anle-toaan-gov-vn
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://huggingface.co/datasets/tmquan/anle-toaan-gov-vn
下载链接
链接失效反馈官方服务:
资源简介:
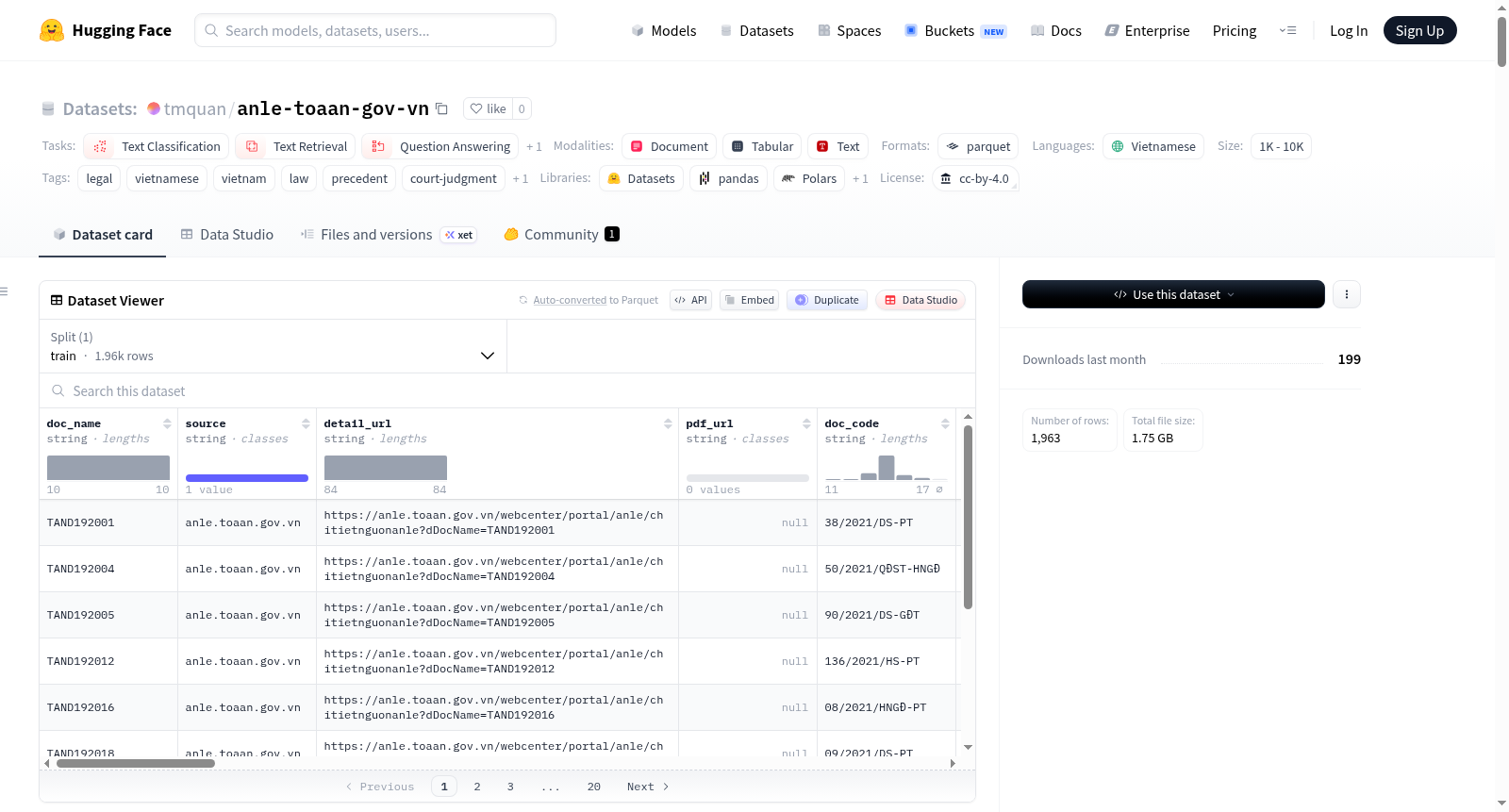
Án lệ — Vietnamese Legal Precedents 数据集包含从越南最高法院官方法律先例门户网站 `anle.toaan.gov.vn` 爬取的 1,963 条案例判决。每条先例以多种形式提供:原始 PDF、解析后的 Markdown、结构化 JSON 记录(包含实体、法规引用、适用条款、采用日期等)、2,048 维密集嵌入向量以及 2-D 投影(PCA / t-SNE / UMAP + HDBSCAN 聚类 ID)。数据集适用于文本分类、文本检索、句子相似度和特征提取等任务,特别适合法律领域的自然语言处理研究。数据集还包含详细的统计分析,如文档长度、采用年份分布、法律领域分类、程序级别、实体提取和嵌入分析等。数据集遵循 CC-BY 4.0 许可,要求使用时引用原始来源和 Hugging Face 上的重新分发。
The Án lệ — Vietnamese Legal Precedents Dataset contains 1,963 case judgments scraped from the official legal precedent portal of the Supreme People's Court of Vietnam, `anle.toaan.gov.vn`. Each precedent is offered in diverse formats: original PDF files, parsed Markdown files, structured JSON records (encompassing entities, statutory citations, applicable articles, adoption dates, and other relevant metadata), 2,048-dimensional dense embedding vectors, and 2D projections (PCA / t-SNE / UMAP + HDBSCAN cluster IDs). This dataset is applicable to tasks such as text classification, text retrieval, sentence similarity, and feature extraction, and is especially suitable for natural language processing research within the legal domain. Furthermore, the dataset includes detailed statistical analyses including document length, adoption year distribution, legal domain classification, procedural levels, entity extraction results, and embedding analysis. The dataset is released under the CC-BY 4.0 license, and users are required to cite the original source and the redistribution on Hugging Face when using the dataset.
创建时间:
2026-04-27
原始信息汇总
数据集概述:Án lệ — Vietnamese Legal Precedents
基本信息
- 语言: 越南语 (vi)
- 许可证: CC-BY 4.0
