ins_filtered
收藏Hugging Face2026-04-21 更新2026-04-22 收录
下载链接:
https://huggingface.co/datasets/TheFinAI/ins_filtered
下载链接
链接失效反馈官方服务:
资源简介:
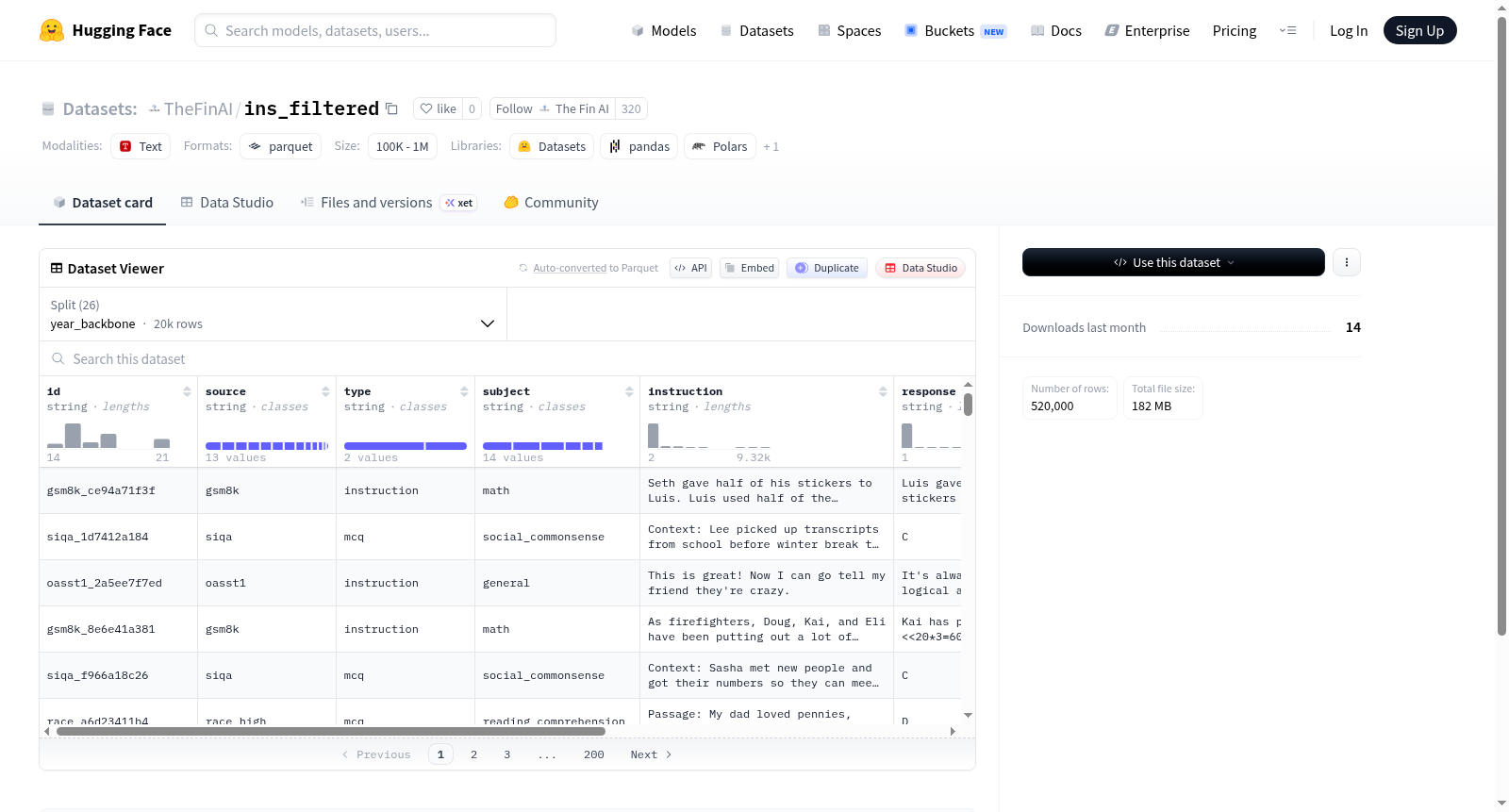
该数据集包含26个按年份划分的数据子集(2001年至2025年,以及一个基础集),每个子集包含20,000条结构化数据记录。数据集采用parquet格式存储,总大小约285MB。每条记录包含以下字段:唯一标识符(id)、数据来源(source)、类型(type)、主题(subject)、指令(instruction)、响应(response)、过滤标记(needs_filter)、来源类型(src_type)和年份(year)。数据集未提供明确的背景说明,但从字段结构推断可能适用于指令响应生成、对话系统训练等自然语言处理任务。各年份子集数据量保持均衡,便于时间序列分析或年度对比研究。
This dataset consists of 26 year-partitioned data subsets (from 2001 to 2025, plus a base subset), with each subset containing 20,000 structured data records. The dataset is stored in Parquet format, with an approximate total size of 285 MB. Each record includes the following fields: unique identifier (id), data source (source), type (type), subject (subject), instruction (instruction), response (response), filter flag (needs_filter), source type (src_type), and year (year). No explicit background description is provided for the dataset, but it can be inferred from the field structure that it is suitable for natural language processing tasks such as instruction response generation and dialogue system training. The data volume of each year-partitioned subset is balanced, facilitating time series analysis or annual comparative studies.
