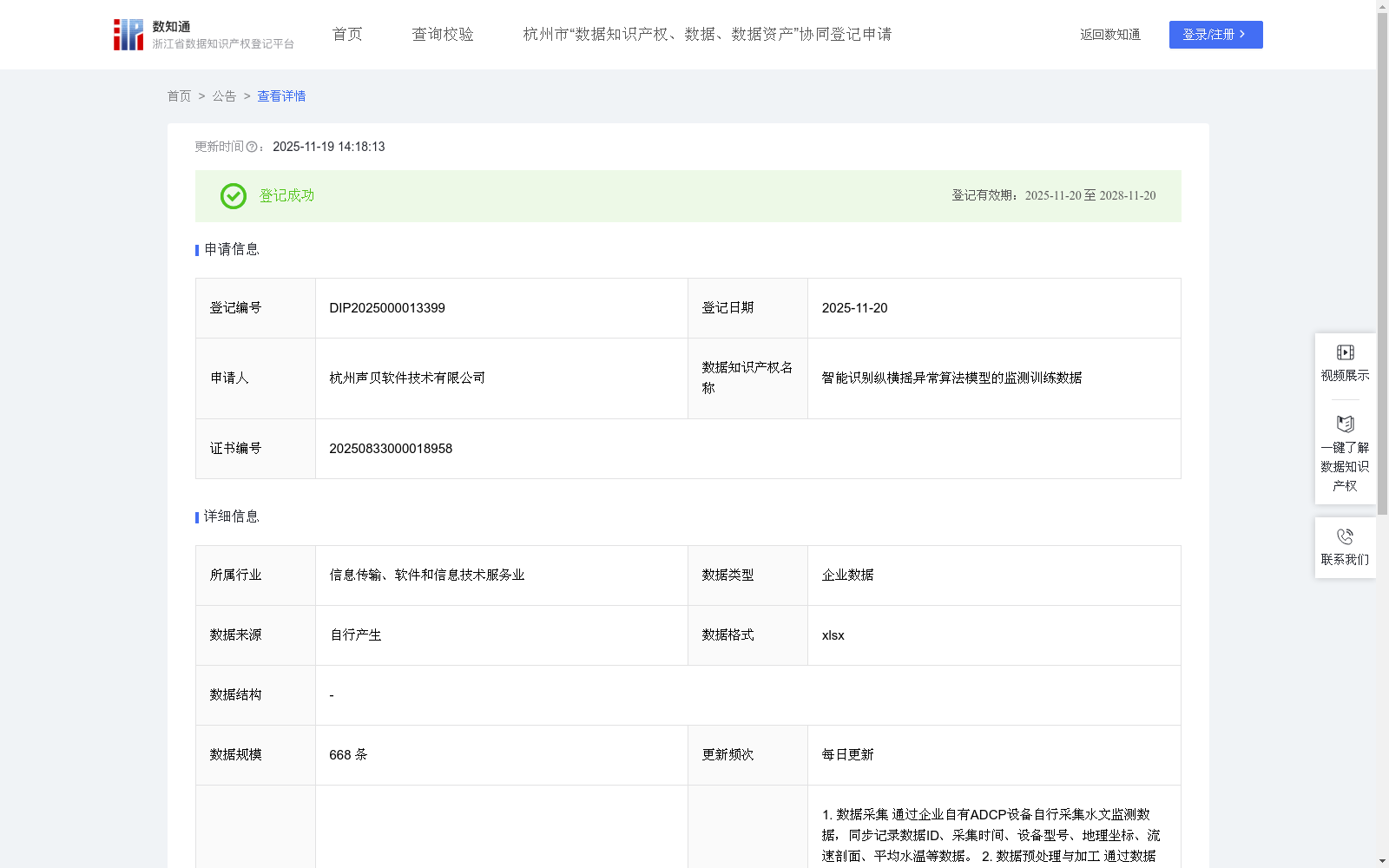
智能识别纵横摇异常算法模型的监测训练数据
收藏浙江省数据知识产权登记平台2025-11-19 更新2025-11-26 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8402470
下载链接
链接失效反馈官方服务:
资源简介:
本数据集主要用于提升AI模型对船舶纵横摇异常行为的识别能力与精确性。通过对该数据集的训练,使AI模型能够精准识别船舶在复杂海况下的异常摇摆动作,并可应用于港口航道监测、海上作业平台安全预警及船舶自动驾驶系统等场景。同时,本数据集可为海洋气象预警分析、船舶航行安全评估等智慧海洋建设项目提供决策依据,提升海上安全管理智能化水平。
1. 数据采集
通过企业自有ADCP设备自行采集水文监测数据,同步记录数据ID、采集时间、设备型号、地理坐标、流速剖面、平均水温等数据。
2. 数据预处理与加工
通过数据清洗剔除异常值、重复数据,按7:2:1比例划分训练集/验证集/测试集。基于流速剖面数据,结合船舶运动学模型计算船舶姿态角度,采用波能谱分析方法,通过流速时间序列计算波浪高度阈值。
设置多级标注体系:
一级标签:正常航行/异常纵横摇
二级标签:横摇异常/纵摇异常/复合异常
3. 模型选择与初始化
采用LSTM(长短期记忆网络)预训练模型,初始化参数并优化超参数:学习率0.001-0.0001动态调整,批量大小8-32动态调整,时间步长适配船舶运动周期;集成卡尔曼滤波模块提升数据稳定性。
4. 模型训练
基于TensorFlow实施分布式训练,采用混合精度训练(FP16)提升效率。设置训练时长,数据增强模拟复杂海况,添加噪声干扰、数据缺失、浑浊水体等特效,模拟极端海况条件。设置早停机制(patience=20),梯度裁剪:max_norm=1.0。
5. 模型评估
在训练模型的过程中,使用验证集调整超参数,训练完成后在测试集上评估模型表现,评估指标包含:
基础性能指标:准确率、误报率
场景鲁棒性测试:极端海况检出率
并设置渐进式测试:单船异常→多船交互异常,标准海况→极端海况(如台风天气)
This dataset is primarily designed to enhance the recognition capability and accuracy of AI models for identifying abnormal pitch and roll behaviors of ships. Training AI models on this dataset enables precise identification of abnormal ship swinging motions under complex sea conditions, with applications in scenarios such as port channel monitoring, safety early warning for offshore operating platforms, and ship autonomous driving systems. Meanwhile, this dataset can provide decision-making support for smart ocean construction projects including marine meteorological early warning analysis and ship navigation safety assessment, thereby improving the intelligence level of maritime safety management.
1. Data Collection
Hydrological monitoring data is collected independently using the enterprise's self-owned ADCP equipment, with synchronized recording of data ID, collection time, equipment model, geographic coordinates, velocity profile, average water temperature and other related data.
2. Data Preprocessing and Processing