- 数据规模: 1K < n < 10K(共 1,963 条判例)
- 任务类型: 文本分类、文本检索、句子相似度、特征提取
- 标签: 法律、越南语、判例、最高法院
数据来源
所有判例来自越南最高人民法院官方判例门户网站 anle.toaan.gov.vn,是公开的法律文件。
数据集配置
数据集包含 4 个配置,对应数据处理管线的 4 个阶段:
| 配置名 | 行数 | 阶段 | 关键列 |
|---|---|---|---|
parse |
1,963 | 解析 | doc_name, source, detail_url, pdf_url, text, num_pages, char_len, parser_model, parsed_at, text_hash |
extract |
1,963 | 提取 | doc_name, text_hash, text, entities, relations, statute_refs, adopted_date, precedent_number, applied_article_*, principle_text, court |
embed |
1,963 | 嵌入 | doc_name, text_hash, embedding (2048维浮点), embedding_dim, embedding_model_id, embedding_chunks_used, embedding_chunking |
reduce |
1,963 | 降维 | doc_name, text_hash, pca_x/y, tsne_x/y, umap_x/y, cluster_id |
仓库结构
README.md 数据集卡片 notebook.ipynb 探索性数据分析(EDA)笔记本 data/ parse.parquet 15 MB · 文本 + 解析元数据 extract.parquet 16 MB · 文本 + 结构化提取 embed.parquet 23 MB · 2048维密集向量 reduce.parquet 90 KB · PCA / t-SNE / UMAP + 聚类ID assets/ 嵌入的静态PNG图片 raw/ pdf/<doc_name>.pdf 原始抓取PDF(共1.4 GB) pdf/<doc_name>.url 来源详情URL md/<doc_name>.md 解析后的Markdown正文 md/<doc_name>.meta.json 解析器元数据侧车 jsonl/<doc_name>.jsonl 单记录JSONL提取
存储统计: 总共9,832个文件,约1.66 GB。
数据处理管线
| 阶段 | 读取 | 写入 | 工具 |
|---|---|---|---|
download |
抓取 anle.toaan.gov.vn 列表 |
pdf/<doc>.pdf + .url |
aiohttp爬虫 (AnleDocumentDownloader) |
parse |
pdf/*.pdf |
md/<doc>.md + <doc>.meta.json |
nvidia/nemoretriever-parse |
extract |
md/*.md |
jsonl/<doc>.jsonl |
规则+LLM提取器(实体、法条引用、适用条款) |
embed |
jsonl/*.jsonl |
parquet/embeddings/*.parquet |
nvidia/llama-nemotron-embed-1b-v2(2048维,滑动窗口) |
reduce |
parquet/embeddings/*.parquet |
parquet/reduced/*.parquet |
scikit-learn PCA + t-SNE, umap-learn UMAP, HDBSCAN |
语料库分析
文档长度
- 中位篇幅:9页 / 20,430字符
- 最长篇幅:90页(224,753字符)
- 每个文档生成一条记录,与长度无关
年份分布
- 覆盖范围:1952 – 2025年
- 2017年后(正式确立Án lệ体系)数量高度集中