提供机构:
The Fin AI
创建时间:
2026-04-21
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,指令微调数据集的质量直接影响大语言模型的泛化能力。ins_filtered数据集专为指令筛选研究而构建,其数据源自多样化的公开语料库,每条样本包含唯一的标识符(id)、来源(source)、指令类型(type)、主题(subject)、具体指令(instruction)及对应的响应(response),并标注了是否需要过滤(needs_filter)的布尔标签。数据集按年份划分为27个切片,从2001年至2025年,每个切片包含20,000条样本,覆盖了长达25年的时间跨度,从而确保数据在时间维度上的广泛代表性。所有数据以Parquet格式存储,便于高效读取和处理。
特点
该数据集的核心特点在于其精细化的标注结构与丰富的时间维度。每条样本不仅记录了指令和响应的原始内容,还通过needs_filter字段明确指示该样本是否应被过滤,为研究者提供了直接的监督信号,用于训练或评估指令质量筛选模型。按年份划分的切片设计,使得研究者能够分析指令数据在时间序列上的演变趋势,例如不同年代的主题分布变化或指令复杂度的提升。此外,数据集包含多种来源类型(src_type),确保数据来源的多样性,避免单一数据源带来的偏差。
使用方法
ins_filtered数据集的使用方式灵活且面向实际应用场景。研究者可通过Hugging Face Datasets库轻松加载指定年份的切片,例如使用load_dataset函数选择'split'参数为'year_2023'来获取特定时间段的样本。每条样本的instruction和response字段可直接用于微调指令遵循模型,而needs_filter标签则可用于训练二分类过滤器,以自动识别低质量或有害的指令-响应对。跨年份的切片组合能够用于构建时间敏感的实验设置,例如评估模型在不同历史时期数据上的表现差异。
背景与挑战
背景概述
在大语言模型快速迭代的浪潮中,指令微调数据的质量直接影响模型的对齐效果与泛化能力。ins_filtered数据集诞生于这一背景下,由某研究团队针对现有公开指令数据集中的噪声与冗余问题而构建,旨在为模型微调提供更干净、更具代表性的训练样本。该数据集涵盖从2001年至2025年间的多源指令数据,每个年份子集包含20000条样本,总规模达54万条,每条数据均经过严格筛选并标注了是否需要过滤的标签,从而为后续数据质量评估与过滤策略研究提供了标准化的基准。自发布以来,ins_filtered已成为数据清洗与指令微调领域的重要参考资源,推动了学界对高质量训练数据构建方法的深入探索。
当前挑战
指令微调数据面临的核心挑战在于如何系统性地识别并剔除低质量、重复或有害的样本,以避免模型学到错误的关联或生成不安全的内容。ins_filtered数据集所解决的正是这一领域问题,通过引入二元过滤标签(needs_filter),为数据质量评估提供了可量化的判别依据。在构建过程中,团队面临着跨年份数据格式不一致、来源多样(src_type字段涵盖多种数据源)以及指令-响应对语义对齐难度大的现实困境,尤其是如何设计高效的过滤策略以平衡样本数量与质量之间的关系,成为制约数据集实用性的关键瓶颈。此外,随着年份增长,数据分布偏移与语言演变也增加了过滤标准的动态适应性挑战。
常用场景
经典使用场景
在自然语言处理与指令微调领域,ins_filtered数据集以其独特的过滤标注信息(needs_filter字段)和跨年份的细粒度划分(涵盖2001年至2025年),成为评估指令数据质量与时间演变的经典基准。研究者常利用其按年分割的子集,探究不同时期生成的指令-响应对在语义一致性、主题分布及过滤需求上的差异,从而揭示大语言模型训练数据随时间推移的质量变迁规律。该数据集尤其适用于构建数据筛选策略的验证场景,通过分析其提供的源类型(src_type)与主题(subject)标签,可系统性地测试各类去噪算法对冗余或低质量指令的识别效能。
衍生相关工作
基于ins_filtered数据集,学术界已衍生出多项探索指令质量自动评估与过滤机制的前沿工作。例如,研究者利用其年际分割特性,构建了时序敏感的数据选择模型,揭示了不同时期指令在长度、复杂度与情感极性上的漂移现象,并提出了基于主题一致性的动态过滤算法。此外,该数据集催生了一系列关于数据源类型(src_type)对模型微调效果影响的研究,推动了跨领域指令适配技术的发展。这些衍生工作共同深化了学界对训练数据质量控制中时间维度重要性的认知。
数据集最近研究
最新研究方向
在指令微调与安全对齐领域,ins_filtered数据集凭借其跨越二十余年的指令-响应对结构,成为探究大语言模型(LLM)行为演化与过滤机制的前沿载体。该数据集按年份分片(2001至2025年)的独特设计,使其能捕捉不同时期语言模式与潜在风险的动态变迁,尤其契合当前对模型毒性、偏见及越狱攻击等安全问题的研究热点。通过分析各年度子集中'needs_filter'字段的分布,研究者可追溯有害内容在训练数据中的历史涌现规律,进而开发更具鲁棒性的对抗性过滤算法。这一资源对于推动可控文本生成、构建负责任的AI系统具有里程碑意义,为理解语言模型在时间维度上的脆弱性提供了不可多得的实验场域。
以上内容由遇见数据集搜集并总结生成


