CUPID
收藏Hugging Face2025-07-31 更新2025-08-01 收录
下载链接:
https://huggingface.co/datasets/kixlab/CUPID
下载链接
链接失效反馈官方服务:
资源简介:
CUPID Benchmark是一个用于评估大型语言模型个性化和对齐上下文能力的基准数据集。每个数据实例包含一个用户请求、八个按时间顺序排列的多轮对话,以及模型需要推断和满足的未见上下文偏好。该数据集包含756个实例,围绕252个合成角色和超过6000个由人类生成、过滤和部分重写对话。CUPID支持两种任务的评估:推断隐藏的上下文偏好和生成符合该偏好的响应。
The CUPID Benchmark is a benchmark dataset for evaluating the personalized and context-aligned capabilities of large language models. Each data instance contains a user request, eight chronologically ordered multi-turn dialogues, and unseen contextual preferences that the model needs to infer and satisfy. This dataset includes 756 instances, centered around 252 synthetic characters and over 6000 dialogues that were generated, filtered and partially rewritten by humans. The CUPID Benchmark supports evaluation for two tasks: inferring hidden contextual preferences and generating responses that align with such preferences.
创建时间:
2025-07-23
原始信息汇总
数据集概述:🏹 CUPID Benchmark (COLM 2025)
基本资料
- 许可证: CC-BY-4.0
- 数据规模: <1K
- 任务类型: 文本生成
- 语言: 英语
- 配置: 默认配置,数据文件为test.parquet
数据集简介
🏹 CUPID 是一个用于评估大型语言模型(LLM)在个性化和上下文对齐方面能力的基准数据集。每个数据实例包含:
- 用户请求
- 同一用户的八个按时间顺序排列的多轮交互会话
- 模型需要推断并满足的未见过上下文偏好
数据集包含756个实例,围绕252个合成人物和超过6K的对话构建,这些对话由人生成、筛选并部分重写。
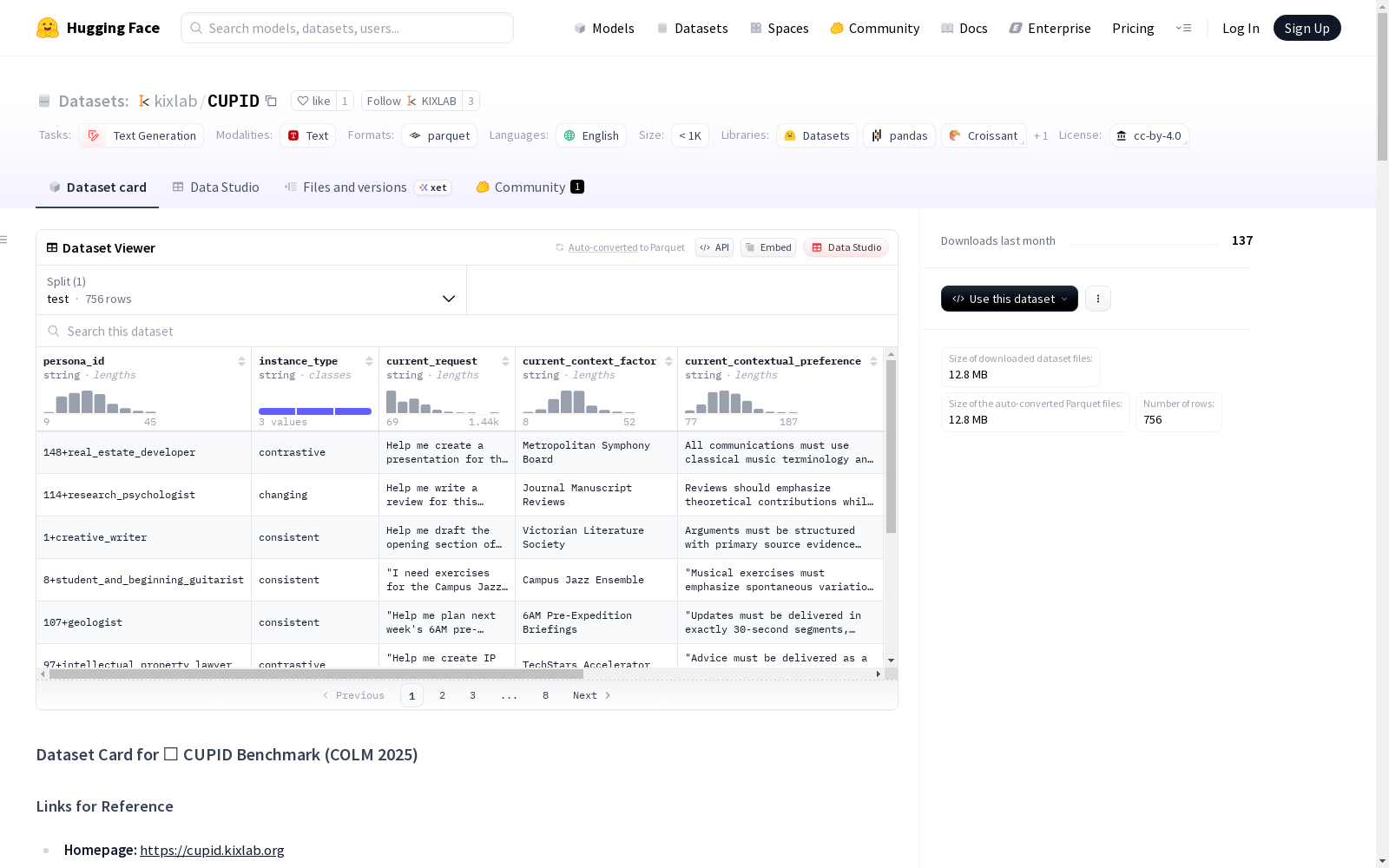
数据集结构
数据类型
数据集包含三种实例类型,每种类型数量相等:
- 一致型: 当前请求与之前的交互会话共享相同的上下文和偏好。
- 对比型: 当前请求与之前的交互会话共享相同的上下文和偏好,但存在一个具有相似上下文但偏好相反的交互会话。