- 提取到判决日期(
adopted_date)的比例为 98.5%(1,933/1,963)
法律部门分布
| 法律部门 | 文档数 | 占比 |
|---|---|---|
| 民事 (Dân sự) | 886 | 45.1% |
| 刑事 (Hình sự) | 467 | 23.8% |
| 行政 (Hành chính) | 327 | 16.7% |
| 商法 (Kinh doanh thương mại) | 99 | 5.0% |
| 婚姻家庭 (Hôn nhân & gia đình) | 43 | 2.2% |
| 其他 (Quyết định khác) | 32 | 1.6% |
| 劳动 (Lao động) | 8 | 0.4% |
| 未知/未解析 | 101 | 5.1% |
程序级别分布
| 程序级别 | 文档数 | 占比 |
|---|---|---|
| 上诉审 (Phúc thẩm) | 1,085 | 55.3% |
| 再审监督 (Giám đốc thẩm) | 690 | 35.1% |
| 一审 (Sơ thẩm) | 65 | 3.3% |
| 重审 (Tái thẩm) | 18 | 0.9% |
| 未知/未解析 | 105 | 5.4% |
实体提取
- 共提取 140,863个实体跨度 和 34,190条法条引用
- 实体类型分布:
| 标签 | 数量 |
|---|---|
DATE(日期) |
79,538 |
ARTICLE(条款) |
34,190 |
ORG-COURT(法院机构) |
27,060 |
PRECEDENT(判例) |
75 |
适用条款
- 每个判例适用一个条款(
applied_article_number),覆盖率为 99.1% - 最常适用的条款:Điều 26(161次)、Điều 51(107次)、Điều 337(75次)
嵌入表示
- 模型:
nvidia/llama-nemotron-embed-1b-v2 - 维度: 2,048维 (float32)
- 分块策略: 滑动窗口 (sliding)
- 所有向量已做L2归一化
- 长文档采用滑动窗口分块后均值池化
降维投影
- 预计算了 PCA / t-SNE / UMAP 坐标及 HDBSCAN 聚类ID
- 按法律部门着色时:民事(蓝色)和刑事(红色)在t-SNE和UMAP中形成良好分离区域
- 按程序级别着色时:区分度不如按法律部门明显
- HDBSCAN聚类结果:两个大簇(c0: 536文档, c1: 328文档)+ 1,099个噪声点
搜集汇总
数据集介绍
构建方式
该数据集源自越南最高人民法院官方判例门户网站(anle.toaan.gov.vn),采用端到端流水线构建,包含下载、解析、提取、嵌入与降维五个阶段。首先,通过异步爬虫获取1,963份PDF原始判例。随后,利用NVIDIA的Nemo Retriever Parse模型将PDF转换为结构化Markdown文本。在提取阶段,结合规则与大型语言模型,从文本中抽取出实体(如日期、法院、法条引用)、判例编号、采纳日期及适用法条等结构化信息。最后,采用NVIDIA Llama-Nemotron嵌入模型生成2,048维稠密向量,并通过PCA、t-SNE与UMAP技术进行降维投影,辅以HDBSCAN聚类分析,形成完整的向量化判例库。
特点
该数据集具备多粒度、多模态的显著特征,提供从原始PDF、解析Markdown、结构化JSON记录到稠密向量投影的完整数据层次。它覆盖了1952年至2025年间跨越68年的越南判例,其中98.5%的判例成功解析出采纳日期,且文档长度中位数为9页、20,430字符。在法律领域分布上,民事、刑事与行政判例分别占45.1%、23.8%与16.7%,呈现出清晰的领域多样性。此外,数据集包含了超过14万条实体标注及3.4万条法条引用,并预计算了PCA、t-SNE、UMAP三种降维坐标与聚类标签,使研究者可即刻开展可视化分析,无需重新运行昂贵的降维计算。
使用方法
