dev-TIR_v3
收藏Hugging Face2026-01-08 更新2026-01-09 收录
下载链接:
https://huggingface.co/datasets/HayatoHongoEveryonesAI/dev-TIR_v3
下载链接
链接失效反馈官方服务:
资源简介:
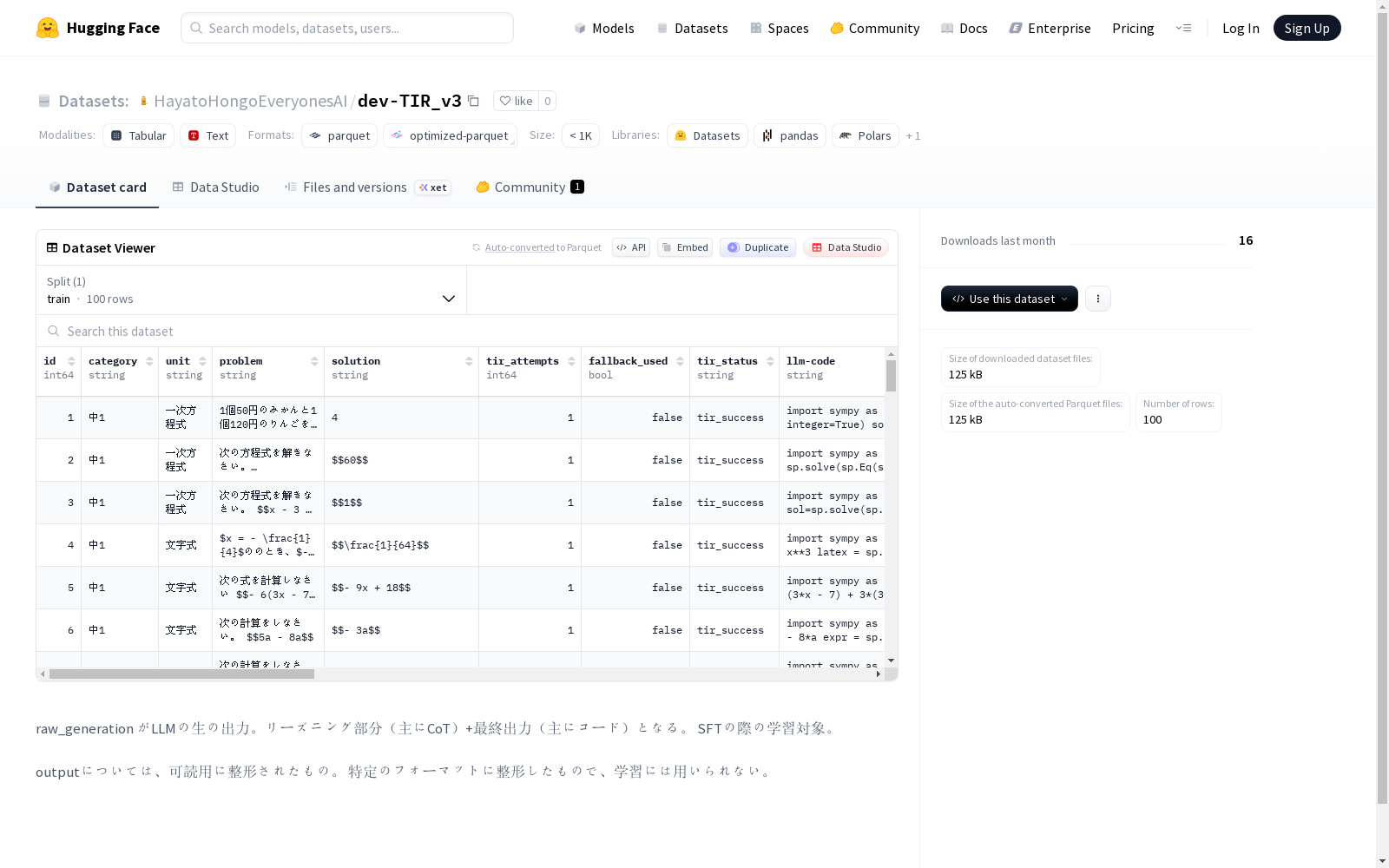
该数据集包含与问题解决任务相关的特征,包括问题陈述、解决方案以及关于解决方案尝试的各种元数据。数据集包含诸如'problem'(问题)、'solution'(解决方案)、'tir_attempts'(尝试次数)、'fallback_used'(是否使用备用方案)、'tir_status'(状态)、'llm-code'(LLM生成的代码)、'raw_generation'(LLM的原始输出,包括推理部分和最终代码)、'output'(格式化后的可读输出)、'execution_output'(执行输出)、'generated_solution'(生成的解决方案)和'expected_answer'(预期答案)等字段。'raw_generation'字段是SFT(监督微调)的学习目标,而'output'字段仅用于可读性展示,不用于训练。数据集包含一个'train'(训练)分割,共100个示例。
This dataset contains features related to problem-solving tasks, including problem statements, solutions, and various metadata regarding solution attempts. It includes fields such as "problem", "solution", "tir_attempts", "fallback_used", "tir_status", "llm-code", "raw_generation" (the raw output of the LLM, including reasoning parts and final code), "output" (formatted readable output), "execution_output", "generated_solution", and "expected_answer". The "raw_generation" field serves as the learning objective for Supervised Fine-Tuning (SFT), while the "output" field is only used for readability display and not applied for training. The dataset has a "train" split containing a total of 100 examples.