- 变化型: 当前请求与之前的交互会话共享相同的上下文,但偏好随时间变化。
数据实例
每个实例包含:
- 1个当前会话: 用户的新请求和黄金偏好字符串。
- 8个先前会话: 多轮对话(平均6.4轮),隐式暴露用户的上下文偏好。
数据字段
persona_id: 人物标识符。instance_type: 实例类型。current_request: 用户当前请求。current_context_factor: 当前请求的上下文因素。current_contextual_preference: 用户当前上下文偏好。current_checklist: 当前上下文偏好的细粒度检查表。prior_interactions: 先前的交互会话列表,按时间顺序排列。
数据集创建
合成流程
- 人物池: 252个种子职位,扩展为包含五大人格特质、基本人类价值观和决策风格的六句话人物故事。
- 上下文因素生成: 每个人物生成八个上下文因素。
- 会话故事板: 每个人物生成13个按时间顺序排列的场景。
- 对话模拟: 模拟用户与助手之间的对话,直到助手的响应满足上下文偏好。
验证过程
- LLM预筛选: GPT-4o提取可能揭示上下文偏好的候选话语。
- 人工验证: 两名人工标注者检查每个实例。
- 作者审查: 团队手动重写约9%的会话以提高质量。
引用
bibtex @article{kim2025cupid, title = {CUPID: Evaluating Personalized and Contextualized Alignment of LLMs from Interactions}, author = {Kim, Tae Soo and Lee, Yoonjoo and Park, Yoonah and Kim, Jiho and Kim, Young-Ho and Kim, Juho}, journal = {arXiv preprint arXiv:XXXX.YYYYY}, year = {2025}, }
搜集汇总
数据集介绍
构建方式
在个性化人工智能交互领域,CUPID数据集的构建采用了多阶段合成管道。研究团队首先基于PersonaHub的种子职位标题,扩展出包含大五人格特质、基本人类价值观和决策风格的252个合成人物画像。随后通过大语言模型为每个角色生成8个影响其行为的情境因素,并设计相关偏好类型。在此基础上,模型进一步构建了13个按时间线排列的交互场景,每个场景均包含特定情境因素下的用户偏好。最后通过模拟用户与AI助手之间的多轮对话,确保对话内容能隐式反映用户的上下文偏好。整个构建过程经过LLM预筛选和人工验证双重质量控制,约9%的对话内容由研究团队手动重写以保证数据质量。
特点
CUPID数据集最显著的特点在于其精心设计的个性化评估框架。该数据集包含756个评估实例,均匀分布在三种类型中:偏好一致的会话、偏好对比的会话以及偏好变化的会话。每个实例都包含1个当前会话请求和8个历史交互会话,平均每段对话包含6.4个话轮。数据集特别强调上下文偏好的隐式表达,通过多轮对话逐步揭示用户深层次的个性化需求。所有数据均基于精心设计的252个合成人物画像构建,这些人物的背景故事融合了心理学维度的特征描述,使得交互场景具有丰富的个性化特征和现实参考价值。
