RenoBench
收藏arXiv2026-03-27 更新2026-03-28 收录
下载链接:
https://huggingface.co/datasets/public-knowledge-project/ref-annotation-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
RenoBench是由斯坦福大学等机构联合构建的首个公共领域引文解析基准数据集,旨在解决学术出版中真实场景下的异构引文标注问题。该数据集包含10,000条经过质量过滤的引文记录,覆盖8种语言及期刊论文、书籍等多元文献类型,数据源自SciELO、Redalyc等四大开放出版平台的PDF文本转换与JATS XML结构化匹配。通过算法平衡采样策略,数据集显著提升了多语言、多类型文献的覆盖率,为引文解析模型的训练与评估提供了高信噪比的真实语料。
RenoBench is the first public-domain citation parsing benchmark dataset jointly developed by Stanford University and other collaborating institutions, aiming to address the issue of heterogeneous citation annotation in real-world academic publishing scenarios. This dataset includes 10,000 quality-filtered citation records, covering 8 languages and diverse document types such as journal articles and books. The data is sourced from PDF text conversion and JATS XML structured matching of four major open access publishing platforms including SciELO and Redalyc. Through an algorithmic balanced sampling strategy, the dataset significantly enhances the coverage of multilingual and multi-type academic documents, providing high signal-to-noise ratio real-world corpora for the training and evaluation of citation parsing models.
提供机构:
斯坦福大学·教育学院; 西蒙弗雷泽大学·公共知识项目; DataCite; 加州大学总校长办公室·加州数字图书馆
创建时间:
2026-03-27
原始信息汇总
RenoBench数据集概述
数据集基本信息
- 数据集名称:RenoBench (Reference Annotation Benchmark)
- 主要任务:引文解析(Citation Parsing)
- 任务类别:标记分类、文本生成
- 标签:引文解析、参考文献、JATS-XML、学术交流、信息抽取、命名实体识别
- 数据规模:1K<n<10K
- 语言:英语、葡萄牙语、西班牙语、法语、德语、意大利语、俄语、中文
- 许可证:cdla-permissive-1.0
数据集描述
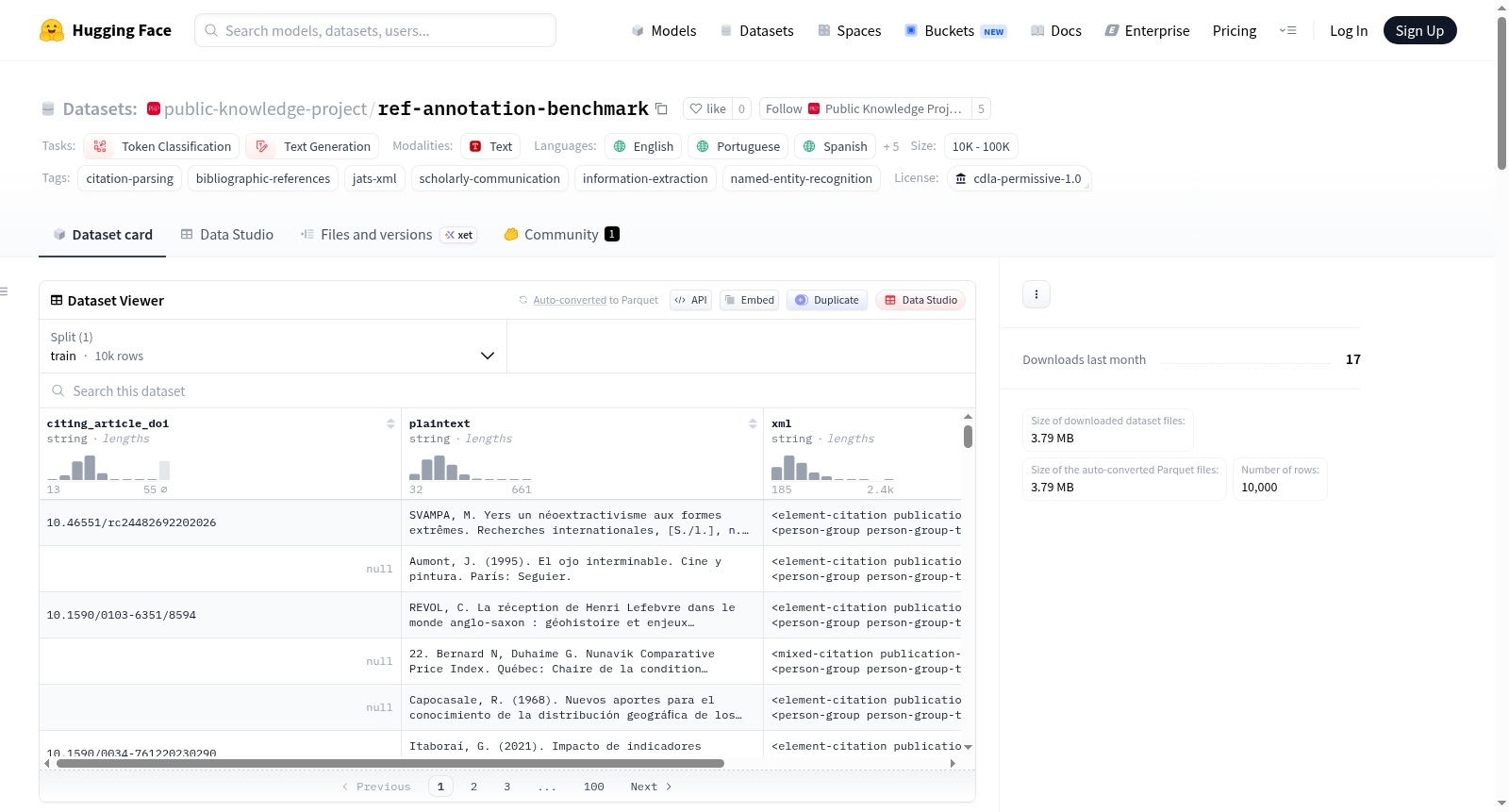
RenoBench是一个用于引文解析的标准化评估基准,包含10,000条纯文本引文及其对应的JATS XML结构化标注。
数据构成
- 总样本数:10,000条(训练集)
- 数据字段:
citing_article_doi:引用文章的DOI(可能为空)plaintext:从PDF中提取的纯文本引文xml:包含结构化参考文献字段的JATS XML标注source:出版平台来源(scielo, redalyc, ore, pkp)