创建时间:
2026-01-07
原始信息汇总
数据集概述
基本信息
- 数据集名称: dev-TIR_v3
- 发布者/机构: HayatoHongoEveryonesAI
- 数据集地址: https://huggingface.co/datasets/HayatoHongoEveryonesAI/dev-TIR_v3
数据集结构与内容
数据字段(Features)
- id: 样本唯一标识(数据类型:int64)。
- category: 问题类别(数据类型:string)。
- unit: 所属单元(数据类型:string)。
- problem: 问题描述(数据类型:string)。
- solution: 解决方案(数据类型:string)。
- tir_attempts: TIR尝试次数(数据类型:int64)。
- fallback_used: 是否使用了后备方案(数据类型:bool)。
- tir_status: TIR状态(数据类型:string)。
- llm-code: 与LLM相关的代码(数据类型:string)。
- raw_generation: 语言模型的原始输出,包含推理过程(如思维链)和最终输出(如代码),用于监督微调学习(数据类型:string)。
- output: 经过格式化、便于人类阅读的输出,不用于模型训练(数据类型:string)。
- execution_output: 执行输出(数据类型:string)。
- generated_solution: 生成的解决方案(数据类型:string)。
- expected_answer: 期望答案(数据类型:string)。
数据划分(Splits)
- train(训练集):
- 样本数量:100
- 数据集大小:281,810 字节
- 下载大小:124,772 字节
配置信息
- 默认配置名称: default
- 数据文件路径:
data/train-*
搜集汇总
数据集介绍
构建方式
在人工智能与编程教育交叉领域,dev-TIR_v3数据集通过系统化流程构建而成。其核心方法涉及从多样化编程问题中收集原始数据,并利用大型语言模型生成推理过程与代码解决方案。每个样本均经过结构化标注,包含问题描述、模型原始输出、格式化解答以及执行结果等多维度信息,确保了数据在训练与评估中的一致性与可追溯性。
特点
该数据集展现出多维度特征,其结构涵盖问题类别、解题单元、模型尝试次数及回退机制使用状态等丰富元数据。特别值得注意的是,数据集明确区分了大型语言模型的原始生成内容与经过人工整理的可读格式输出,这为研究模型推理过程与最终代码生成间的关联提供了细致观察窗口。此外,执行输出与预期答案的并存,使得对模型性能的定量评估成为可能。
使用方法
针对模型训练与评估,dev-TIR_v3数据集提供了清晰的使用路径。在监督微调场景中,研究者可将模型的原始生成作为直接学习目标,以优化其分步推理与代码生成能力。同时,经过格式化的输出与执行结果可作为验证集,用于评估模型解决方案的正确性与鲁棒性。该设计支持端到端的训练-评估循环,适用于编程问题求解领域的模型能力迭代与基准测试。
背景与挑战
背景概述
dev-TIR_v3数据集聚焦于代码生成与推理评估领域,其构建旨在系统化探索大型语言模型在解决编程问题时的思维链推理能力。该数据集由研究团队精心设计,核心研究问题涉及模型在生成代码解决方案过程中的内部推理机制及其与最终输出的关联性。通过记录模型的多轮尝试、回退策略及执行状态,它为深入理解模型在复杂任务中的决策逻辑提供了实证基础,对推动可解释人工智能及代码智能的发展具有显著影响力。
当前挑战
该数据集首要挑战在于解决代码生成领域中模型推理过程的可追溯性与可靠性问题,传统方法往往仅关注最终输出,而忽视了中间推理步骤的透明性。构建过程中的挑战包括如何有效捕获并结构化模型的生成长文本输出,区分推理部分与代码部分,并确保执行结果与预期答案的精准对齐,同时需处理多轮尝试数据的完整性及回退机制的标注一致性,这些都对数据收集与清洗流程提出了较高要求。
常用场景
经典使用场景
在代码生成与程序推理领域,dev-TIR_v3数据集为大型语言模型(LLM)的思维链(CoT)推理能力评估提供了标准化基准。该数据集通过记录模型在解决编程问题时的完整生成过程,包括中间推理步骤与最终代码输出,使得研究者能够深入分析模型在复杂逻辑任务中的表现。经典使用场景集中于模型微调(SFT)与推理策略优化,通过对比raw_generation中的原始输出与expected_answer,系统评估模型代码生成准确性及错误模式。
解决学术问题
该数据集有效解决了程序合成研究中模型推理过程黑箱化、错误归因困难等核心问题。通过结构化记录tir_attempts、fallback_used等关键指标,支持对模型迭代调试行为的量化分析,为理解LLM在代码生成中的失败机制提供了实证基础。其意义在于建立了可复现的评估框架,推动了对模型推理鲁棒性、多步问题分解能力等前沿课题的深入研究,显著提升了代码生成领域的评估方法论水平。
衍生相关工作
基于该数据集衍生的经典工作主要集中在代码生成模型的迭代优化范式研究。例如,利用tir_status字段开发动态推理轨迹监控方法,提升模型在多次尝试中的自我修正能力。相关研究还拓展至跨语言代码迁移、程序语义等价性验证等方向,通过结合category与unit的元信息,构建了面向特定编程领域的细粒度评估子集,进一步推动了程序合成与软件工程领域的交叉创新。
以上内容由遇见数据集搜集并总结生成