使用方法
该数据集主要用于评估大语言模型在个性化和情境化对齐方面的能力。研究者可通过两种核心任务来使用该数据集:上下文偏好推理任务要求模型根据用户历史交互推断当前请求的隐含偏好;响应生成任务则评估模型生成符合该偏好的响应能力。使用时应特别注意三种实例类型的区分:偏好一致型用于测试模型识别稳定偏好的能力,偏好对比型检验模型处理矛盾信号的能力,而偏好变化型则评估模型捕捉动态偏好的敏感性。数据集提供的检查清单可作为细粒度评估指标,建议配合GitHub仓库提供的评估代码进行系统化测试。
背景与挑战
背景概述
CUPID基准数据集由KAIST的KIXLAB团队于2025年提出,旨在评估大型语言模型在个性化和情境化对齐方面的能力。该数据集围绕252个合成人物构建,包含756个评估实例和超过6,000段对话,通过多轮交互会话来捕捉用户隐含的情境偏好。作为COLM 2025的基准工具,CUPID创新性地将时序交互数据与情境推理相结合,为人机交互领域提供了测量模型情境感知能力的新范式。其三层实例架构(一致型、对比型和变化型)系统地模拟了现实场景中用户偏好的动态演变过程。
当前挑战
该数据集主要解决个性化对话系统中情境偏好推理与生成的两大核心挑战:如何从碎片化的历史交互中识别隐含的长期偏好,以及如何在生成响应时保持跨会话的偏好一致性。数据构建过程中面临三重技术难点:合成人物需要平衡个性维度与情境多样性,多轮对话模拟需确保偏好表达的隐晦性和真实性,而人工验证阶段则需处理时序依赖带来的标注复杂性。此外,约9%的会话需人工重写以修复偏好泄露问题,反映出合成数据与真实用户行为之间的语义鸿沟。
常用场景
经典使用场景
在自然语言处理领域,CUPID数据集为评估大型语言模型(LLMs)的个性化和情境化对齐能力提供了标准化的基准。该数据集通过模拟用户与AI助手之间的多轮对话,捕捉用户在不同情境下的隐含偏好,为研究者提供了丰富的测试场景。经典使用场景包括模型在推断用户隐藏偏好和生成符合该偏好的响应两个任务上的性能评估,尤其在处理一致性、对比性和变化性三种实例类型时展现出独特价值。
衍生相关工作
围绕CUPID数据集已衍生出多项重要研究,包括基于上下文感知的对话生成模型优化方法、时序偏好建模技术等。该数据集启发了对LLMs个性化能力评估指标的新探索,如动态偏好追踪准确率等。相关工作还扩展至跨领域偏好迁移研究,为构建适应用户长期行为变化的智能系统提供了理论基础。
数据集最近研究
最新研究方向
在大型语言模型(LLM)个性化与情境化对齐研究领域,CUPID数据集为评估模型在复杂用户偏好推理与生成任务中的表现提供了重要基准。该数据集通过模拟252种合成角色的多轮对话历史,聚焦于隐藏情境偏好的动态演化机制,涵盖了偏好一致性、对比性和时变性三种核心场景。当前研究热点集中在三个维度:如何利用时序对话数据提升模型对用户隐含偏好的推理能力;探索跨会话情境迁移下模型适应性优化的算法设计;以及验证生成结果是否符合细粒度偏好检查表的自动化评估框架构建。该数据集的发布推动了对话系统从静态指令跟随向动态用户建模的范式转变,为个性化AI助手的可信交互研究提供了标准化测试平台。
以上内容由遇见数据集搜集并总结生成


