HiFiTTS-2
收藏arXiv2025-06-05 更新2025-06-06 收录
下载链接:
https://huggingface.co/datasets/nvidia/hifitts-2
下载链接
链接失效反馈官方服务:
资源简介:
HiFiTTS-2是一个大规模的语音数据集,用于高带宽语音合成。该数据集源于LibriVox有声读物,包含约36.7k小时的英语语音用于22.05 kHz的训练,以及31.7k小时用于44.1 kHz的训练。数据集还包括详细的语句和有声读物元数据,以便研究人员根据不同的用例对数据集进行质量筛选。实验结果表明,我们的数据管道和生成的数据集可以促进高质量、零样本文本到语音(TTS)模型在高带宽下的训练。该数据集适用于语音合成和语音克隆等应用,并为研究高带宽和混合带宽建模提供了新的数据资源。
HiFiTTS-2 is a large-scale speech dataset dedicated to high-bandwidth speech synthesis. Derived from LibriVox audiobooks, this dataset contains approximately 36.7k hours of English speech for training at 22.05 kHz, and 31.7k hours for training at 44.1 kHz. It also includes detailed utterance and audiobook metadata, enabling researchers to perform quality filtering on the dataset according to different use cases. Experimental results demonstrate that our data pipeline and the generated dataset can facilitate the training of high-quality zero-shot text-to-speech (TTS) models for high-bandwidth scenarios. This dataset is suitable for applications such as speech synthesis and voice cloning, and provides a new data resource for research on high-bandwidth and mixed-bandwidth modeling.
提供机构:
英伟达公司
创建时间:
2025-06-05
原始信息汇总
HiFiTTS-2 数据集概述
数据集基本信息
- 名称: HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset
- 所有者: NVIDIA Corporation
- 创建日期: June 2025
- 许可证: Creative Commons Attribution 4.0 International License (CC BY 4.0)
- 论文链接: https://arxiv.org/abs/2506.04152
数据集内容
- 来源: LibriVox 有声读物
- 音频时长: 约 36.7k 小时
- 说话人数量: 5k
- 采样率: 48 kHz(原始下载)