数据来源与分布
- 数据来源平台:
- SciELO (Scientific Electronic Library Online):47%
- Redalyc (Red de Revistas Científicas de América Latina):24%
- Open Research Europe:14%
- PKP (Public Knowledge Project OJS journals):14%
- 语言分布:
- 英语:32%
- 葡萄牙语:30%
- 西班牙语:23%
- 法语:7%
- 德语:3%
- 意大利语:2%
- 俄语:2%
- 中文:1%
- 出版物类型分布:
- 期刊文章:53%
- 书籍:30%
- 网页:8%
- 学位论文:5%
- 会议论文集:4%
- 其他特征:
- 59%的引文包含持久标识符(DOI)
- 14%的引用文章是预印本
JATS XML标注元素
标注使用标准的JATS参考文献元素,包括:
<surname>:作者姓氏<given-names>:作者名或首字母<article-title>:被引文章标题<source>:期刊名称、书名或出版商<year>:出版年份<volume>:期刊卷号<issue>:期刊期号<fpage>,<lpage>:起始页和结束页<pub-id pub-id-type="doi">:数字对象标识符
数据收集流程
- PDF提取:使用markitdown将文章PDF转换为2. 引文提取:使用Llama-3.1-8B-Instruct提取纯文本引文,并进行程序化验证
- 匹配:使用归一化编辑距离(阈值≥0.75)将纯文本引文与JATS XML标注匹配
- 过滤:通过自动质量检查移除存在结构错误、字段格式错误或标注不一致的引文
- 抽样:使用学习到的抽样权重,在语言、出版物类型和来源之间进行平衡抽样
预期用途
- 基准测试:引文解析系统(GROBID、神经解析器、LLMs)
- 训练:用于引文解析的序列标注或文本到文本模型
- 评估:多语言和跨领域泛化能力
局限性
- 标注反映了出版商的实践,完整性可能有所不同
- 某些引文风格(法律、专利)代表性不足
- 语言分布反映了来源平台的人口统计特征
搜集汇总
数据集介绍
构建方式
在学术文献引用解析领域,现有基准往往局限于单一学科或合成数据,难以反映真实出版环境中的复杂性与多样性。RenoBench的构建旨在填补这一空白,其数据来源于四个公开出版平台——SciELO、Redalyc、PKP与Open Research Europe的公共领域PDF文献。通过将PDF转换为Markdown格式,并利用Llama-3.1-8B-Instruct模型提取纯文本引用,随后与对应的JATS XML标注进行相似度匹配,确保数据来源的真实性与准确性。在匹配得到的161,625条数据基础上,研究团队实施了多层次的质量过滤,包括结构验证、字段级校验与内容一致性检查,最终保留约71.3%的高质量引用对。为进一步提升数据集的代表性与平衡性,团队采用基于特征向量的优化采样策略,通过可学习参数调整采样权重,最终构建了一个包含10,000条引用、涵盖多语言、多文献类型与多出版环境的标准化评测数据集。
特点
RenoBench作为首个基于真实多生态系统条件的公开引用解析基准,其核心特点体现在高度的现实性与多样性。数据集涵盖了来自八个不同语言的引用,其中英语、葡萄牙语与西班牙语占据主导,同时包含法语、德语等语言,充分反映了全球学术交流的多语言特性。在文献类型上,数据集平衡收录了期刊论文、书籍、网站页面、学位论文及会议论文集等多种出版形式,其中约59%的引用包含持久标识符,增强了数据的可追溯性。数据来源分布于SciELO、Redalyc、ORE与PKP四大平台,确保了出版工作流与格式的异质性。此外,数据集通过严格的质控流程,有效规避了PDF提取噪声、多语言句法差异及出版流程特异性引入的误差,为引用解析模型提供了贴近实际应用场景的评测环境。
使用方法