使用者可通过Hugging Face Datasets库直接加载四种配置之一:'parse'提供Markdown文本及元数据,'extract'额外包含结构化法律实体与引用,'embed'提供2,048维稠密向量,'reduce'则提供PCA、t-SNE、UMAP降维坐标与HDBSCAN聚类ID。此外,支持通过snapshot_download选择性下载原始PDF或解析后的Markdown文件。数据集附带了完整的探索性数据分析(EDA)Notebook,所有图表与统计结果均可复现。对于需要细粒度访问的场景,data目录下的parquet文件可直接用Pandas或DuckDB进行高效查询与分析。
背景与挑战
背景概述
越南司法体系在数字化转型进程中,判例数据的系统化与可计算性成为制约法律人工智能发展的关键瓶颈。由越南最高人民法院官方判例门户(anle.toaan.gov.vn)于2026年发布的Án lệ数据集,由TMQuan研究团队通过NeMo Curator流水线系统构建,收录了1963份经过完整处理的越南判例文档。该数据集的核心研究问题在于如何将非结构化的法律判决书转化为结构化的可计算数据资源,涵盖从原始PDF解析、实体识别到密集向量嵌入的全链条处理。作为首个公开可用的越南语法律判例数据集,它填补了低资源语言法律自然语言处理领域的空白,为法律文本分类、语义检索、相似度计算等下游任务提供了基准资源,其影响力辐射至东南亚法律信息化研究领域。
当前挑战
数据集的构建面临双重挑战。在领域问题层面,越南判例体系具有独特的法律渊源结构,判例文本中混合了引用法条、审判层级标识、事实认定与法律论证等多层次语义信息,传统的序列标注模型在提取法律实体、识别法律原则与适用法条间的逻辑关系时易产生歧义,特别是当同一判例引用不同法典的多个条款时,需要精细的上下文消歧能力。在构建过程中,流水线各环节均存在技术瓶颈:PDF解析阶段需处理越南语特有的标点符号变体与法律文书排版格式;实体抽取环节依赖规则与混合方法的结合,但规则提取器对无明确编码名称的法条引用(如仅有'Điều 51'而无法典名称)的覆盖率不足;嵌入阶段采用滑动窗口策略处理长文档,但均值池化可能稀释法律论证的关键细节。此外,数据版权合规与隐私保护(已隐去当事人全名)也为公开发布增加了法律层面的复杂性。
常用场景
经典使用场景
在法律自然语言处理领域,Án Lệ——越南判例数据集为研究者提供了从原始PDF到结构化法律知识的全链条数据资源。该数据集包含1963份由越南最高人民法院官方判例门户网站爬取的裁决文书,涵盖民商事、刑事、行政等多个法律部门。其经典使用场景包括基于预训练嵌入向量的法律文档语义检索、判例文本的自动分类与聚类分析,以及利用降维投影进行法律主题的可视化探索。研究者可便捷地加载解析后的Markdown文本、结构化实体与法条引用记录,或直接使用2048维密集向量开展下游任务,为越南语法律智能系统提供了标准化的基准测试平台。
衍生相关工作
围绕该数据集已衍生出一系列开创性工作。其全流程处理管线(下载→解析→提取→嵌入→降维)为法律数据工程树立了可复现的范式,启发了其他小语种法律语料库的构建方法。基于该语料库,研究者开展了越南语法律实体识别与关系抽取的对比实验,探索了规则与LLM联合提取法条引用的最优策略。嵌入空间的聚类分析催生了关于判例“法律领域”与“审判层级”表征分离性的量化研究,证实了主题语义主导嵌入结构的特性。此外,数据集中降维投影与无监督聚类标签的预计算设计,为大规模法律文档的可视化分析与交互式探索提供了可直接复用的基础设施。
数据集最近研究
最新研究方向
在越南司法体系数字化的浪潮中,法律判例数据集`anle-toaan-gov-vn`为自然语言处理与法律智能的交叉研究提供了坚实的数据基座。该数据集不仅收录了越南最高人民法院官方门户发布的1963份判例全文,更创新性地构建了从原始PDF解析、结构化实体提取到2048维稠密向量嵌入的全流程管线,囊括了民事、刑事、行政等七大法律部门及上诉、再审等不同审级的判例。前沿研究正聚焦于利用该数据集进行法律领域的语义相似性计算、判例自动检索与推理,以及基于嵌入向量的法律文书聚类与主题建模,从而推动法律知识图谱的构建、量刑辅助系统的开发与法律文本的深度语义理解,为越南乃至整个东南亚地区的法律科技应用树立了重要的数据标杆。
以上内容由遇见数据集搜集并总结生成