- 配置:
- 22kHz: 适用于 22 kHz 训练的基数据集
- 44kHz: 预计算子集,31.7k 小时,适用于 44 kHz 训练
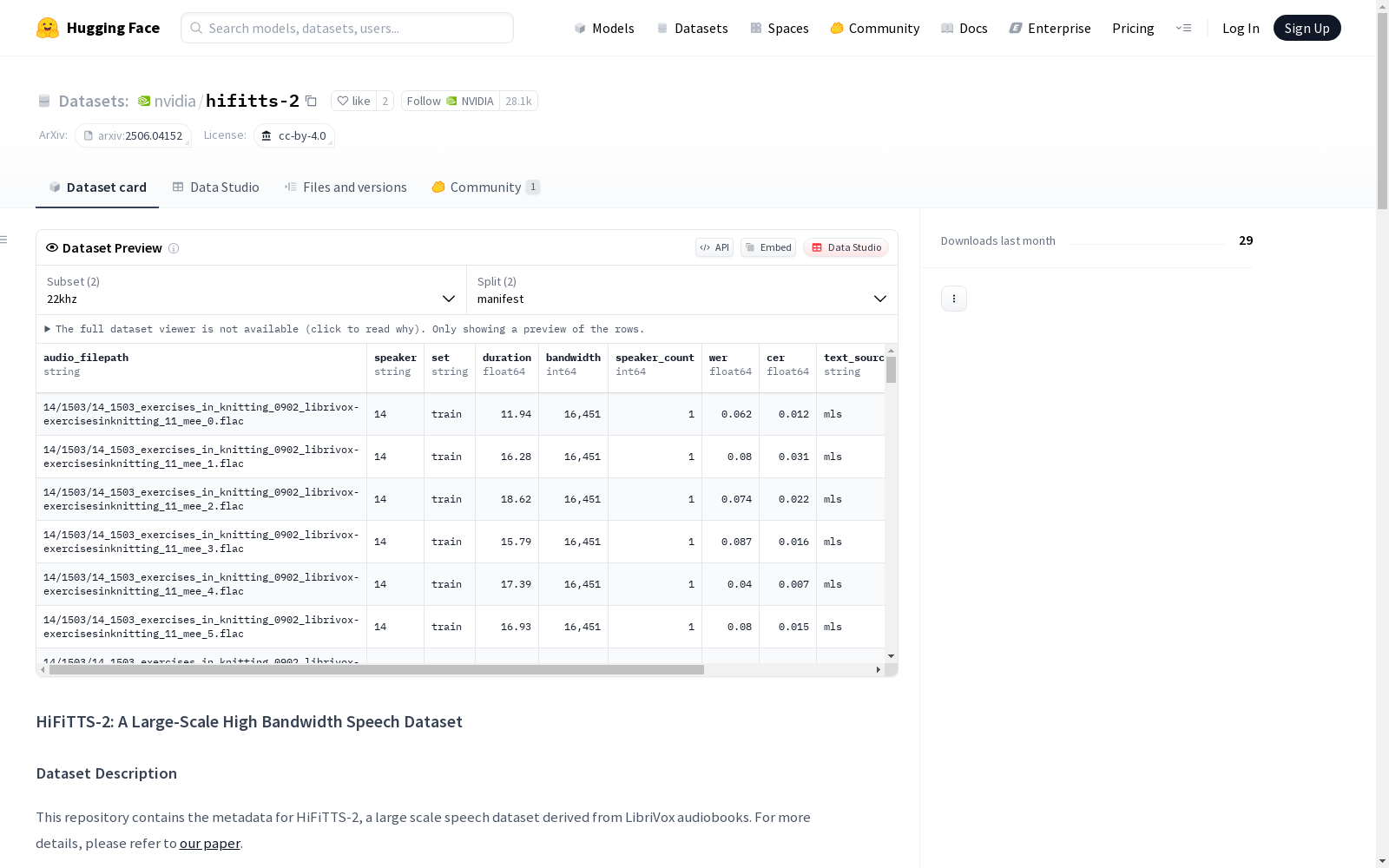
数据集格式
- 字段:
- utterance level manifest:
- audio_filepath, speaker, set, duration, bandwidth, speaker_count, wer, cer, text_source, text, normalized_text
- audiobook chapter level manifest:
- url, chapter_filepath, bandwidth, utterances (包含 audio_filepath, offset, duration)
- utterance level manifest:
下载说明
- 下载元数据文件: 从 Hugging Face 仓库下载 manifest.json 和 chapter.json 文件。
- 安装工具: 安装 NeMo-speech-data-processor (SDP)。
- 运行下载脚本: bash python /home/NeMo-speech-data-processor/main.py --config-path="/home/NeMo-speech-data-processor/dataset_configs/english/hifitts2" --config-name="config_22khz.yaml" workspace_dir="/home/hifitts2" max_workers=8
- 磁盘空间需求:
- 22 kHz 版本: 约 3TB
- 44 kHz 版本: 约 5TB
引用
bibtex @inproceedings{rlangman2025hifitts2, title={HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset}, author={Ryan Langman and Xuesong Yang and Paarth Neekhara and Shehzeen Hussain and Edresson Casanova and Evelina Bakhturina and Jason Li}, booktitle={Interspeech}, year={2025}, }
搜集汇总
数据集介绍
构建方式
HiFiTTS-2数据集的构建基于LibriVox有声读物的原始音频资源,通过一系列严谨的数据处理流程实现。首先,从LibriVox下载48 kHz的原始音频文件,并降采样至44.1 kHz,同时转换为FLAC格式以保持音频质量。随后,采用能量基础的静音修剪技术,确保每段语音前后最多保留0.5秒的静音。带宽估计环节利用功率谱分析,筛选出高频带丰富的语音数据,22.05 kHz子集要求带宽不低于11 kHz,而44.1 kHz子集则要求带宽超过13 kHz。此外,通过文本预处理恢复标点符号和大小写,并结合语音对齐技术优化语音分段,最终形成包含多维度元数据的高质量语音数据集。
特点