Outliers and duplicate data are removed via data cleaning, and the dataset is split into training, validation and test sets at a ratio of 7:2:1. Based on the velocity profile data, ship attitude angles are calculated in combination with the ship kinematics model. The wave energy spectrum analysis method is adopted to calculate the wave height threshold from the velocity time series. A multi-level annotation system is established:
First-level label: Normal navigation / Abnormal pitch and roll
Second-level label: Abnormal roll / Abnormal pitch / Compound abnormal
3. Model Selection and Initialization
A pre-trained LSTM (Long Short-Term Memory) model is utilized. Parameters are initialized and hyperparameters are optimized: dynamically adjust the learning rate within the range of 0.001-0.0001, dynamically adjust the batch size between 8 and 32, and adapt the time step to the ship's motion cycle. A Kalman filtering module is integrated to improve data stability.
4. Model Training
Distributed training is implemented based on TensorFlow, and mixed-precision training (FP16) is adopted to enhance training efficiency. The training duration is set, and data augmentation is used to simulate complex sea conditions, including adding effects such as noise interference, data missing and turbid water to replicate extreme sea conditions. An early stopping mechanism (patience=20) is configured, and gradient clipping is performed with max_norm=1.0.
5. Model Evaluation
During the model training process, the validation set is used to adjust hyperparameters. After training is completed, model performance is evaluated on the test set. The evaluation metrics include:
Basic performance metrics: Accuracy, False Positive Rate
Scenario robustness test: Detection rate under extreme sea conditions
Progressive testing is also designed: Single-ship abnormal behavior → Multi-ship interactive abnormal behavior, Standard sea conditions → Extreme sea conditions (such as typhoon weather)
提供机构:
杭州声贝软件技术有限公司
创建时间:
2025-08-03
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于训练AI模型识别船舶纵横摇异常行为的监测数据,包含668条企业数据,每日更新。它通过LSTM模型和波能谱分析等方法,提升模型在复杂海况下的识别精确性,应用于港口监测、海上安全预警等场景,支持智慧海洋建设。
以上内容由遇见数据集搜集并总结生成