RenoBench为引用解析系统的性能评估提供了标准化框架,其使用方法聚焦于模型在真实引用数据上的结构化标注能力。研究人员可将待评测模型——包括传统解析工具如GROBID或各类语言模型——在数据集上进行推理,任务目标是将纯文本引用解析为符合JATS标准的结构化字段。评测过程通常涉及提供少量标注示例作为提示,引导模型完成解析,并通过对比模型输出与数据集的JATS标注来计算召回率等指标。由于数据集的标注可能不完全覆盖所有有效字段,评估时需谨慎对待精确度指标,避免因标注缺失而低估模型性能。该数据集支持对模型在多语言、多文献类型场景下的鲁棒性进行系统分析,并可进一步用于微调领域专用模型,推动引用解析技术在学术索引与知识发现等下游应用中的发展。
背景与挑战
背景概述
在学术信息处理领域,引文解析作为实现机器可读引文的关键技术,长期面临缺乏标准化评估基准的困境。现有数据集往往局限于单一学科、依赖合成数据或处于非公开状态,难以全面反映真实出版环境中的复杂性与多样性。为应对这一挑战,斯坦福大学等机构的研究团队于2026年推出了RenoBench数据集。该数据集从SciELO、Redalyc等四个公共出版平台中提取真实PDF引文,并依据JATS标准进行结构化标注,旨在为引文解析任务提供首个源于多生态系统、公开可用的基准测试工具。RenoBench的建立不仅填补了该领域公共评估资源的空白,也为推动引文解析系统的可复现比较与性能优化奠定了重要基础。
当前挑战
RenoBench数据集致力于解决引文解析这一核心领域问题,其挑战在于如何准确、一致地从嘈杂且异构的纯文本引文中提取结构化字段,以适应多语言、多出版风格的复杂场景。在构建过程中,研究团队面临多重挑战:首先,从真实PDF中提取引文需克服格式噪声、多语言句法差异及出版商特定工作流程带来的干扰;其次,将纯文本引文与JATS XML标注进行高精度匹配,需设计稳健的相似度度量并处理大量不匹配或低质量数据;此外,为确保数据质量,需实施多层次自动化校验以剔除结构错误、字段混淆及内容不一致的样本,最终仅约71.3%的初始匹配数据通过筛选。这些挑战凸显了在真实学术出版条件下构建可靠引文解析基准的复杂性与必要性。
常用场景
经典使用场景
在学术出版与信息计量领域,引文解析作为构建知识网络的基础环节,长期面临数据标准化与评估体系缺失的挑战。RenoBench作为首个基于真实出版环境构建的公开引文解析基准数据集,其经典使用场景在于为各类引文解析系统提供统一、可复现的性能评估平台。该数据集通过从多平台、多语言的公开领域PDF中提取纯文本引文,并与JATS标准的结构化标注进行匹配,构建了一个包含噪声、异构性及多语言特性的测试环境。研究人员可利用RenoBench系统性地比较不同模型(如GROBID、Qwen、Llama等)在解析作者、标题、年份等结构化字段时的准确性与鲁棒性,从而推动引文解析技术向更实用、更可靠的方向演进。
实际应用
超越纯粹的学术评估,RenoBench在数字图书馆、学术搜索引擎和开放科学基础设施中具有直接的实际应用价值。例如,图书馆与出版商可利用基于该基准优化的引文解析工具,自动化处理海量学术文献的参考文献列表,将其高效转换为JATS等标准结构化数据,从而提升元数据构建的精度与效率。对于开放获取平台和引文索引服务(如OpenCitations),RenoBench有助于开发更健壮的解析器,以准确处理全球范围内不同语言、不同出版风格的引文,增强学术资源的互联性与可发现性。此外,它也为开发面向特定领域(如生物医学、社会科学)的专用引文分析工具提供了可靠的训练与验证数据来源。
衍生相关工作
RenoBench的建立不仅是一个评估终点,更催生了一系列相关的经典研究工作。其论文中详述的评估框架直接引导了对GROBID、Qwen系列、Llama、Mistral以及GPT-OSS等多种大语言模型在引文解析任务上的系统性性能对比,揭示了领域特定微调(如COMET发布的基于Qwen3-0.6B的LoRA适配器)对于提升任务性能的显著潜力。这些评估结果为后续研究指明了方向,例如开发更专注于处理多语言噪声、改进XML生成质量或融合领域知识的轻量化模型。RenoBench作为公共基础资源,预期将持续激励关于引文解析模型架构、训练策略以及其在细粒度学术知识抽取中应用的新探索。
以上内容由遇见数据集搜集并总结生成