HiFiTTS-2数据集以其大规模和高带宽特性脱颖而出,包含两个子集:22.05 kHz子集涵盖36.7千小时的语音数据,涉及5,013名说话人;44.1 kHz子集则提供31.7千小时的高带宽语音,覆盖4,631名说话人。数据集不仅提供原始语音和文本转录,还包含详尽的元数据,如带宽估计、说话人数量标注以及语音质量指标(WER/CER),支持研究者根据需求灵活筛选数据。其独特的全带宽设计填补了高分辨率语音合成数据的空白,尤其适合零样本语音合成和带宽扩展等前沿研究。
使用方法
该数据集专为高带宽语音合成任务设计,用户可通过Hugging Face平台直接访问。使用前建议结合提供的元数据(如带宽标签、说话人ID)进行数据筛选,以适应不同应用场景。对于语音合成模型训练,推荐优先采用44.1 kHz子集以获取更丰富的频谱信息;若需平衡数据规模与计算成本,22.05 kHz子集是理想选择。实验表明,结合分类器无关引导(CFG)技术时,模型在未见说话人上的表现显著提升。此外,数据集的细分开发集和测试集(含可见/未见说话人划分)为模型评估提供了标准化基准。
背景与挑战
背景概述
HiFiTTS-2是由NVIDIA的研究团队于2025年推出的一个大规模高带宽语音数据集,旨在推动高质量语音合成技术的发展。该数据集基于LibriVox的有声读物,包含约36.7千小时的22.05 kHz语音数据和31.7千小时的44.1 kHz语音数据,涵盖了数千名说话人。HiFiTTS-2的推出填补了高带宽语音合成领域的数据空白,为零样本文本到语音(TTS)模型的训练提供了重要支持。其数据处理流程包括带宽估计、分段、文本预处理和多说话人检测等步骤,确保了数据的高质量和多样性。该数据集的发布为语音合成研究提供了新的基准,并在高带宽语音生成任务中展现了显著优势。
当前挑战
HiFiTTS-2在解决高带宽语音合成问题时面临多重挑战。首先,领域问题的挑战在于现有数据集多为低带宽(如16 kHz)音频,难以满足高带宽语音合成的需求,而混合带宽音频会导致模型性能下降。其次,数据构建过程中的挑战包括:1) 音频带宽的准确估计与筛选,需确保数据的高带宽特性;2) 文本转录的标点与大小写恢复,这对语音合成的自然性至关重要;3) 多说话人检测与数据清洗,以确保说话人标签的可靠性;4) 法律与版权问题,需确保数据来源的合法性与商业可用性。这些挑战通过先进的数据处理流程得以解决,但高带宽语音数据的稀缺性仍是未来研究的重要方向。
常用场景
经典使用场景
HiFiTTS-2数据集在语音合成领域具有广泛的应用价值,特别是在高带宽语音合成方面。该数据集通过提供22.05 kHz和44.1 kHz的高质量语音数据,为研究人员训练零样本文本到语音(TTS)模型提供了强有力的支持。其经典使用场景包括训练和评估高保真语音合成模型,尤其是在需要模拟未见过的说话人声音时,数据集中的多说话人数据和高带宽特性使其成为理想的选择。
实际应用
在实际应用中,HiFiTTS-2数据集被广泛用于开发高质量的语音合成系统,如虚拟助手、有声读物和语音克隆技术。其高带宽特性使得生成的语音更加自然和清晰,适用于对音质要求较高的场景。此外,数据集的商业友好许可使其能够无障碍地应用于各类商业产品中,进一步推动了语音技术的产业化进程。
衍生相关工作
HiFiTTS-2数据集的发布催生了一系列相关研究,特别是在高带宽语音合成和零样本TTS领域。例如,基于该数据集的Koel-TTS模型展示了在高带宽语音合成中的卓越性能。此外,数据集还被用于探索混合带宽音频的建模和带宽扩展技术,推动了语音处理技术的多样化发展。这些衍生工作不仅验证了数据集的实用性,也为未来研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


